Day: May 29, 2024
-
How Researchers Cracked an 11-Year-Old Password to a $3 Million Crypto Wallet
Two years ago when “Michael,” an owner of cryptocurrency, contacted Joe Grand to help recover access to about $2 million worth of bitcoin he stored in encrypted format on his computer, Grand turned him down. Michael, who is based in Europe and asked to remain anonymous, stored the cryptocurrency in a password-protected digital wallet. He…
Written by
-
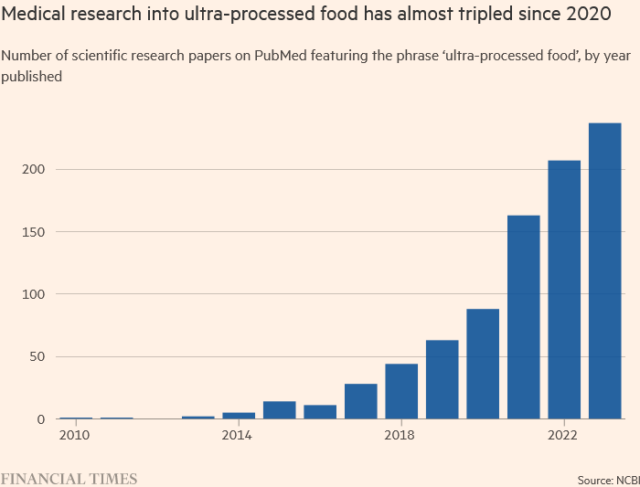
“Deny, denounce, delay”: ultra-processed food companies fighting using big tobacco type tactics
When the Brazilian nutritional scientist Carlos Monteiro coined the term “ultra-processed foods” 15 years ago, he established what he calls a “new paradigm” for assessing the impact of diet on health. Monteiro had noticed that although Brazilian households were spending less on sugar and oil, obesity rates were going up. The paradox could be explained…
Written by

-
2.8M US folks’ personal info swiped in Sav-Rx IT heist – 8 months ago
Sav-Rx has started notifying about 2.8 million people that their personal information was likely stolen during an IT intrusion that happened more than seven months ago. The biz provides prescription drug management services to more than 10 million US workers and their families, via their employers or unions. It first spotted the network “interruption” on…
Written by
-
Google’s technical info about search ranking leaks online
A trove of documents that appear to describe how Google ranks search results has appeared online, likely as the result of accidental publication by an in-house bot. The leaked documentation describes an old version of Google’s Content Warehouse API and provides a glimpse of Google Search’s inner workings. The material appears to have been inadvertently…
Written by

-
Lawyers To Plastic Makers: Prepare For ‘Astronomical’ PFAS Lawsuits
An anonymous reader quotes a report from the New York Times: The defense lawyer minced no words as he addressed a room full of plastic-industry executives. Prepare for a wave of lawsuits with potentially “astronomical” costs. Speaking at a conference earlier this year, the lawyer, Brian Gross, said the coming litigation could “dwarf anything related…
Written by
-
YouTube’s Crackdown on Adblockers Makes Videos Unwatchable – now skips to end of video
YouTube has been at war with adblockers for quite some time now and has employed various tactics to keep users off those extensions. Its most recent defense strategy is to skip right to the end of the video you’re playing. If you try replaying it, it’ll do that again. If you tap anywhere on the…
Written by