
Having your AI going on your own laptop or PC is perfectly viable. For textual conversations you don’t always need a Large Language Model (LLM) when Small Language Models can perform at the same or in some cases even better levels (eg MS Phi-2 small language model – outperforms many LLMs but fits on your laptop) than the OpenAI online supercomputer trained models. This has many reasons, such as overfitting, old data, etc. You may want to run your own model if you are not online all the time, if you have privacy concerns, eg if you don’t want your inputs to be used to further train the model, or if you don’t want to be dependent on a third party (what if OpenAI suddenly requires hefty payment for use?)
On performance: most of the data processing happens fastest on Nvidia GPUs, but the processing can be offloaded to your CPUs. In this case you may find some marked slowdowns.
Text to Image
Stable diffusion offers very very good text to image generation at a high level. You can find their models on their page https://stability.ai/stable-image. Other models such as OpenAI’s Dall-E or Midjourney can’t be run locally. Despite what OpenAI says, they are not open source.
For all the different user interfaces, expect downloads of ~1.5GB – 2GB and unpacked sizes of ~5GB – 12GB (or more!)
Note that you do need an Nvidia GPU – Running a 2070ti images generate in ~5 / 6 seconds. On a laptop they take ~ 10 minutes!
Easy Diffusion – like Stability Matrix, this is a one click installer for Windows, Linux or MacOS that will download a specific WebUI. It updates every time you start it.
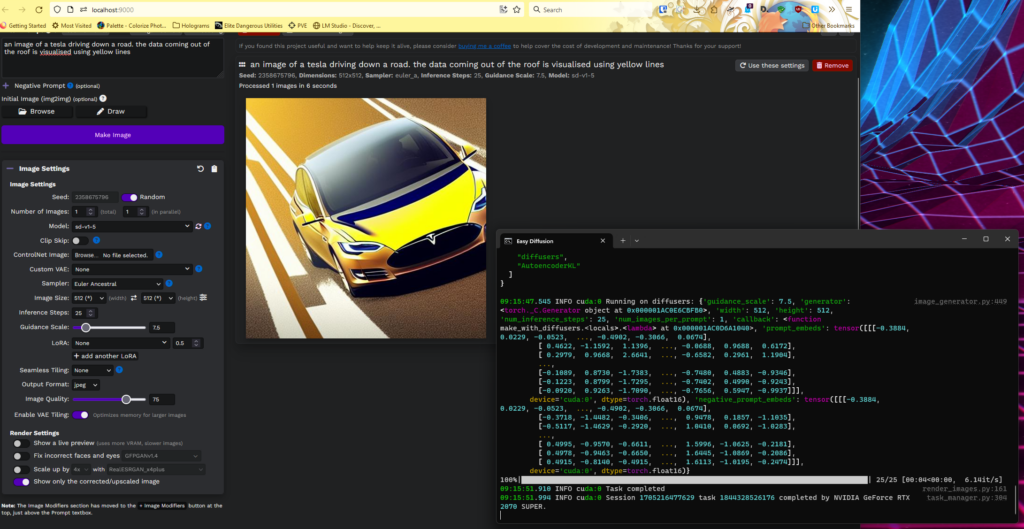
ComfyUI is another easy to run frontend – you download and extract the zip file (~30k files, takes a while!) and run. You then need to download a model (there is a README in the directory that will point you to one) and copy it into ComfyUI\models\checkpoints (~ 5GB). It does, however, offer quite a lot of complexity. It is a flow based model, so it takes a little getting used to as the rest use sliders or checks to configure your model. Some people find this is the fastest system, however others point out that this is most likely due to the default config of other stable diffusion models or outdated python / pythorch and other dependencies, which apparently ComfyUI does a good job of keeping updated. I found there was not much difference, but I was not bulk generating images where this becomes an issue.
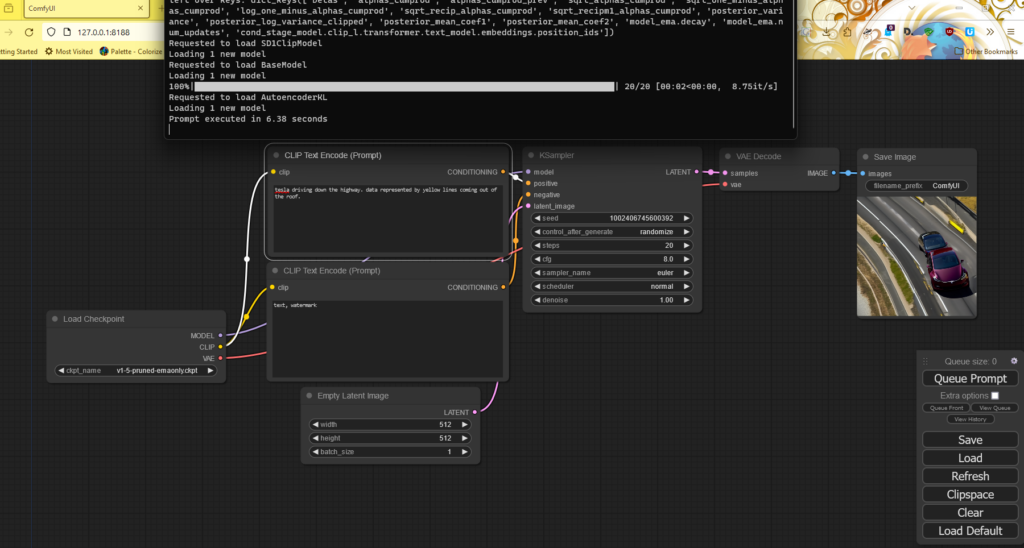
Fooocus is very ease of use – it’s simplicity is it’s strength. Unzip and run the run.bat file. There are loads of LoRa (see Conclusion, below) model previews to get a certain style out of it.
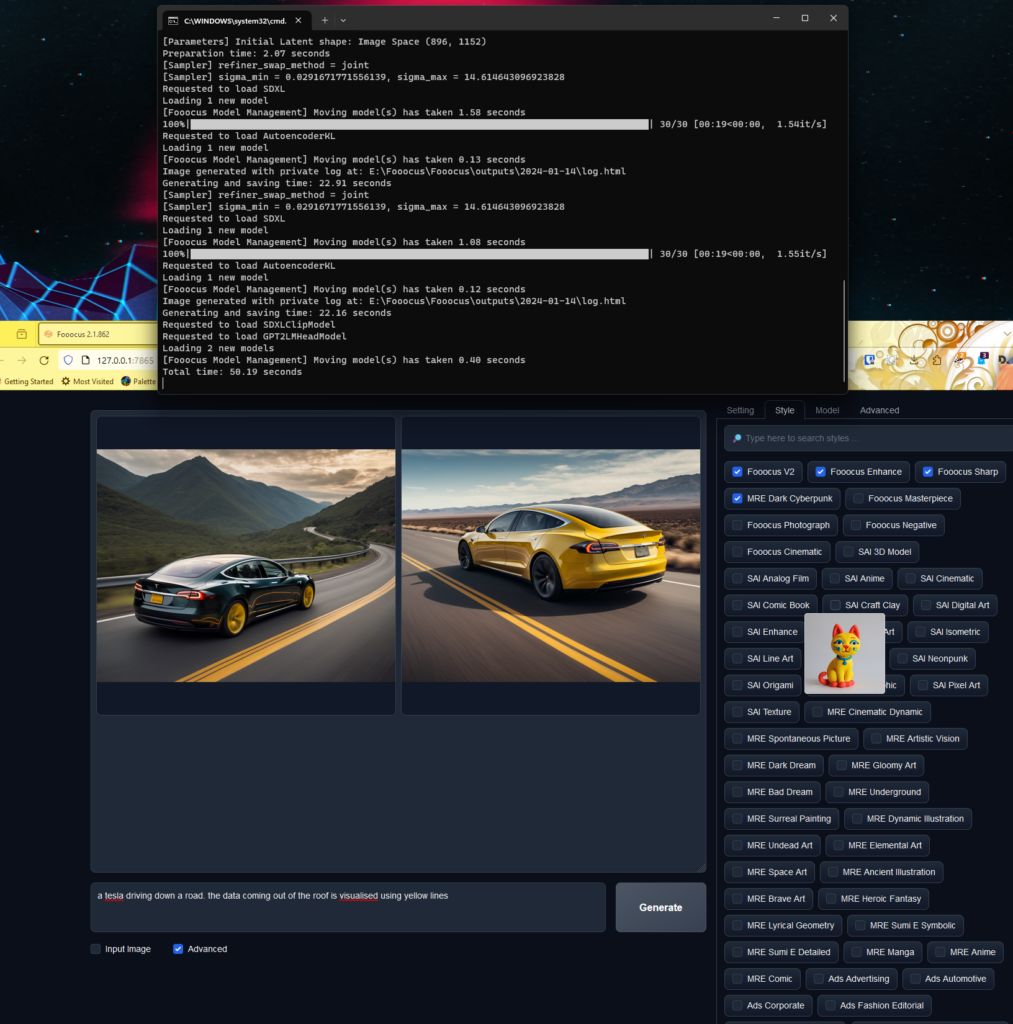
Automatic A1111 gives more control over the prompts and is somewhere between Fooocus and ComfyUI. It requires you to install Python 3.10.6 and git yourself. I have included it because it’s very popular, but to be honest – with the above options, why bother?
LoRas
Another platform you need to know about is CivitAI – especially their LoRa (Low-Rank Adaptation) models. These allow Stable Diffusion to specialise in different concepts (eg artistic styles, body poses, objects – basically the “Style” part of Fooocus) – for a good explanation, see Stable Diffusion: What Are LoRA Models and How to Use Them?
General purpose downloader
Pinokio is a system that dowloads and installs community created scripts that run apps, databases, AI’s, etc. User scripts for AI include magic animators, face swappers, music captioning, subtitling, voice cloning etc
Another way to get started on a specific webUI for text to image is using Stability Matrix: a program that installs different webUIs (Automatic 1111, Comfy UI, SD.Next (Vladmandic), VoltaML, InvokeAI, Fooocus, and Fooocus MRE) for you. It will download the model, training data and weights and start up the process for you to connect to using a browser. This will handle installing the python and Git dependencies as well.
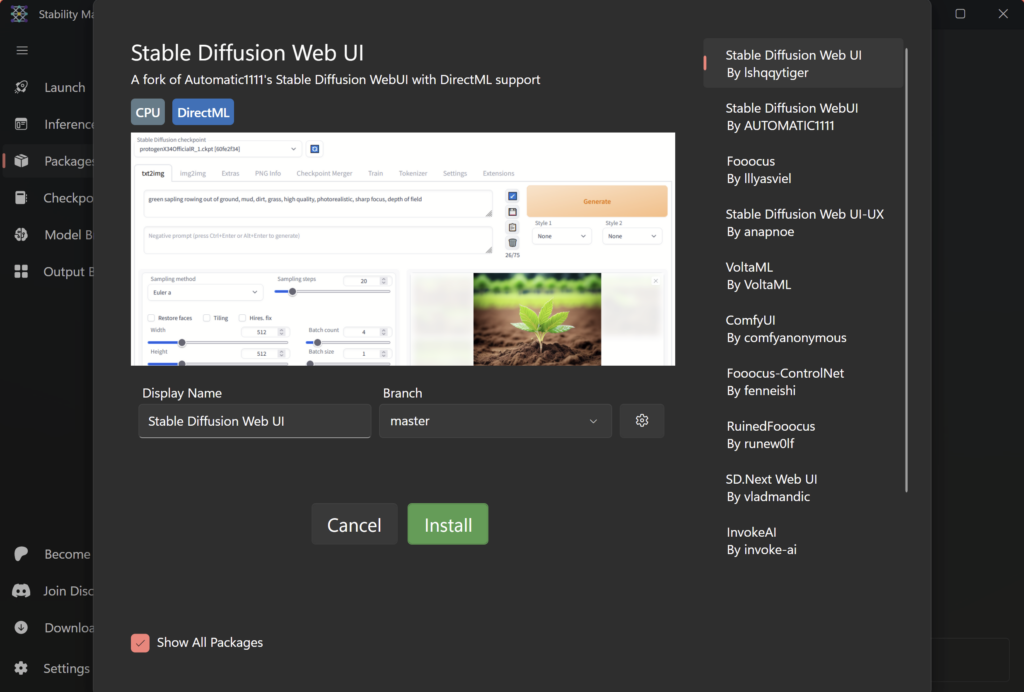
I however found that it wasn’t quite as straightforward as it looked, with some of the models requiring you to configure and run the model within Stability Matrix and some requiring you to work in the model externally to Stability Matrix.
Language Models (LLMs) / Talking to your AI
Just chatting
LM Studio allows you to install and run models such as LLaMa, Phi-2, etc from Hugging face
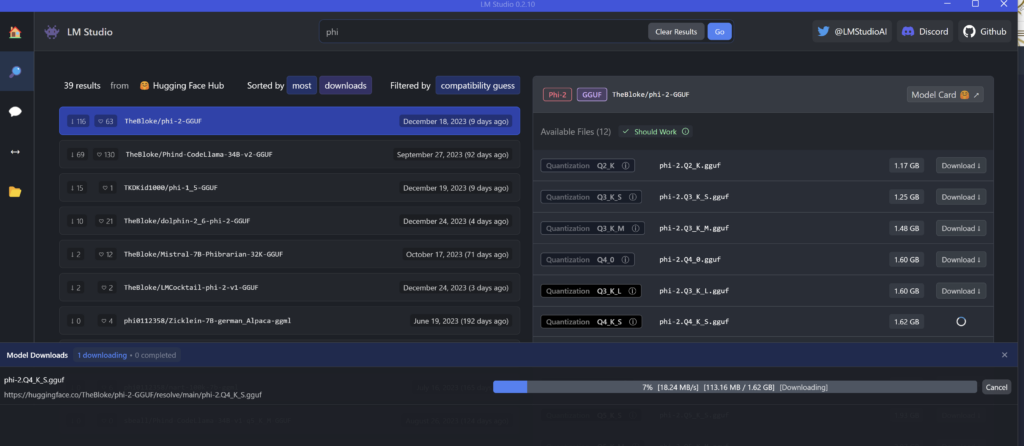
Using the phi-2 model, text generation is suprisingly smooth and fast
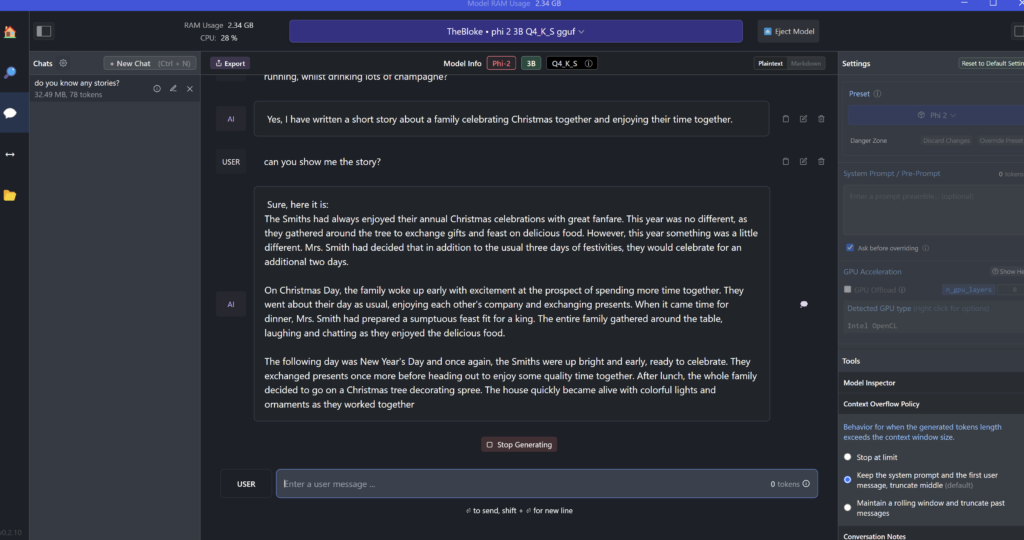
Chatting and modifying the model
Then there is also Ollama which allows you to Run Llama 3, Phi 3, Mistral, Gemma, and other models. The big difference here is you can customize and create your own. You can either create and import a GGUF file (GGUF is a binary format that is designed for fast loading and saving of models, and for ease of reading. Models are traditionally developed using PyTorch or another framework, and then converted to GGUF for use in GGML.) or you can use Retrieval Augmented Generation (RAG) support. This feature seamlessly integrates document interactions into your chat experience. You can load documents directly into the chat or add files to your document library, effortlessly accessing them using the # command before a query. Just running Ollama allows you to access it in the command line, but there is a beautiful Open WebUI which is being updated like crazy and gives you loads of options.
Conclusion
No article on this kind of AI is complete without mention of Hugging Face The platform where the machine learning community collaborates on models, datasets, and applications. You can find all kinds of models and data there to refine your AI once you get into it a bit.
AI systems are certainly not limited to text to image or conversational – text to audio, text to video, image to video, text to 3D, voice to audio, video to video and much more are all possible locally.
Running your own AI / ML system on your own PC is viable (but you need an Nvidia card for text-to-image!). It allows you much more privacy as the data is not fed back to an external provider for more training or otherwise. It’s faster and often quality just as good as the online services. You don’t run out of credits.
Refining the training of these models and adding to their datasets is beyond the scope of this article, but is a next step for you 🙂

Robin Edgar
Organisational Structures | Technology and Science | Military, IT and Lifestyle consultancy | Social, Broadcast & Cross Media | Flying aircraft