[…]
On Tuesday, the company unveiled GPT-4, an update to its advanced AI system that’s meant to generate natural-sounding language in response to user input. The company claimed GPT-4 is more accurate and more capable of solving problems. It even inferred that ChatGPT performs better than most humans can on complicated tests. OpenAI said GPT-4 scores in the 90th percentile of the Uniform Bar Exam and the 99th percentile of the Biology Olympiad. GPT-3, the company’s previous version, scored 10th and 31st on those tests, respectively.
The new system is now capable of handling over 25,000 words of text, according to the company. GPT-3 was only capable of handling 2,048 linguistic tokens, or 1,500 words at a time. This should allow for “more long-from content creation.” That’s not to say some folks haven’t tried writing entire novels with earlier versions of the LLM, but this new version could allow text to remain much more cohesive.
Those who have been hanging on OpenAI’s every word have been long anticipating the release of GPT-4, the latest edition of the company’s large language model. OpenAI said it spent six months modifying its LLM to make it 82% less likely to respond to requests for “disallowed content” and 40% more likely to produce factual responses than previous versions. Of course, we don’t have access to OpenAI’s internal data that might show how often GPT-3 was liable to lie or showcase banned content. Few people outside OpenAI have been able to take the new system on a test run, so all these claims could very well just be mere puffery.
Folks looking to get access to GPT-4 either has to be one of the select few companies given early access, or join a waitlist for the GPT-4 API or be one of the lucky few selected ChatGPT Plus subscribers.
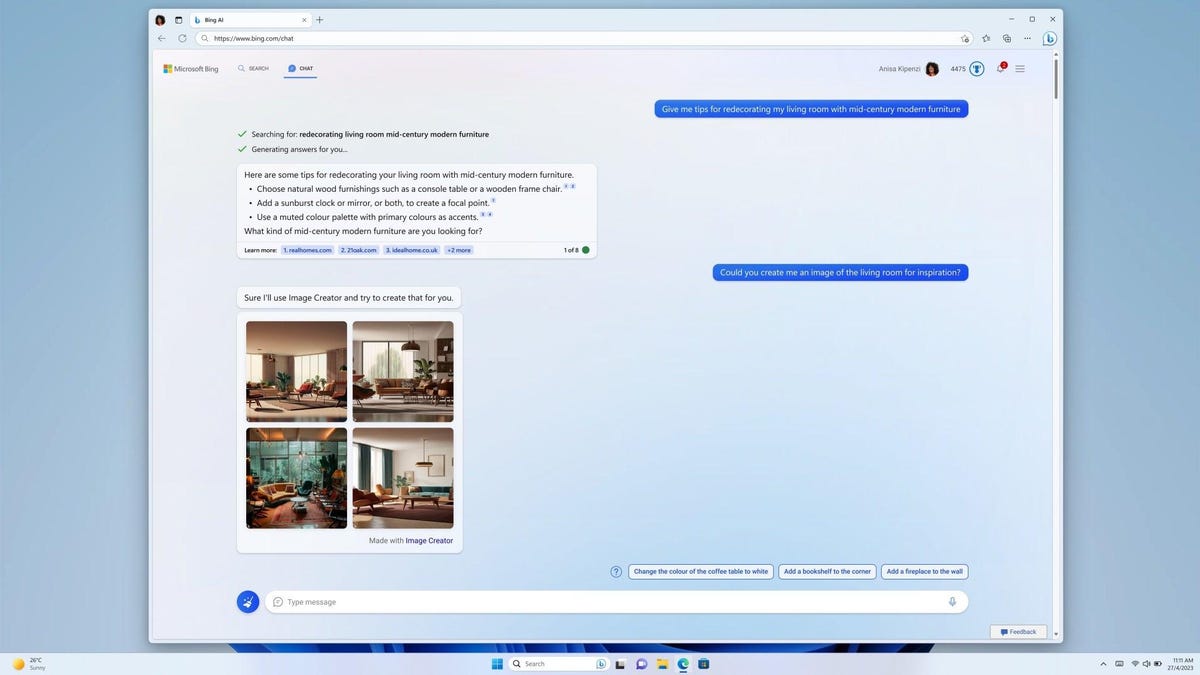
The new system also includes the ability to accept images as inputs, allowing the system to generate captions, or provide analyses of an image. The company used the example of an image with a few ingredients, and the system provided some examples for what food those ingredients could create. OpenAI CEO Sam Altman wrote on Twitter that the company was “previewing” its visual inputs but it will “need some time to mitigate the safety challenges.”
What else is GPT-4 good at?
In a Tuesday livestream, OpenAI showed off a few capabilities of GPT-4, though the company constantly had to remind folks to not explicitly trust everything the AI produces.
In the livestream, OpenAI President Greg Brockman showed how the system can complete relatively inane tasks, like summarizing an article in one sentence where every word starts with the same letter. He then showed how users can instill the system with new information for it to parse, adding parameters to make the AI more aware of its role.
The company co-founder said the system is relatively slow, especially when completing complex tasks, though it wouldn’t take more than a few minutes to finish up requests. In one instance, Brockman made the AI create code for an AI-based Discord bot. He constantly iterated on the requests, even inputting error messages into GPT-4 until it managed to craft what was asked. He also put in U.S. tax code to finalize some tax info for an imaginary couple.
All the while, Brockman kept reiterating that people should not “run untrusted code from humans or AI,” and that people shouldn’t implicitly trust the AI to do their taxes. Of course, that won’t stop people from doing exactly that, depending on how capable public models of this AI end up being. It relates to the very real risk of running these AI models in professional settings, even when there’s only a small chance of AI error.
“It’s not perfect, but neither are you,” Brockman said.
OpenAI is getting even more companies hooked on AI
OpenAI has apparently leveraged its recently-announced multi-billion dollar arrangement with Microsoft to train GPT-4 on Microsoft Azure supercomputers. Altman said this latest version of the company’s LLM is “more creative than previous models, it hallucinates significantly less, and it is less biased.” Still, he said the company was inviting more outside groups to evaluate GPT-4 and offer feedback.
Of course, that’s not to say the system isn’t already been put into use by several companies. Language learning app Duolingo announced Tuesday afternoon that it was implementing a “Duolingo Max” premium subscription tier. The app has new features powered by GPT-4 that lets AI offer “context-specific explanations” for why users made a mistake. It also lets users practice conversations with the AI chatbot, meaning that damn annoying owl can now react to your language flubs in real time.
Because that’s what this is really about, getting more companies to pay to access OpenAI’s APIs. Altman mentioned the new system will have even more customization of behavior, which will further allow developers to fine-tune AI for specific purposes. Other customers of GPT-4 include the likes of Morgan Stanley, Khan Academy, and the Icelandic government. The U.S. Chamber of Commerce recently said in 10 years, virtually every company and government entity will be up on this AI tech.
Though the company still said GPT-4 has “many known limitations” including social biases, hallucinations, and adversarial prompts. Even if the new system is better than before, there’s still plenty of room for the AI to be abused. Some ChatGPT users have flooded open submission sections for at least one popular fiction magazine. Now that GPT-4 can write even longer, It’s likely we’ll see even more long-form AI-generated content flooding the internet.
OpenAI was supposed to be all about open source and stuff, but with this definitely being about increasing (paid) API access, it’s looking more and more like a massive money grab. Not really surprising but a real shame.