Facebook AI has built and open-sourced Blender, the largest-ever open-domain chatbot. It outperforms others in terms of engagement and also feels more human, according to human evaluators.
The culmination of years of research in conversational AI, this is the first chatbot to blend a diverse set of conversational skills — including empathy, knowledge, and personality — together in one system.
We achieved this milestone through a new chatbot recipe that includes improved decoding techniques, novel blending of skills, and a model with 9.4 billion parameters, which is 3.6x more than the largest existing system.
Today we’re releasing the complete model, code, and evaluation set-up, so that other AI researchers will be able to reproduce this work and continue to advance conversational AI research.
[…]
As the culmination of years of our research, we’re announcing that we’ve built and open-sourced Blender, the largest-ever open-domain chatbot. It outperforms others in terms of engagement and also feels more human, according to human evaluators. This is the first time a chatbot has learned to blend several conversational skills — including the ability to assume a persona, discuss nearly any topic, and show empathy — in natural, 14-turn conversation flows. Today we’re sharing new details of the key ingredients that we used to create our new chatbot.
Some of the best current systems have made progress by training high-capacity neural models with millions or billions of parameters using huge text corpora sourced from the web. Our new recipe incorporates not just large-scale neural models, with up to 9.4 billion parameters — or 3.6x more than the largest existing system — but also equally important techniques for blending skills and detailed generation.
[…]
We’re currently exploring ways to further improve the conversational quality of our models in longer conversations with new architectures and different loss functions. We’re also focused on building stronger classifiers to filter out harmful language in dialogues. And we’ve seen preliminary success in studies to help mitigate gender bias in chatbots.
True progress in the field depends on reproducibility — the opportunity to build upon the best technology possible. We believe that releasing models is essential to enable full, reliable insights into their capabilities. That’s why we’ve made our state of the art open-domain chatbot publicly available through our dialogue research platform ParlAI. By open-sourcing code for fine-tuning and conducting automatic and human evaluations, we hope that the AI research community can build on this work and collectively push conversational AI forward.
Existing rules for deploying AI in clinical settings, such as the standards for FDA clearance in the US or a CE mark in Europe, focus primarily on accuracy. There are no explicit requirements that an AI must improve the outcome for patients, largely because such trials have not yet run. But that needs to change, says Emma Beede, a UX researcher at Google Health: “We have to understand how AI tools are going to work for people in context—especially in health care—before they’re widely deployed.”
[…]
Google’s first opportunity to test the tool in a real setting came from Thailand. The country’s ministry of health has set an annual goal to screen 60% of people with diabetes for diabetic retinopathy, which can cause blindness if not caught early. But with around 4.5 million patients to only 200 retinal specialists—roughly double the ratio in the US—clinics are struggling to meet the target. Google has CE mark clearance, which covers Thailand, but it is still waiting for FDA approval. So to see if AI could help, Beede and her colleagues outfitted 11 clinics across the country with a deep-learning system trained to spot signs of eye disease in patients with diabetes.
In the system Thailand had been using, nurses take photos of patients’ eyes during check-ups and send them off to be looked at by a specialist elsewhere—a process that can take up to 10 weeks. The AI developed by Google Health can identify signs of diabetic retinopathy from an eye scan with more than 90% accuracy—which the team calls “human specialist level”—and, in principle, give a result in less than 10 minutes. The system analyzes images for telltale indicators of the condition, such as blocked or leaking blood vessels.
Sounds impressive. But an accuracy assessment from a lab goes only so far. It says nothing of how the AI will perform in the chaos of a real-world environment, and this is what the Google Health team wanted to find out. Over several months they observed nurses conducting eye scans and interviewed them about their experiences using the new system. The feedback wasn’t entirely positive.
When it worked well, the AI did speed things up. But it sometimes failed to give a result at all. Like most image recognition systems, the deep-learning model had been trained on high-quality scans; to ensure accuracy, it was designed to reject images that fell below a certain threshold of quality. With nurses scanning dozens of patients an hour and often taking the photos in poor lighting conditions, more than a fifth of the images were rejected.
Patients whose images were kicked out of the system were told they would have to visit a specialist at another clinic on another day. If they found it hard to take time off work or did not have a car, this was obviously inconvenient. Nurses felt frustrated, especially when they believed the rejected scans showed no signs of disease and the follow-up appointments were unnecessary. They sometimes wasted time trying to retake or edit an image that the AI had rejected.
Because the system had to upload images to the cloud for processing, poor internet connections in several clinics also caused delays. “Patients like the instant results, but the internet is slow and patients then complain,” said one nurse. “They’ve been waiting here since 6 a.m., and for the first two hours we could only screen 10 patients.”
The Google Health team is now working with local medical staff to design new workflows. For example, nurses could be trained to use their own judgment in borderline cases. The model itself could also be tweaked to handle imperfect images better.
Of course the anti ML people are using this as some sort of AI will never work kind of way, but as far as I can see these kinds of tests are necessary and seemed to have been performed with oversight, meaning there was no real risk to patients involved. Lessons were learned and will be implemented, as with all new technologies. And going public with the lessons is incredibly useful for everyone in the field.
Google Translate today launched Transcribe for Android, a feature that delivers a continual, real-time translation of a conversation. Transcribe will begin by rolling out support for eight languages in the coming days: English, French, German, Hindi, Portuguese, Russian, Spanish and Thai. With Transcribe, Translate is now capable of translating classroom or conference lectures with no time limits, whereas before speech-to-text AI in Translate lasted no longer than a word, phrase, or sentence. Google plans to bring Transcribe to iOS devices at an unspecified date in the future.
TensorFlow Quantum (TFQ) is a quantum machine learning library for rapid prototyping of hybrid quantum-classical ML models. Research in quantum algorithms and applications can leverage Google’s quantum computing frameworks, all from within TensorFlow.
TensorFlow Quantum focuses on quantum data and building hybrid quantum-classical models. It integrates quantum computing algorithms and logic designed in Cirq, and provides quantum computing primitives compatible with existing TensorFlow APIs, along with high-performance quantum circuit simulators. Read more in the TensorFlow Quantum white paper.
The state of Utah has given an artificial intelligence company real-time access to state traffic cameras, CCTV and “public safety” cameras, 911 emergency systems, location data for state-owned vehicles, and other sensitive data.
The company, called Banjo, says that it’s combining this data with information collected from social media, satellites, and other apps, and claims its algorithms “detect anomalies” in the real world.
The lofty goal of Banjo’s system is to alert law enforcement of crimes as they happen. It claims it does this while somehow stripping all personal data from the system, allowing it to help cops without putting anyone’s privacy at risk. As with other algorithmic crime systems, there is little public oversight or information about how, exactly, the system determines what is worth alerting cops to.
Jason Mayes apparently likes to do things the hard way: He’s developed an AI-powered tool for browsers that can erase people from live webcam feeds in real-time but leave everything else in the shot.
Mayes is a Google web engineer who developed his Disappearing-People tool using Javascript and TensorFlow, which is Google’s free, open source software library that allows the terrifying potential of artificial intelligence and deep learning to be applied to less terrifying applications. In this case, the neural network works to determine what the static background imagery of a video is in order to develop a clean plate—a version without any humans moving around in the frame—without necessarily requiring the feed to be free of people to start with.
The neural network used in this instance is trained to recognize people, and using that knowledge it can not only generate a clean image of a webcam feed’s background, but it can then actively erase people as they walk into frame and move around, in real-time, while allowing live footage of everything else happening in the background to remain.
Mayes has created test versions of the tool that you can access and try yourself in a browser through his personal GitHub repository. The results aren’t 100 percent perfect just yet (you can still see quite a few artifacts popping up here and there in the sample video he shared where he walks into frame), but as the neural network powering this tool continues to improve, so will the results.
Google has released an open-source tool, Autoflip, that could make bad cropping a thing of the past by intelligently reframing video to correctly fit alternate aspect ratios.
In a blog post, Google’s AI team wrote that footage shot for television and desktop computers normally comes in a 16:9 or 4:3 format, but with mobile devices now outpacing TV in terms of video consumption, the footage is often displayed in a way that looks odd to the end-user. Fixing this problem typically requires “video curators to manually identify salient contents on each frame, track their transitions from frame-to-frame, and adjust crop regions accordingly throughout the video,” soaking up time and effort that could be better spent on other work.
Autoflip aims to fix that with a framework that applies video stabilizer-esque techniques to keep the camera focused on what’s important in the footage. Using “ML-enabled object detection and tracking technologies to intelligently understand video content” built on the MediaPipe framework, Google’s team wrote, it’s able to adjust the frame of a video on the fly.
What’s more, Autoflip automatically adjusts between scenes by identifying “changes in the composition that signify scene changes in order to isolate scenes for processing,” according to the company. Finally, it analyzes each scene to determine whether it should use a static frame or tracking mode.
This is pretty neat and offers obvious advantages over static cropping of videos, though it’s probably better suited to things like news footage and Snapchat videos than movies and TV shows (where being able to view an entire shot is more important).
Modeling immensely complex natural phenomena such as how subatomic particles interact or how atmospheric haze affects climate can take many hours on even the fastest supercomputers. Emulators, algorithms that quickly approximate these detailed simulations, offer a shortcut. Now, work posted online shows how artificial intelligence (AI) can easily produce accurate emulators that can accelerate simulations across all of science by billions of times.
“This is a big deal,” says Donald Lucas, who runs climate simulations at Lawrence Livermore National Laboratory and was not involved in the work. He says the new system automatically creates emulators that work better and faster than those his team designs and trains, usually by hand. The new emulators could be used to improve the models they mimic and help scientists make the best of their time at experimental facilities. If the work stands up to peer review, Lucas says, “It would change things in a big way.”
[…]
creating training data for them requires running the full simulation many times—the very thing the emulator is meant to avoid.
[…]
with a technique called neural architecture search, the most data-efficient wiring pattern for a given task can be identified.
The technique, called Deep Emulator Network Search (DENSE), relies on a general neural architecture search co-developed by Melody Guan, a computer scientist at Stanford University. It randomly inserts layers of computation between the networks’ input and output, and tests and trains the resulting wiring with the limited data. If an added layer enhances performance, it’s more likely to be included in future variations. Repeating the process improves the emulator.
[…]
The researchers used DENSE to develop emulators for 10 simulations—in physics, astronomy, geology, and climate science. One simulation, for example, models the way soot and other atmospheric aerosols reflect and absorb sunlight, affecting the global climate. It can take a thousand of computer-hours to run, so Duncan Watson-Parris, an atmospheric physicist at Oxford and study co-author, sometimes uses a machine learning emulator. But, he says, it’s tricky to set up, and it can’t produce high-resolution outputs, no matter how many data you give it.
The emulators that DENSE created, in contrast, excelled despite the lack of data. When they were turbocharged with specialized graphical processing chips, they were between about 100,000 and 2 billion times faster than their simulations. That speedup isn’t unusual for an emulator, but these were highly accurate: In one comparison, an astronomy emulator’s results were more than 99.9% identical to the results of the full simulation, and across the 10 simulations the neural network emulators were far better than conventional ones. Kasim says he thought DENSE would need tens of thousands of training examples per simulation to achieve these levels of accuracy. In most cases, it used a few thousand, and in the aerosol case only a few dozen.
Thanks to recent software updates, the most sophisticated systems—Cadillac‘s Super Cruise and Tesla‘s Autopilot—are more capable today than they were initially. This report on those systems includes a lesser known third player. For $998, upstart Comma.ai sells an aftermarket dash cam and wiring harness that taps into and overrides the factory-installed assistance systems in many Honda and Toyota models as well as some Chrysler, Kia, and Lexus vehicles, among others. When activated, Comma.ai’s Openpilot software assumes control over the steering, brakes, and throttle, and it reduces the frequent reminders to keep your hands on the wheel. As you might imagine, automakers do not endorse this hack.
[…this bit is where they discuss the Chrysler and Tesla systems in the article…]
Comma.ai’s control is based almost exclusively on a single windshield-mounted camera. A model-specific wiring harness plugs into the vehicle’s stock front camera behind the rearview mirror. That’s where it taps into the car’s communication network, which is used for everything from the power windows to the wheel-speed sensors. There it inserts new messages to actuate the steering, throttle, and brakes on its command while blocking the factory communication. However, certain safety systems, such as forward-collision alert, remain functional. There are no warning lights to indicate that the vehicle senses anything is amiss. And if you start the car with the Comma.ai unit unplugged, everything reverts back to stock. There is no sophisticated calibration procedure. Just stick the supplied GoPro mount somewhere roughly in the middle of the windshield and pop in the Eon camera display. After doing nothing more than driving for a few minutes, the system announces it’s ready.
Given its lack of sensors, we were shocked at the sophisticated control of the system and its ability to center the car in its lane, both on and off the highway. Importantly, Comma.ai collects the data from the 2500 units currently in use in order to learn from errors and make the system smarter. Compared with the others, Openpilot wasn’t quite as locked on its lane, and its control on two-lane roads wasn’t as solid as Autopilot’s, but its performance didn’t degrade perceptibly at night as Super Cruise’s did. However, the following distance, which isn’t adjustable, is roughly double that of Autopilot and Super Cruise in their closest settings, making us feel as though we were endlessly holding up traffic.
Like Super Cruise, the Comma.ai system employs a driver-facing camera to monitor engagement and doesn’t require regular steering inputs. Unlike Super Cruise, it lacks infrared lighting to enable nighttime vision. That will be part of the next hardware update, Hotz says.
Obviously, the system is reliant on the donor vehicle’s hardware, including the car’s steering-torque limitations. So our Honda Passport couldn’t keep up with the sharpest corners and would regularly flash warning messages to the driver, even when the system handled the maneuver appropriately. Hotz promises the next release will dial back the too-frequent warning messages.
Hotz says he has had conversations with car companies about selling his tech, but he doesn’t see the top-down approach as the way to win. Instead, he envisions Comma.ai as a dealer-installed add-on. But that will be difficult, as both Honda and Toyota are against the installation of the system in their vehicles. Toyota has gone so far as to say it will void the factory warranty. This seems shortsighted, though, as the carmakers could learn a lot from what Comma.ai has accomplished.
The greater use of artificial intelligence (AI) and autonomous systems by the militaries of the world has the potential to affect deterrence strategies and escalation dynamics in crises and conflicts. Up until now, deterrence has involved humans trying to dissuade other humans from taking particular courses of action. What happens when the thinking and decision processes involved are no longer purely human? How might dynamics change when decisions and actions can be taken at machine speeds? How might AI and autonomy affect the ways that countries have developed to signal one another about the potential use of force? What are potential areas for miscalculation and unintended consequences, and unwanted escalation in particular?
This exploratory report provides an initial examination of how AI and autonomous systems could affect deterrence and escalation in conventional crises and conflicts. Findings suggest that the machine decisionmaking can result in inadvertent escalation or altered deterrence dynamics, due to the speed of machine decisionmaking, the ways in which it differs from human understanding, the willingness of many countries to use autonomous systems, our relative inexperience with them, and continued developments of these capabilities. Current planning and development efforts have not kept pace with how to handle the potentially destabilizing or escalatory issues associated with these new technologies, and it is essential that planners and decisionmakers begin to think about these issues before fielded systems are engaged in conflict.
Key Findings
Insights from a wargame involving AI and autonomous systems
Manned systems may be better for deterrence than unmanned ones.
Replacing manned systems with unmanned ones may not be seen as a reduced security commitment.
Players put their systems on different autonomous settings to signal resolve and commitment during the conflict.
The speed of autonomous systems did lead to inadvertent escalation in the wargame.
Implications for deterrence
Autonomous and unmanned systems could affect extended deterrence and our ability to assure our allies of U.S. commitment.
Widespread AI and autonomous systems could lead to inadvertent escalation and crisis instability.
Different mixes of human and artificial agents could affect the escalatory dynamics between two sides.
Machines will likely be worse at understanding the human signaling involved deterrence, especially deescalation.
Whereas traditional deterrence has largely been about humans attempting to understand other humans, deterrence in this new age involves understanding along a number of additional pathways.
Past cases of inadvertent engagement of friendly or civilian targets by autonomous systems may offer insights about the technical accidents or failures involving more-advanced systems.
Denis Shiryaev wondered if it could be made more compelling by using neural network powered algorithms (including Topaz Labs’ Gigapixel AI and DAIN) to not only upscale the footage to 4K, but also increase the frame rate to 60 frames per second. You might yell at your parents for using the motion smoothing setting on their fancy new TV, but here the increased frame rate has a dramatic effect on drawing you into the action.
Aside from it still being black and white (which could be dismissed as simply an artistic choice) and the occasional visual artifact introduced by the neural networks, the upgraded version of L’Arrivée d’un train en gare de La Ciotat looks like it could have been shot just yesterday on a smartphone or a GoPro. Even the people waiting on the platform look like the costumed historical reenactors you’d find portraying an old-timey character at a pioneer village.
Google on Tuesday unveiled a feature that’ll let people use their phones to both transcribe and translate a conversation in real time into a language that isn’t being spoken. The tool will be available for the Google Translate app in the coming months, said Bryan Lin, an engineer on the Translate team.
Right now the feature is being tested in several languages, including Spanish, German and French. Lin said the computing will take place on Google’s servers and not on people’s devices.
You can now filter the results based on the types of dataset that you want (e.g., tables, images, text), or whether the dataset is available for free from the provider. If a dataset is about a geographic area, you can see the map. Plus, the product is now available on mobile and we’ve significantly improved the quality of dataset descriptions. One thing hasn’t changed however: anybody who publishes data can make their datasets discoverable in Dataset Search by using an open standard (schema.org) to describe the properties of their dataset on their own web page.
In short, a Neon is an artificial intelligence in the vein of Halo’s Cortana or Red Dwarf’s Holly, a computer-generated life form that can think and learn on its own, control its own virtual body, has a unique personality, and retains its own set of memories, or at least that’s the goal. A Neon doesn’t have a physical body (aside from the processor and computer components that its software runs on), so in a way, you can sort of think of a Neon as a cyberbrain from Ghost in the Shell too. Mistry describes Neon as a way to discover the “soul of tech.”
Here’s a look at three Neons, two of which were part of Mistry’s announcement presentation at CES.
Graphic: Neon
Whatever.
But unlike a lot of the AIs we interact with today, like Siri and Alexa, Neon’s aren’t digital assistants. They weren’t created specifically to help humans and they aren’t supposed to be all-knowing. They are fallible and have emotions, possibly even free will, and presumably, they have the potential to die. Though that last one isn’t quite clear.
OK, but those things look A LOT like humans. What’s the deal?
That’s because Neons were originally modeled on humans. The company used computers to record different people’s faces, expressions, and bodies, and then all that info was rolled into a platform called Core R3, which forms the basis of how Neons appear to look, move, and react so naturally.
Mistry showed how Neon starting out by recording human movements, before transitioning to have Neon’s Core R3 engine generate animations on its own.
Photo: Sam Rutherford (Gizmodo)
If you break it down even further, the three Rs in Core R3 stand for reality, realtime, and responsiveness, each R representing a major tenet for what defines a Neon. Reality is meant to show that a Neon is it’s own thing, and not simply a copy or motion capture footage from an actor or something else. Realtime is supposed to signify that a Neon isn’t just a preprogrammed line of code, scripted to perform a certain task without variation like you would get from a robot. Finally, the part about responsiveness represents that Neons, like humans, can react to stimuli, with Mistry claiming latency as low as a few milliseconds.
Whoo, that’s quite a doozy. Is that it?
Photo: Sam Rutherford (Gizmodo)
Oh, I see, a computer-generated human simulation with emotions, free will, and the ability to die isn’t enough for you? Well, there’s also Spectra, which is Neon’s (the company) learning platform that’s designed to teach Neons (the artificial humans) how to learn new skills, develop emotions, retain memories, and more. It’s the other half of the puzzle. Core R3 is responsible for the look, mannerisms, and animations of a Neon’s general appearance, including their voice. Spectra is responsible for a Neon’s personality and intelligence.
Oh yeah, did we mention they can talk too?
So is Neon Skynet?
Yes. No. Maybe. It’s too early to tell.
That all sounds nice, but what actually happened at Neon’s CES presentation?
After explaining the concept behind Neon’s artificial humans and how the company started off creating their appearance by recording and modeling humans, Mistry showed how after becoming adequately sophisticated, Core R3 engine allows a Neon to animate a realistic-looking avatar on its own.
From left to right, meet Karen, Cathy, and Maya.
Photo: Sam Rutherford (Gizmodo)
Then, Mistry and another Neon employee attempted to present a live demo of a Neon’s abilities, which is sort of when things went awry. To Neon’s credit, Mistry did preface everything by saying the tech is still very early, and given the complexity of the task and issues with doing a live demo at CES, it’s not really a surprise the Neon team ran into technical difficulties.
At first, the demo went smooth, as Mistry introduced three Neons whose avatars were displayed in a row of nearby displays: Karen, an airline worker, Cathy, a yoga instructor, and Maya, a student. From there, each Neon was commanded to perform various things like laugh, smile, and talk, through controls on a nearby tablet. To be clear, in this case, the Neons weren’t moving on their own but were manually controlled to demonstrate the lifelike mannerisms.
For the most part, each Neon did appear quite realistic, avoiding nearly all the awkwardness you get from even high-quality CGI like the kind Disney used animate young Princess Leia in recent Star Wars movies. In fact, when the Neons were asked to move and laugh, the crowd at Neon’s booth let out a small murmur of shock and awe (and maybe fear).
From there, Mistry introduced a fourth Neon along with a visualization of the Neon’s neural network, which is essentially an image of its brain. And after getting the Neon to talk in English, Chinese, and Korean (which sounded a bit robotic and less natural than what you’d hear from Alexa or the Google Assistant), Mistry attempted to demo even more actions. But that’s when the demo seemed to freeze, with the Neon not responding properly to commands.
At this point, Mistry apologized to the crowd and promised that the team would work on fixings things so it could run through more in-depth demos later this week. I’m hoping to revisit the Neon booth to see if that’s the case, so stay tuned for potential updates.
So what’s the actual product? There’s a product, right?
Yes, or at least there will be eventually. Right now, even in such an early state, Mistry said he just wanted to share his work with the world. However, sometime near the end of 2020, Neon plans to launch a beta version of the Neon software at Neon World 2020, a convention dedicated to all things Neon. This software will feature Core R3 and will allow users to tinker with making their own Neons, while Neon the company continues to work on developing its Spectra software to give Neon’s life and emotion.
How much will Neon cost? What is Neon’s business model?
Supposedly there isn’t one. Mistry says that instead of worrying about how to make money, he just wants Neon to “make a positive impact.” That said, Mistry also mentioned that Neon (the platform) would be made available to business partners, who may be able to tweak the Neon software to sell things or serve in call centers or something. The bottom line is this: If Neon can pull off what it’s aiming to pull off, there would be a healthy business in replacing countless service workers.
Neon are going to Neon, I don’t know. I’m a messenger trying to explain the latest chapter of CES quackery. Don’t get me wrong, the idea behind Neon is super interesting and is something sci-fi writers have been writing about for decades. But for right now, it’s not even clear how legit all this is.
Here are some of the core building blocks of Neon’s software.
Photo: Sam Rutherford (Gizmodo)
It’s unclear how much a Neon can do on its own, and how long it will take for Neon to live up to its goal of creating a truly independent artificial human. What is really real? It’s weird, ambitious, and could be the start of a new era in human development. For now? It’s still quackery.
The Trump administration will make it more difficult to export artificial intelligence software as of next week, part of a bid to keep sensitive technologies out of the hands of rival powers like China.
Under a new rule that goes into effect on Monday, companies that export certain types of geospatial imagery software from the United States must apply for a license to send it overseas except when it is being shipped to Canada.
The measure is the first to be finalized by the Commerce Department under a mandate from a 2018 law, which tasked the agency with writing rules to boost oversight of exports of sensitive technology to adversaries like China, for economic and security reasons.
Reuters first reported that the agency was finalizing a set of narrow rules to limit such exports in a boon to U.S. industry that feared a much tougher tougher crackdown on sales abroad.
Just in case you forgot about encryption products, clipper chips etc: US products were weakened with backdoors, which meant a) no-one wanted US products and b) there was a wildfire growth of non-US encryption products. So basically the US goal to limit cryptography failed and at a cost to US producers.
Ever notice that underwater images tend to be be blurry and somewhat distorted? That’s because phenomena like light attenuation and back-scattering adversely affect visibility. To remedy this, researchers at Harbin Engineering University in China devised a machine learning algorithm that generates realistic water images, along with a second algorithm that trains on those images to both restore natural color and reduce haze. They say that their approach qualitatively and quantitatively matches the state of the art, and that it’s able to process upwards of 125 frames per second running on a single graphics card.
The team notes that most underwater image enhancement algorithms (such as those that adjust white balance) aren’t based on physical imaging models, making them poorly suited to the task. By contrast, this approach taps a generative adversarial network (GAN) — an AI model consisting of a generator that attempts to fool a discriminator into classifying synthetic samples as real-world samples — to produce a set of images of specific survey sites that are fed into a second algorithm, called U-Net.
The team trained the GAN on a corpus of labeled scenes containing 3,733 images and corresponding depth maps, chiefly of scallops, sea cucumbers, sea urchins, and other such organisms living within indoor marine farms. They also sourced open data sets including NY Depth, which comprises thousands of underwater photographs in total.
Post-training, the researchers compared the results of their twin-model approach to that of baselines. They point out that their technique has advantages in that it’s uniform in its color restoration, and that it recovers green-toned images well without destroying the underlying structure of the original input image. It also generally manages to recover color while maintaining “proper” brightness and contrast, a task at which competing solutions aren’t particularly adept.
It’s worth noting that the researchers’ method isn’t the first to reconstruct frames from damaged footage. Cambridge Consultants’ DeepRay leverages a GAN trained on a data set of 100,000 still images to remove distortion introduced by an opaque pane of glass, and the open source DeOldify project employs a family of AI models including GANs to colorize and restore old images and film footage. Elsewhere, scientists at Microsoft Research Asia in September detailed an end-to-end system for autonomous video colorization; researchers at Nvidia last year described a framework that infers colors from just one colorized and annotated video frame; and Google AI in June introduced an algorithm that colorizes grayscale videos without manual human supervision.
Boring 2D images can be transformed into corresponding 3D models and back into 2D again automatically by machine-learning-based software, boffins have demonstrated.
The code is known as a differentiable interpolation-based renderer (DIB-R), and was built by a group of eggheads led by Nvidia. It uses a trained neural network to take a flat image of an object as inputs, work out how it is shaped, colored and lit in 3D, and outputs a 2D rendering of that model.
This research could be useful in future for teaching robots and other computer systems how to work out how stuff is shaped and lit in real life from 2D still pictures or video frames, and how things appear to change depending on your view and lighting. That means future AI could perform better, particularly in terms of depth perception, in scenarios in which the lighting and positioning of things is wildly different from what’s expected.
Jun Gao, a graduate student at the University of Toronto in Canada and a part-time researcher at Nvidia, said: “This is essentially the first time ever that you can take just about any 2D image and predict relevant 3D properties.”
During inference, the pixels in each studied photograph are separated into two groups: foreground and background. The rough shape of the object is discerned from the foreground pixels to create a mesh of vertices.
Next, a trained convolutional neural network (CNN) predicts the 3D position and lighting of each vertex in the mesh to form a 3D object model. This model is then rendered as a full-color 2D image using a suitable shader. This allows the boffins to compare the original 2D object to the rendered 2D object to see how well the neural network understood the lighting and shape of the thing.
You looking for an AI project? You love Lego? Look no further than this Reg reader’s machine-learning Lego sorter
During the training process, the CNN was shown stuff in 13 categories in the ShapeNet dataset. Each 3D model was rendered as 2D images viewed from 24 different angles to create a set of training images: these images were used to show the network how 2D images relate to 3D models.
Crucially, the CNN was schooled using an adversarial framework, in which the DIB-R outputs were passed through a discriminator network for analysis.
If a rendered object was similar enough to an input object, then DIB-R’s output passed the discriminator. If not, the output was rejected and the CNN had to generate ever more similar versions until it was accepted by the discriminator. Over time, the CNN learned to output realistic renderings. Further training is required to generate shapes outside of the training data, we note.
As we mentioned above, DIB-R could help robots better detect their environments, Nvidia’s Lauren Finkle said: “For an autonomous robot to interact safely and efficiently with its environment, it must be able to sense and understand its surroundings. DIB-R could potentially improve those depth perception capabilities.”
Online shoppers typically string together a few words to search for the product they want, but in a world with millions of products and shoppers, the task of matching those unspecific words to the right product is one of the biggest challenges in information retrieval.
Using a divide-and-conquer approach that leverages the power of compressed sensing, computer scientists from Rice University and Amazon have shown they can slash the amount of time and computational resources it takes to train computers for product search and similar “extreme classification problems” like speech translation and answering general questions.
The research will be presented this week at the 2019 Conference on Neural Information Processing Systems (NeurIPS 2019) in Vancouver. The results include tests performed in 2018 when lead researcher Anshumali Shrivastava and lead author Tharun Medini, both of Rice, were visiting Amazon Search in Palo Alto, California.
In tests on an Amazon search dataset that included some 70 million queries and more than 49 million products, Shrivastava, Medini and colleagues showed their approach of using “merged-average classifiers via hashing,” (MACH) required a fraction of the training resources of some state-of-the-art commercial systems.
“Our training times are about 7-10 times faster, and our memory footprints are 2-4 times smaller than the best baseline performances of previously reported large-scale, distributed deep-learning systems,” said Shrivastava, an assistant professor of computer science at Rice.
[…]
“Extreme classification problems” are ones with many possible outcomes, and thus, many parameters. Deep learning models for extreme classification are so large that they typically must be trained on what is effectively a supercomputer, a linked set of graphics processing units (GPU) where parameters are distributed and run in parallel, often for several days.
“A neural network that takes search input and predicts from 100 million outputs, or products, will typically end up with about 2,000 parameters per product,” Medini said. “So you multiply those, and the final layer of the neural network is now 200 billion parameters. And I have not done anything sophisticated. I’m talking about a very, very dead simple neural network model.”
“It would take about 500 gigabytes of memory to store those 200 billion parameters,” Medini said. “But if you look at current training algorithms, there’s a famous one called Adam that takes two more parameters for every parameter in the model, because it needs statistics from those parameters to monitor the training process. So, now we are at 200 billion times three, and I will need 1.5 terabytes of working memory just to store the model. I haven’t even gotten to the training data. The best GPUs out there have only 32 gigabytes of memory, so training such a model is prohibitive due to massive inter-GPU communication.”
MACH takes a very different approach. Shrivastava describes it with a thought experiment randomly dividing the 100 million products into three classes, which take the form of buckets. “I’m mixing, let’s say, iPhones with chargers and T-shirts all in the same bucket,” he said. “It’s a drastic reduction from 100 million to three.”
In the thought experiment, the 100 million products are randomly sorted into three buckets in two different worlds, which means that products can wind up in different buckets in each world. A classifier is trained to assign searches to the buckets rather than the products inside them, meaning the classifier only needs to map a search to one of three classes of product.
“Now I feed a search to the classifier in world one, and it says bucket three, and I feed it to the classifier in world two, and it says bucket one,” he said. “What is this person thinking about? The most probable class is something that is common between these two buckets. If you look at the possible intersection of the buckets there are three in world one times three in world two, or nine possibilities,” he said. “So I have reduced my search space to one over nine, and I have only paid the cost of creating six classes.”
Adding a third world, and three more buckets, increases the number of possible intersections by a factor of three. “There are now 27 possibilities for what this person is thinking,” he said. “So I have reduced my search space by one over 27, but I’ve only paid the cost for nine classes. I am paying a cost linearly, and I am getting an exponential improvement.”
In their experiments with Amazon’s training database, Shrivastava, Medini and colleagues randomly divided the 49 million products into 10,000 classes, or buckets, and repeated the process 32 times. That reduced the number of parameters in the model from around 100 billion to 6.4 billion. And training the model took less time and less memory than some of the best reported training times on models with comparable parameters, including Google’s Sparsely-Gated Mixture-of-Experts (MoE) model, Medini said.
He said MACH’s most significant feature is that it requires no communication between parallel processors. In the thought experiment, that is what’s represented by the separate, independent worlds.
“They don’t even have to talk to each other,” Medini said. “In principle, you could train each of the 32 on one GPU, which is something you could never do with a nonindependent approach.”
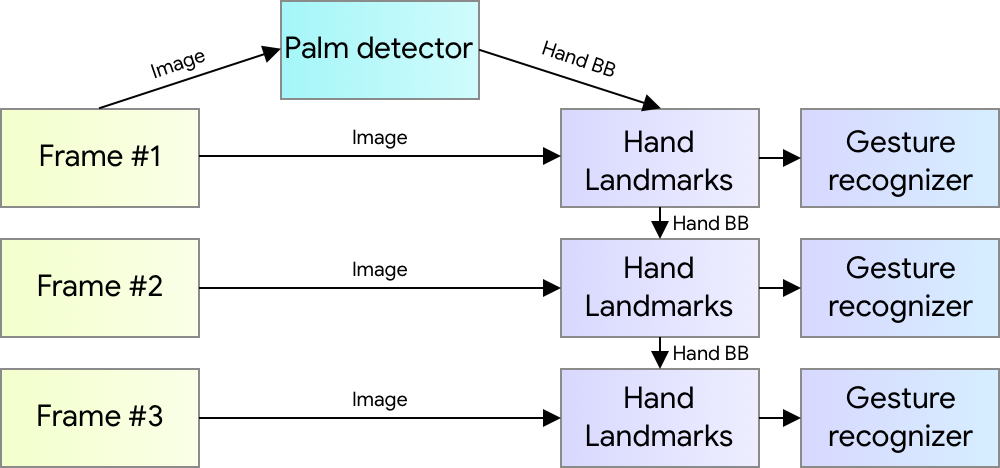
The ability to perceive the shape and motion of hands can be a vital component in improving the user experience across a variety of technological domains and platforms. For example, it can form the basis for sign language understanding and hand gesture control, and can also enable the overlay of digital content and information on top of the physical world in augmented reality. While coming naturally to people, robust real-time hand perception is a decidedly challenging computer vision task, as hands often occlude themselves or each other (e.g. finger/palm occlusions and hand shakes) and lack high contrast patterns. Today we are announcing the release of a new approach to hand perception, which we previewed CVPR 2019 in June, implemented in MediaPipe—an open source cross platform framework for building pipelines to process perceptual data of different modalities, such as video and audio. This approach provides high-fidelity hand and finger tracking by employing machine learning (ML) to infer 21 3D keypoints of a hand from just a single frame. Whereas current state-of-the-art approaches rely primarily on powerful desktop environments for inference, our method achieves real-time performance on a mobile phone, and even scales to multiple hands. We hope that providing this hand perception functionality to the wider research and development community will result in an emergence of creative use cases, stimulating new applications and new research avenues.
3D hand perception in real-time on a mobile phone via MediaPipe. Our solution uses machine learning to compute 21 3D keypoints of a hand from a video frame. Depth is indicated in grayscale.
An ML Pipeline for Hand Tracking and Gesture Recognition Our hand tracking solution utilizes an ML pipeline consisting of several models working together:
A palm detector model (called BlazePalm) that operates on the full image and returns an oriented hand bounding box.
A hand landmark model that operates on the cropped image region defined by the palm detector and returns high fidelity 3D hand keypoints.
A gesture recognizer that classifies the previously computed keypoint configuration into a discrete set of gestures.
This architecture is similar to that employed by our recently published face meshML pipeline and that others have used for pose estimation. Providing the accurately cropped palm image to the hand landmark model drastically reduces the need for data augmentation (e.g. rotations, translation and scale) and instead allows the network to dedicate most of its capacity towards coordinate prediction accuracy.
Hand perception pipeline overview.
BlazePalm: Realtime Hand/Palm Detection To detect initial hand locations, we employ a single-shot detector model called BlazePalm, optimized for mobile real-time uses in a manner similar to BlazeFace, which is also available in MediaPipe. Detecting hands is a decidedly complex task: our model has to work across a variety of hand sizes with a large scale span (~20x) relative to the image frame and be able to detect occluded and self-occluded hands. Whereas faces have high contrast patterns, e.g., in the eye and mouth region, the lack of such features in hands makes it comparatively difficult to detect them reliably from their visual features alone. Instead, providing additional context, like arm, body, or person features, aids accurate hand localization. Our solution addresses the above challenges using different strategies. First, we train a palm detector instead of a hand detector, since estimating bounding boxes of rigid objects like palms and fists is significantly simpler than detecting hands with articulated fingers. In addition, as palms are smaller objects, the non-maximum suppression algorithm works well even for two-hand self-occlusion cases, like handshakes. Moreover, palms can be modelled using square bounding boxes (anchors in ML terminology) ignoring other aspect ratios, and therefore reducing the number of anchors by a factor of 3-5. Second, an encoder-decoder feature extractor is used for bigger scene context awareness even for small objects (similar to the RetinaNet approach). Lastly, we minimize the focal loss during training to support a large amount of anchors resulting from the high scale variance. With the above techniques, we achieve an average precision of 95.7% in palm detection. Using a regular cross entropy loss and no decoder gives a baseline of just 86.22%.
Google has announced a new Explainable AI feature for its cloud platform, which provides more information about the features that cause an AI prediction to come up with its results.
Artificial neural networks, which are used by many of today’s machine learning and AI systems, are modelled to some extent on biological brains. One of the challenges with these systems is that as they have become larger and more complex, it has also become harder to see the exact reasons for specific predictions. Google’s white paper on the subject refers to “loss of debuggability and transparency”.
The uncertainty this introduces has serious consequences. It can disguise spurious correlations, where the system picks on an irrelevant or unintended feature in the training data. It also makes it hard to fix AI bias, where predictions are made based on features that are ethically unacceptable.
AI Explainability has not been invented by Google but is widely researched. The challenge is how to present the workings of an AI system in a form which is easily intelligible.
Google has come up with a set of three tools under this heading of “AI Explainability” that may help. The first and perhaps most important is AI Explanations, which lists features detected by the AI along with an attribution score showing how much each feature affected the prediction. In an example from the docs, a neural network predicts the duration of a bike ride based on weather data and previous ride information. The tool shows factors like temperature, day of week and start time, scored to show their influence on the prediction.
Scored attributions shown by the AI Explainability tool
In the case of images, an overlay shows which parts of the picture were the main factors in the classification of the image content.
There is also a What-If tool that lets you test model performance if you manipulate individual attributes, and a continuous evaluation tool that feeds sample results to human reviewers on a schedule to assist monitoring of results.
AI Explainability is useful for evaluating almost any model and near-essential for detecting bias, which Google considers part of its approach to responsible AI.
When there is a mismatch between the target identity and the driver identity, face reenactment suffers severe degradation in the quality of the result, especially in a few-shot setting. The identity preservation problem, where the model loses the detailed information of the target leading to a defective output, is the most common failure mode. The problem has several potential sources such as the identity of the driver leaking due to the identity mismatch, or dealing with unseen large poses. To overcome such problems, we introduce components that address the mentioned problem: image attention block, target feature alignment, and landmark transformer. Through attending and warping the relevant features, the proposed architecture, called MarioNETte, produces high-quality reenactments of unseen identities in a few-shot setting. In addition, the landmark transformer dramatically alleviates the identity preservation problem by isolating the expression geometry through landmark disentanglement. Comprehensive experiments are performed to verify that the proposed framework can generate highly realistic faces, outperforming all other baselines, even under a significant mismatch of facial characteristics between the target and the driver.
researchers recorded the brain activity of mice staring at images and used the data to help make computer vision models more robust against adversarial attacks.
Convolutional neural networks (CNNs) used for object recognition in images are all susceptible to adversarial examples. These inputs have been tweaked in some way, whether its adding random noise or changing a few pixels here or there, that forces a model to incorrectly recognize an object. Adversarial attacks cause these systems to mistake an image of a banana for a toaster, or a toy turtle for a rifle.
[…]
, a group of researchers led by Baylor College of Medicine, Texas, have turned to mice for inspiration, according to a paper released on arXiv.
“We presented natural images to mice and measured the responses of thousands of neurons from cortical visual areas,” they wrote.
“Next, we denoised the notoriously variable neural activity using strong predictive models trained on this large corpus of responses from the mouse visual system, and calculated the representational similarity for millions of pairs of images from the model’s predictions.”
As you can tell the paper is pretty jargony. In simple terms, the researchers recorded the brain activity of the mice staring at thousands of images and used that data to build a similar computational system that models that activity. To make sure the mice were looking at the image, they were “head-fixed” and put on a treadmill.
[…]
When the CNN was tasked with classifying a different set of images that were not presented to the mice, its accuracy was comparable to a ResNet-18 model that had not been regularized. But as the researchers began adding random noise to those images, the performance of the unregularized models dropped more drastically compared to the regularized version.
“We observed that the CNN model becomes more robust to random noise when neural regularization is used,” the paper said. In other words, the mice-hardened ResNet-18 model is less likely to be fooled by adversarial examples if it contains features that have been borrowed by real biological mouse brains.
The researchers believe that incorporating these “brain-like representations” into machine learning models could help them reach “human-like performance” one day. But although the results seem promising, the researchers have no idea how it really works.
“While our results indeed show the benefit of adopting more brain-like representation in visual processing, it is however unclear which aspects of neural representation make it work. We think that it is the most important question and we need to understand the principle behind it,” they concluded
Algorithms identified death notices in old newspaper pages, then another set of algorithms pulled names and other key details into a searchable database. From a report: Ancestry used artificial intelligence to extract obituary details hidden in a half-billion digitized newspaper pages dating back to 1690, data invaluable for customers building their family trees. The family history and consumer-genomics company, based in Lehi, Utah, began the project in late 2017 and introduced the new functionality last month. Through its subsidiary Newspapers.com, the company had a trove of newspaper pages, including obituaries — but it said that manually finding and importing those death notices to Ancestry.com in a form that was usable for customers would likely have taken years. Instead, Ancestry tasked its 24-person data-science team with having technology pinpoint and make sense of the data. The team trained machine-learning algorithms to recognize obituary content in those 525 million newspaper pages. It then trained another set of algorithms to detect and index key facts from the obituaries, such as names of the deceased’s spouse and children, birth dates, birthplaces and more.
Ancestry, which has about 3.5 million subscribers, now offers about 262 million obituaries, up from roughly 40 million two years ago. Its database includes about a billion names associated with obituaries, including names of the deceased and their relatives. Besides analyzing the trove of old newspaper pages, the algorithms were also applied to online obituaries coming into Ancestry’s database, making them more searchable. Before the AI overhaul, the roughly 40 million obituaries on Ancestry.com were searchable only by the name of the deceased. That meant a search for “Mary R. Smith,” for instance, would yield obituaries only for people with that name — not other obituaries that mentioned that name as a sibling or child.
In modern cities, we’re constantly surveilled through CCTV cameras in both public and private spaces, and by companies trying to sell us shit based on everything we do. We are always being watched.
But what if a simple T-shirt could make you invisible to commercial AIs trying to spot humans?
A team of researchers from Northeastern University, IBM, and MIT developed a T-shirt design that hides the wearer from image recognition systems by confusing the algorithms trying to spot people into thinking they’re invisible.
[…]
A T-shirt is a low-barrier way to move around the world unnoticed by AI watchers. Previously, researchers have tried to create adversarial fashion using patches attached to stiff cardboard, so that the design doesn’t distort on soft fabric while the wearer moves. If the design is warped or part of it isn’t visible, it becomes ineffective.
No one’s going to start carrying cardboard patches around, and most of us probably won’t put Juggalo paint on our faces (at least not until everyone’s doing it), so the researchers came up with an approach to account for the ways that moving cloth distorts an image when generating an adversarial design to print on a shirt. As a result, the new shirt allows the wearer to move naturally while (mostly) hiding the person.
It would be easy to dismiss this sort of thing as too far-fetched to become reality. But as more cities around the country push back against facial recognition in their communities, it’s not hard to imagine some kind of hypebeast Supreme x MIT collab featuring adversarial tees to fool people-detectors in the future. Security professional Kate Rose’s shirts that fool Automatic License Plate Readers, for example, are for sale and walking amongst us already.