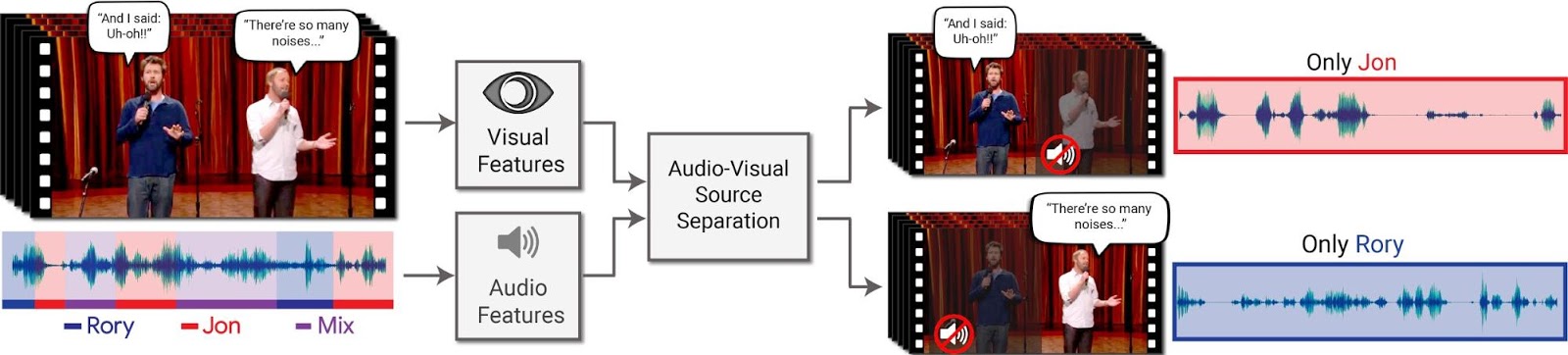
ALPHA is currently viewed as a research tool for manned and unmanned teaming in a simulation environment. In its earliest iterations, ALPHA consistently outperformed a baseline computer program previously used by the Air Force Research Lab for research. In other words, it defeated other AI opponents.
In fact, it was only after early iterations of ALPHA bested other computer program opponents that Lee then took to manual controls against a more mature version of ALPHA last October. Not only was Lee not able to score a kill against ALPHA after repeated attempts, he was shot out of the air every time during protracted engagements in the simulator.
Since that first human vs. ALPHA encounter in the simulator, this AI has repeatedly bested other experts as well, and is even able to win out against these human experts when its (the ALPHA-controlled) aircraft are deliberately handicapped in terms of speed, turning, missile capability and sensors.
Lee, who has been flying in simulators against AI opponents since the early 1980s, said of that first encounter against ALPHA, “I was surprised at how aware and reactive it was. It seemed to be aware of my intentions and reacting instantly to my changes in flight and my missile deployment. It knew how to defeat the shot I was taking. It moved instantly between defensive and offensive actions as needed.”
He added that with most AIs, “an experienced pilot can beat up on it (the AI) if you know what you’re doing. Sure, you might have gotten shot down once in a while by an AI program when you, as a pilot, were trying something new, but, until now, an AI opponent simply could not keep up with anything like the real pressure and pace of combat-like scenarios.”
[…]
Eventually, ALPHA aims to lessen the likelihood of mistakes since its operations already occur significantly faster than do those of other language-based consumer product programming. In fact, ALPHA can take in the entirety of sensor data, organize it, create a complete mapping of a combat scenario and make or change combat decisions for a flight of four fighter aircraft in less than a millisecond. Basically, the AI is so fast that it could consider and coordinate the best tactical plan and precise responses, within a dynamic environment, over 250 times faster than ALPHA’s human opponents could blink.
[…]
It would normally be expected that an artificial intelligence with the learning and performance capabilities of ALPHA, applicable to incredibly complex problems, would require a super computer in order to operate.
However, ALPHA and its algorithms require no more than the computing power available in a low-budget PC in order to run in real time and quickly react and respond to uncertainty and random events or scenarios.
[…]
To reach its current performance level, ALPHA’s training has occurred on a $500 consumer-grade PC. This training process started with numerous and random versions of ALPHA. These automatically generated versions of ALPHA proved themselves against a manually tuned version of ALPHA. The successful strings of code are then “bred” with each other, favoring the stronger, or highest performance versions. In other words, only the best-performing code is used in subsequent generations. Eventually, one version of ALPHA rises to the top in terms of performance, and that’s the one that is utilized.
[…]
ALPHA is developed by Psibernetix Inc., serving as a contractor to the United States Air Force Research Laboratory.
Support for Ernest’s doctoral research, $200,000 in total, was provided over three years by the Dayton Area Graduate Studies Institute and the U.S. Air Force Research Laboratory.
Source: New Artificial Intelligence Beats Tactical Experts in Combat Simulation, University of Cincinnati