In the EU, Meta has given you a warning saying that you need to choose for an expensive ad free version or continue using targetted adverts. Strangely, considering Meta makes it’s profits by selling your information, you don’t get the option to be paid a cut of the profits they gain by selling your information. Even more strangely, not many people are covering it. Below is a pretty good writeup of the situation, but what is not clear is whether by agreeing to the free version, things continue as they are, or are you signing up for additional invasions into your privacy, such as sending your information to servers into the USA.
Even though it’s a seriously and strangely underreported phenomenon, people are leaving Meta for fear (justly or unjustly) of further intrusions into their privacy by the slurping behemoth.
Why is Meta launching an ad-free plan for Instagram and Facebook?
After receiving major backlash from the European Union in January 2023, resulting in a €377 million fine for the tech giant, Meta has since adapted their applications to suit EU regulations. These major adaptions have all led to the recent launch of their ad-free subscription service.
This most recent announcement comes to keep in line with the European Union’s Digital Marketers Act legislation. The legislation requires companies to give users the option to give consent before being tracked for advertising reasons, something Meta previously wasn’t doing.
As a way of complying with this rule while also sustaining its ad-supported business model, Meta is now releasing an ad-free subscription service for users who don’t want targeted ads showing up on their Instagram and Facebook feeds while also putting some more cash in the company’s pocket.
How much will the ad-free plan cost on Instagram and Facebook?
Austin Distel on Unsplash
The price depends on where you purchase the subscription. If you purchase the ad-free plan from Meta for your desktop, then the plan will cost €9.99/month. If you purchase on your Android or IOS device, the plan will cost €12.99/month. Presumably, this is because Apple and Google charge fees, and Meta is passing those fees along to the user instead of taking a hit on its profit.
If I buy the plan on desktop, will the subscription carry over to my phone?
Yes! It’s confusing at first, but no matter where you sign up for your subscription, it will automatically link to all your meta accounts, allowing you to view ad-free content on every device. Essentially, if you have access to a desktop and are interested in signing up for the ad-free plan, you’re better off signing up there, as you’ll save some money.
When will the ad-free plan be available to Instagram and Facebook users?
The subscription will be available for users in November 2023. Meta didn’t announce a specific date.
“In November, we will be offering people who use Facebook or Instagram and reside in these regions the choice to continue using these personalised services for free with ads, or subscribe to stop seeing ads.”
Can I still use Instagram and Facebook without subscribing to Meta’s ad-free plan?
Meta’s statement said that it believes “in an ad-supported internet, which gives people access to personalized products and services regardless of their economic status.” Staying true to its beliefs, Meta will still allow users to use its services for free with ads.
However, it’s important to note that Meta mentioned in its statement, “Beginning March 1, 2024, an additional fee of €6/month on the web and €8/month on iOS and Android will apply for each additional account listed in a user’s Account Center.” So, for now, the subscription will cover accounts on all platforms, but the cost will rise in the future for users with more than one account
Which countries will get the new. ad-free subscription option?
The below countries can access Meta’s new subscription:
Austria, Belgium, Bulgaria, Croatia, Republic of Cyprus, Czech Republic, Denmark, Estonia, Finland, France, Germany, Greece, Hungary, Iceland, Ireland, Italy, Latvia, Lichtenstein, Lithuania, Luxembourg, Malta, Norway, Netherlands, Poland, Portugal, Romania, Slovakia, Slovenia, Spain, Switzerland and Sweden.
Will Meta launch this ad-free plan outside the EU and Switzerland?
It’s unknown at the moment whether Meta plans to expand this service into any other regions. Currently, the only regions able to subscribe to an ad-free plan are those listed above, but if it’s successful in those countries, it’s possible that Meta could roll it out in other regions.
What’s the difference between Meta Verified and this ad-free plan?
Launched in early 2023, Meta Verified allows Facebook and Instagram users to pay for a blue tick mark next to their name. Yes, the same tick mark most celebrities with major followings typically have. This subscription service was launched as a way for users to protect their accounts and promote their businesses. Meta Verified costs $14.99/month (€14/month). It gives users the blue tick mark and provides extra account support and protection from impersonators.
Unsplash/Pocket-lint
While Meta Verified offers several unique account privacy features for users, it doesn’t offer an ad-free subscription. Currently, those subscribed to Meta Verified must also pay for an ad-free account if they live in one of the supported countries.
How can I sign up for Meta’s ad-free plan for Instagram and Facebook?
Users can sign up for the ad-free subscription via their Facebook or Instagram accounts. Here’s what you need to sign up:
Go to account settings on Facebook or Instagram.
Click subscribe on the ad-free plan under the subscriptions tab (once it’s available).
If I choose not to subscribe, will I receive more ads than I do now?
Meta says that nothing will change about your current account if you choose to keep your account as is, meaning you don’t subscribe to the ad-free plan. In other words, you’ll see exactly the same amount of ads you’ve always seen.
How will this affect other social media platforms?
Paid subscriptions seem to be the trend among many social media platforms in the past couple of years. Snapchat hopped onto the trend early in the Summer of 2022 when they released Snapchat+, which allows premium users to pay $4/month to see where they rank on their friends’ best friends list, boost their stories, pin friends as their top best friends, and further customize their settings.
More notably, Twitter, famously bought by Elon Musk, who now rebranded the platform to “X,” released three different tiers of subscriptions meant to improve a user’s experience. The tiers include Basic, Premium, and Premium Plus. X’s latest release, the Premium+ tier, allows users to pay $16/month for an ad-free experience and the ability to edit or undo their posts.
Pocket-lint
Other major apps, such as TikTok, have yet to announce any ad-free subscription plans, although it wouldn’t be shocking if they followed suit.
For Meta’s part, it claims to want its websites to remain a free ad-based revenue domain, but we’ll see how long that lasts, especially if its first two subscription offerings succeed.
What else is noteworthy, is that this comes as Youtube is installing spyware onto your computer to figure out if you are running an adblocker – also something not receiving enough attention.
Many courts have already dealt with these lawsuits-come-lately filed by opportunistic people who failed to capitalize on their own pop culture cache but thought it was worth throwing a few hundred dollars in filing fees towards a federal court in hopes that the eventual payoff would be millions.
Most of these efforts have failed. Dance moves are tough to copyright, considering they’re often not a cohesive form of expression. On top of that, there’s a whole lot of independent invention because the human body is only capable of so many dance moves that portray talent, rather than just an inability to control your limbs.
Hence the federal court’s general hesitance to proclaim controlled flailing protectable. And hence the failure of most these Fortnite-is-worth-millions lawsuits written by people with dollar signs for eyes and Web 2.0 ambulance chasers for lawyers.
But one of these lawsuits has been revived by the Ninth Circuit, which has decided a certain number of sequential dance steps is actual intellectual property worth suing over. Here’s Wes Davis with more details for The Verge:
This week, a panel of US appeals court judges has renewed the legal battle over Fortnite dance moves by reversing the dismissal of a lawsuit filed last year by professional choreographer Kyle Hanagami against Epic Games.
[…]
The lower court said choreographic works are made up of poses that aren’t protectable alone.It found that the steps and poses of dance choreography used by characters in Fortnite were not “substantially similar, other than the four identical counts of poses” because they don’t “share any creative elements” with Hanagami’s work.
The 9th Circuit panel agreed with the lower court that “choreography is composed of various elements that are unprotectable when viewed in isolation.” However, Judge Richard Paez wrote this week that referring to portions of choreography as “poses” was like calling music “just ‘notes.’” They also found that choreography can involve other elements like timing, use of space, and even the energy of the performance.
This is a strange conclusion to reach given prior case law on the subject. But a lot of prior Fortnite case law is based on the fact that complainants never made any attempt to copyright their moves, but rather decided they were owed a living by Fortnite’s producer (Epic Games) simply because Fortnite (and Epic Games) were extremely successful.
That’s not the case here, as the Ninth Circuit [PDF] notes:
Plaintiff Kyle Hanagami (“Hanagami”) is a celebrity choreographer who owns a validly registered copyright in a five-minute choreographic work.
That’s a point in Hanagami’s favor. Whether or not this particular expression is protected under copyright law is no longer an open question. It has been registered with the US Copyright office, thus making it possible for Hanagami to seek a payout that far exceeds actual damages that can be proven in court.
As was noted above, the lower court compared Hanagami’s registered work with the allegedly infringing “emote” and found that, at best, only small parts had been copied.
The Ninth Circuit disagrees.
The district court erred by ruling that, as a matter of law, the Steps are unprotectable because they are relatively brief. Hanagami has more than plausibly alleged that the four-count portion has substantial qualitative significance to the overall Registered Choreography. The four counts in question are repeated eight times throughout the Registered Choreography, corresponding to the chorus and titular lyrics of the accompanying song. Hanagami alleges that the segment is the most recognizable and distinctive portion of his work, similar to the chorus of a song. Whether or not a jury would ultimately find the copied portion to be qualitatively significant is a question for another day. We conclude only that the district court erred in dismissing Hanagami’s copyright claim on the basis that Epic allegedly infringed only a relatively small amount of the Registered Choreography.
This allows the lawsuit to move forward. The Ninth Circuit does not establish a bright line ruling that would encourage/deter similar lawsuits. Nor does it establish a baseline to guide future rulings. Instead, it simply says some choreography is distinctive enough plaintiffs can sue over alleged infringement, but most likely, it will be a jury deciding these facts, rather than a judge handling motions to dismiss.
So… maybe that’s ok? I can understand the point that distinctive progressive dance steps are as significant as distinctive chord progressions when it comes to expression that can be copyrighted. But, on the other hand, the lack of guidance from the appellate level encourages speculative litigation because it refuses to make a call one way or the other but simply decides the lower court is (1) wrong and (2) should handle all the tough questions itself.
Where this ends up is tough to say. But, for now, it guarantees someone who rues every “emote” purchase made for my persistent offspring will only become more “get off my lawn” as this litigation progresses.
In response to criticism suggesting that the ban on short selling implemented on Nov. 6 is a “political decision” aimed at next year’s general election, Lee Bok-hyun, the head of the Financial Supervisory Service (FSS), directly refuted the claims, stating, “About 100 stocks were identified as targets for naked short selling.” He said that it was a decisive measure to uproot rampant illegal short selling in the stock market.
[…]
“Currently, around 100 stocks, regardless of whether they are listed on the KOSPI or KOSDAQ, have been identified as subjects of naked, or illegal, short selling, and additional investigations are ongoing.”
[…]
He described the current situation regarding short selling as, “Not just a street with many broken windows, but rather a market where illegality has become so widespread that all the windows are shattered.”
[…]
Naked shorting is the illegal practice of short-selling shares that have not been affirmatively determined to exist. Ordinarily, traders must borrow a stock or determine that it can be borrowed before they sell it short. So naked shorting refers to short pressure on a stock that may be larger than the tradable shares in the market.
Despite being made illegal after the 2008–09 financial crisis, naked shorting continues to happen because of loopholes in rules and discrepancies between paper and electronic trading systems.
This and dark pool trading well all exposed by the GameStop / #GME explosion a few years ago. It’s nice to see someone finally taking it seriously, even if it is Korea and not the USA.
The FTC has accused Kochava of violating the FTC Act by amassing and disclosing “a staggering amount of sensitive and identifying information about consumers,” alleging that Kochava’s database includes products seemingly capable of identifying nearly every person in the United States.
According to the FTC, Kochava’s customers, ostensibly advertisers, can access this data to trace individuals’ movements—including to sensitive locations like hospitals, temporary shelters, and places of worship, with a promised accuracy within “a few meters”—over a day, a week, a month, or a year. Kochava’s products can also provide a “360-degree perspective” on individuals, unveiling personally identifying information like their names, home addresses, phone numbers, as well as sensitive information like their race, gender, ethnicity, annual income, political affiliations, or religion, the FTC alleged.
Beyond that, the FTC alleged that Kochava also makes it easy for advertisers to target customers by categories that are “often based on specific sensitive and personal characteristics or attributes identified from its massive collection of data about individual consumers.” These “audience segments” allegedly allow advertisers to conduct invasive targeting by grouping people not just by common data points like age or gender, but by “places they have visited,” political associations, or even their current circumstances, like whether they’re expectant parents. Or advertisers can allegedly combine data points to target highly specific audience segments like “all the pregnant Muslim women in Kochava’s database,” the FTC alleged, or “parents with different ages of children.”
[…]
According to the FTC, Kochava obtains data “from a myriad of sources, including from mobile apps and other data brokers,” which together allegedly connects a web of data that “contains information about consumers’ usage of over 275,000 mobile apps.”
The FTC alleged that this usage data is also invasive, allowing Kochava customers to track not just what apps a customer uses, but how long they’ve used the apps, what they do in the apps, and how much money they spent in the apps, the FTC alleged.
[…]
Kochava “actively promotes its data as a means to evade consumers’ privacy choices,” the FTC alleged. Further, the FTC alleged that there are no real ways for consumers to opt out of Kochava’s data marketplace, because even resetting their mobile advertising IDs—the data point that’s allegedly most commonly used to identify users in its database—won’t stop Kochava customers from using its products to determine “other points to connect to and securely solve for identity.”
[…]
Kochava hoped the court would impose sanctions on the FTC because Kochava argued that many of the FTC’s allegations were “knowingly false.” But Winmill wrote that the bar for imposing sanctions is high, requiring that Kochava show that the FTC’s complaint was not just implausibly pled, but “clearly frivolous,” raised “without legal foundation,” or “brought for an improper purpose.”
In the end, Winmill denied the request for sanctions, partly because the court could not identify a “single” allegation in the FTC complaint flagged by Kochava as false that actually appeared “false or misleading,” the judge wrote.
Instead, it seemed like Kochava was attempting to mislead the court.
[…]
“The Court concludes that the FTC’s legal and factual allegations are not frivolous,” Winmill wrote, dismissing Kochava’s motion for sanctions. The judge concluded that Kochava’s claims that the FTC intended to harass and generate negative publicity about the data broker were ultimately “long on hyperbole and short on facts.”
A federal judge on Tuesday refused to bring back a class action lawsuit alleging four auto manufacturers had violated Washington state’s privacy laws by using vehicles’ on-board infotainment systems to record and intercept customers’ private text messages and mobile phone call logs.
The Seattle-based appellate judge ruled that the practice does not meet the threshold for an illegal privacy violation under state law, handing a big win to automakers Honda, Toyota, Volkswagen and General Motors, which are defendants in five related class action suits focused on the issue. One of those cases, against Ford, had been dismissed on appeal previously.
The plaintiffs in the four live cases had appealed a prior judge’s dismissal. But the appellate judge ruled Tuesday that the interception and recording of mobile phone activity did not meet the Washington Privacy Act’s standard that a plaintiff must prove that “his or her business, his or her person, or his or her reputation” has been threatened.
In an example of the issues at stake, plaintiffs in one of the five cases filed suit against Honda in 2021, arguing that beginning in at least 2014 infotainment systems in the company’s vehicles began downloading and storing a copy of all text messages on smartphones when they were connected to the system.
An Annapolis, Maryland-based company, Berla Corporation, provides the technology to some car manufacturers but does not offer it to the general public, the lawsuit said. Once messages are downloaded, Berla’s software makes it impossible for vehicle owners to access their communications and call logs but does provide law enforcement with access, the lawsuit said.
Many car manufacturers are selling car owners’ data to advertisers as a revenue boosting tactic, according to earlier reporting by Recorded Future News. Automakers are exponentially increasing the number of sensors they place in their cars every year with little regulation of the practice.
A new feature in WhatsApp will let you hide your IP address from whoever you call using the app. Knowing someone’s IP address can reveal a lot of personal information such as their location and internet service provider, so having the option to hide it is a major privacy win. “This new feature provides an additional layer of privacy and security geared towards our most privacy-conscious users,” WhatsApp wrote in a blog post.
WhatsApp currently relays calls either through its own servers or by establishing a direct connection called peer-to-peer with whoever you are calling depending on network conditions. Peer-to-peer calls often provide better voice quality, but require both devices to know each other’s IP addresses.
Once you turn the new feature, known simply as “Protect IP address in calls” on, however, WhatsApp will always relay your calls through its own servers rather than establishing a peer-to-peer connection, even if it means a slight hit to sound quality. All calls will continue to remain end-to-end encrypted, even if they go through WhatsApp’s servers, the company said.
WhatsApp has been adding more privacy features over the last few months. In June, the company added a feature that let people automatically silence unknown callers. It also introduced a “Privacy Checkup” section to allow users to tune up a host of privacy settings from a single place in the app, and earlier this year, added a feature that lets people lock certain chats with a fingerprint or facial recognition.
So this means that Meta / Facebook / Whatsapp will now know who you are calling with, once you turn this privacy feature on. So to gain some privacy towards the end caller, you sacrifice privacy towards Meta.
It truly is amazing that the video game industry is so heavily divided on the topic of user-made game mods. I truly don’t understand it. My take has always been very simple: mods are good for gamers and even better for game makers. Why? Simple, mods serve to extend the useful life of video games by adding new ways to play them and therefore making them more valuable, they can serve to fix or make better the original game thereby doing some of the game makers work for them for free, and can simply keep a classic game relevant decades later thanks to a dedicated group of fans of a franchise that continues to be a cash cow to this day.
On the other hand are all the studios and publishers that somehow see mods as some kind of threat, even outside of the online gaming space. Take Two, Nintendo, EA: the list goes on and on and on. In most of those cases, it simply appears that control is preferred by the publisher over building an active community and gaining all the benefits that come along with that modding community.
And then there’s Capcom, which recently made some statements essentially claiming that for all practical purposes mods are just a different form of cheating and that mods hurt the gaming experience for the public.
“For the purposes of anti-cheat and anti-piracy, all mods are defined as cheats,” Capcom explained. The only exception to this are mods which are “officially” supported by the developer and, as Capcom sees it, all user-created mods are “internally” no different than cheating.
Capcom goes on to say that some mods with offensive content can be “detrimental” to a game or franchise’s reputation. The publisher also explained that mods can create new bugs and lead to more players needing support, stretching resources, and leading to increased game development costs or even delays. (I can’t help but feel my eyes starting to roll…)
I’m sorry, but just… no. No to pretty much all of this. Mods do not need to be defined as cheats, particularly in offline single player games. Mods are mods, cheats are cheats. There are a zillion different aesthetic and/or quality of life mods that exist for hundreds of games that fall into this category. Skipping intro videos for games, which I do in Civilization, cannot possibly be equated to cheating within the game, but that’s a mod.
As to the claim that mods increase development time because support teams have to handle requests from people using mods that are causing problems within the games… come on, now. Support and dev teams are very distinct and I refuse to believe this is a big enough problem to even warrant a comment.
As to offensive mods, here I have some sympathy. But I also have a hard time believing that the general public is really looking with narrow eyes at publishers of games because of what third-party mods do to their product. Mods like that exist for all kinds of games and those publishers and developers appear to be getting on just fine.
Whatever the reason behind Capcom’s discomfort with mods, it should think long and hard about its stance and decide whether it’s valid. We have seen time and time again examples of modding communities being a complete boon to publishers and I see no reason why Capcom should be any different.
So they allow people to play the game in new and unexpected ways. The same does go for cheats. Sometimes you just don’t have the patience to do that boss fight for the 100th time. Sometimes you just want to get through the game. Sometimes you want to play that super 1/1000 drop chance rare item. If you’re not online, then mod and cheat the hell out of the game. It yours! You paid for it, installed the code on your hard drive. It’s out of the hands of the publisher.
The EU is currently updating eIDAS (electronic IDentification, Authentication and trust Services), an EU regulation on electronic identification and trust services for electronic transactions in the European Single Market.
[…]
Back in March 2022, a group of experts sent an open letter to MEPs [pdf] […]
It warned:
The Digital Identity framework includes provisions that are intended to increase the take-up of Qualified Website Authentication Certificates (QWACs), a specific EU form of website certificate that was created in the 2014 eIDAS regulation but which – owing to flaws with its technical implementation model – has not gained popularity in the web ecosystem. The Digital Identity framework mandates browsers accept QWACs issued by Trust Service Providers, regardless of the security characteristics of the certificates or the policies that govern theirissuance. This legislative approach introduces significant weaknesses into the global multi-stakeholder ecosystem for securing web browsing, and will significantly increase the cybersecurity risks for users of the web.
The near-final text for eIDAS 2.0 has now been agreed by the EU’s negotiators, and it seems that it is even worse than the earlier draft. A new site from Mozilla called “Last Chance to fix eIDAS” explains how new legislative articles will require all Web browsers in Europe to trust the the certificate authorities and cryptographic keys selected by the government of EU Member States. Mozilla explains:
These changes radically expand the capability of EU governments to surveil their citizens by ensuring cryptographic keys under government control can be used to intercept encrypted web traffic across the EU. Any EU member state has the ability to designate cryptographic keys for distribution in web browsers and browsers are forbidden from revoking trust in these keys without government permission.
This enables the government of any EU member state to issue website certificates for interception and surveillance which can be used against every EU citizen, even those not resident in or connected to the issuing member state. There is no independent check or balance on the decisions made by member states with respect to the keys they authorize and the use they put them to. This is particularly troubling given that adherence to the rule of law has not been uniform across all member states, with documented instances of coercion by secret police for political purposes.
To make matters worse, browser producers will be forbidden from carrying out routine and necessary checks
[…]
for those interested in understanding the underlying technology, there’s an excellent introduction to eIDAS and QWACs from Eric Rescorla on the Educated Guesswork blog. But there’s a less technical issue too. Mozilla writes that:
forcing browsers to automatically trust government-backed certificate authorities is a key tactic used by authoritarian regimes, and these actors would be emboldened by the legitimising effect of the EU’s actions. In short, if this law were copied by another state, it could lead to serious threats to cybersecurity and fundamental rights.
[…]
the insinuation that this is just an attempt by Google to head off some pesky EU legislation is undercut by the fact that separately from Mozilla, 335 scientists and researchers from 32 countries and various NGOs have signed a joint statement criticizing the proposed eIDAS reform. If the latest text is adopted, they warn:
the government-controlled authority would then be able to intercept the web traffic of not only their own citizens, but all EU citizens, including banking information, legally privileged information, medical records and family photos. This would be true even when visiting non-EU websites, as such an authority could issue certificates for any website that all browsers would have to accept. Additionally, although much of eIDAS2.0 regulation carefully gives citizens the capability to opt out from usage of new services and functionality, this is not the case for Article 45. Every citizen would have to trust those certificates, and thus every citizen would see their online safety threatened.
[…]
It’s a blatant power-grab by the EU, already attempting to circumvent encryption elsewhere with its Chat Control proposals. It must be stopped before it undermines core elements of the Internet’s security infrastructure not just in the EU, but globally too as result of its knock-on effects.
The EU Ombudsman has found a case of maladministration in theEuropean Commission’s refusal to provide the list of experts, which it first denied existing, with whom they worked together in drafting the regulation to detect and remove online child sexual abuse material.
Last December, the Irish Council for Civil Liberties (ICCL) filed complaints to the European Ombudsman against the European Commission for refusing to provide the list of external experts involved in drafting the regulation to detect and remove online child sexual abuse material (CSAM).
Consequently, the Ombudsman concluded that “the Commission’s failure to identify the list of experts as falling within the scope of the complainant’s public access request constitutes maladministration”.
The EU watchdog also slammed the Commission for not respecting the deadlines for handling access to document requests, delays that have become somewhat systematic.
The Commission told the Ombudsman inquiry team during a meeting that the requests by the ICCL “seemed to be requests to justify a political decision rather than requests for public access to a specific set of documents”.
The request was about getting access to the list of experts the Commission was in consultations with and who also participated in meetings with the EU Internet Forum, which took place in 2020, according to an impact assessment report dated 11 May 2022.
The main political groups of the EU Parliament reached an agreement on the draft law to prevent the dissemination of online child sexual abuse material (CSAM) on Tuesday (24 October).
The list of experts was of public interest because independent experts have stated on several occasions that detecting CSAM in private communications without violating encryption would be impossible.
The Commission, however, suggested otherwise in their previous texts, which has sparked controversy ever since the introduction of the file last year.
During the meetings, “academics, experts and companies were invited to share their perspectives on the matter as well as any documents that could be valuable for the discussion.”
Based on these discussions, and both oral and written inputs, an “outcome document” was produced, the Commission said.
According to a report about the meeting between the Commission and the Ombudsman, this “was the only document that was produced in relation to these workshops.”
The phantom list
While a list of participants does exist, it was not disclosed “for data protection and public security reasons, given the nature of the issues discussed”, the Commission said, according to the EU Ombudsman.
Besides security reasons, participants were also concerned about their public image, the Commission told the EU Ombudsman, adding that “disclosure could be exploited by malicious actors to circumvent detection mechanisms and moderation efforts by companies”.
Moreover, “revealing some of the strategies and tactics of companies, or specific technical approaches also carries a risk of informing offenders on ways to avoid detection”.
However, the existence of this list was at first denied by the Commission.
Kris Shrishak, senior fellow at the Irish Council for Civil Liberties, told Euractiv that the Commission had told him that no such list exists. However, later on, he was told by the EU Ombudsman that that was not correct since they found a list of experts.
The only reason the ICCL learned that there is a list is because of the Ombudsman, Shrishak emphasised.
Previously, the Commission said there were email exchanges about the meetings, which contained only the links to the online meetings.
“Following the meeting with the Ombudsman inquiry team, the Commission tried to retrieve these emails” but since they were more than two years old at the time, “they had already been deleted in line with the Commission’s retention policy” and were “not kept on file”.
Euractiv reached out to the European Commission for a comment but did not get a response by the time of publication.
This law is an absolute travesty – it’s talking about the poor children (how can we not protect them!) whilst being a wholesale surveillance law being put in by nameless faces and unelected officials.
Researchers at Duke University released a study on Monday tracking what measures data brokers have in place to prevent unidentified or potentially malign actors from buying personal data on members of the military. As it turns out, the answer is often few to none — even when the purchaser is actively posing as a foreign agent.
A 2021 Duke study by the same lead researcher revealed that data brokers advertised that they had access to — and were more than happy to sell —information on US military personnel. In this more recent study researchers used wiped computers, VPNs, burner phones bought with cash and other means of identity obfuscation to go undercover. They scraped the websites of data brokers to see which were likely to have available data on servicemembers. Then they attempted to make those purchases, posing as two entities: datamarketresearch.org and dataanalytics.asia. With little-or-no vetting, several of the brokers transferred the requested data not only to the presumptively Chicago-based datamarketresearch, but also to the server of the .asia domain which was located in Singapore. The records only cost between 12 to 32 cents a piece.
The sensitive information included health records and financial information. Location data was also available, although the team at Duke decided not to purchase that — though it’s not clear if this was for financial or ethical reasons. “Access to this data could be used by foreign and malicious actors to target active-duty military personnel, veterans, and their families and acquaintances for profiling, blackmail, targeting with information campaigns, and more,” the report cautions. At an individual level, this could also include identity theft or fraud.
This gaping hole in our national security apparatus is due in large part to the absence of comprehensive federal regulations governing either individual data privacy, or much of the business practices engaged in by data brokers. Senators Elizabeth Warren, Bill Cassidy and Marco Rubio introduced the Protecting Military Service Members’ Data Act in 2022 to give power to the Federal Trade Commission to prevent data brokers from selling military personnel information to adversarial nations. They reintroduced the bill in March 2023 after it stalled out. Despite bipartisan support, it still hasn’t made it past the introduction phase.
YouTube wants its pound of flesh. Disable your ad blocker or pay for Premium, warns a new message being shown to an unsuspecting test audience, with the barely hidden subtext of “you freeloading scum.” Trouble is, its ad blocker detecting mechanism doesn’t exactly comply with EU law, say privacy activists. Ask for user permission or taste regulatory boot. All good clean fun.
Privacy advocate challenges YouTube’s ad blocking detection scripts under EU law
Only it isn’t. It’s profoundly depressing. The battleground between ad tech and ad blockers has been around so long that in the internet’s time span it’s practically medieval. In 2010, Ars Technica started blocking ad blockers; in under a day, the ad blocker blocker was itself blocked by the ad blockers. The editor then wrote an impassioned plea saying that ad blockers were killing online journalism. As the editor ruefully notes, people weren’t using blockers because they didn’t care about the good sites, it was because so much else of the internet was filled with ad tech horrors.
Nothing much has changed. If your search hit ends up with an “ERROR: Ad blocker detected. Disable it to access this content” then it’s browser back button and next hit down, all day, every day. It’s like running an app that asks you to disable your firewall; that app is never run again. Please disable my ad blocker? Sure, if you stop pushing turds through my digital letterbox.
The reason YouTube has been dabbling with its own “Unblock Or Eff Off” strategy instead of bringing down the universal banhammer is that it knows how much it will upset the balance of the ecosystem. That it’s had to pry deep enough into viewers’ browsers to trigger privacy laws shows just how delicate that balance is. It’s unstable because it’s built on bad ideas.
In that ecosystem of advertisers, content consumers, ad networks, and content distributors, ad blockers aren’t the disease, they’re the symptom. Trying to neutralize a symptom alone leaves the disease thriving while the host just gets sicker. In this case, the disease isn’t cynical freeloading by users, it’s the basic dishonesty of online advertising. It promises things to advertisers that it cannot deliver, while blocking better ways of working. It promises revenue to content providers while keeping them teetering on the brink of unviability, while maximizing its own returns. Google has revenues in the hundreds of billions of dollars, while publishers struggle to survive, and users have to wear a metaphorical hazmat suit to stay sane. None of this is healthy.
Content providers have to be paid. We get that. Advertising is a valid way of doing that. We get that too. Advertisers need to reach audiences. Of course they do. But like this? YouTube needs its free, ad-supported model, or it would just force Premium on everyone, but forcing people to watch adverts will not force them to pony up for what’s being advertised.
The pre-internet days saw advertising directly support publishers who knew how to attract the right audiences who would respond well to the right adverts. Buy a computer magazine and it would be full of adverts for computer stuff – much of which you’d actually want to look at. The publisher didn’t demand you have to see ads for butter or cars or some dodgy crypto. That model has gone away, which is why we need ad blockers.
YouTube’s business model is a microcosm of the bigger ad tech world, where it basically needs to spam millions to generate enough results for its advertisers. It cannot stomach ad blockers, but it can’t neutralize them technically or legally. So it should treat them like the cognitive firewalls they are. If YouTube developed ways to control what and how adverts appeared back into the hands of its content providers and viewers, perhaps we’d tell our ad blockers to leave YouTube alone – punch that hole through the firewall for the service you trust. We’d get to keep blocking things that needed to be blocked, content makers could build their revenues by making better content, and advertisers would get a much better return on their ad spend.
Of course, this wouldn’t provide the revenues to YouTube or the ad tech business obtainable by being spammy counterfeits of responsible companies with a lock on the market. That a harmful business model makes a shipload of money does not make it good, in fact quite the reverse.
So, to YouTube we say: you appear to be using a bad lock-in. Disable it, or pay the price
These requirements would oblige AI developers to disclose a summary of all copyrighted material used to train their AI systems. Burdensome and impractical are the right words to describe the proposed rules.
In some cases it would basically come down to providing a summary of half the internet.
Leaving aside the impossibly large volume of material that might need to be summarized, another issue is that it is by no means clear when something is under copyright, making compliance even more infeasible. In any case, as the DisCo post rightly points out, the EU Copyright Directive already provides a legal framework that addresses the issue of training AI systems:
The existing European copyright rules are very simple: developers can copy and analyse vast quantities of data from the internet, as long as the data is publicly available and rights holders do not object to this kind of use. So, rights holders already have the power to decide whether AI developers can use their content or not.
This is a classic case of the copyright industry always wanting more, no matter how much it gets. When the EU Copyright Directive was under discussion, many argued that an EU-wide copyright exception for text and data mining (TDM) and AI in the form of machine learning would be hugely beneficial for the economy and society. But as usual, the copyright world insisted on its right to double dip, and to be paid again if copyright materials were used for mining or machine learning, even if a license had already been obtained to access the material.
As I wrote in a column five years ago, that’s ridiculous, because the right to read is the right to mine. Updated for our AI world, that can be rephrased as “the right to read is the right to train”. By failing to recognize that, the European Parliament has sabotaged its own AI Act. Its amendment to the text will make it far harder for AI companies to thrive in the EU, which will inevitably encourage them to set up shop elsewhere.
If the final text of the AI Act still has this requirement to provide a summary of all copyright material that is used for training, I predict that the EU will become a backwater for AI. That would be a huge loss for the region, because generative AI is widely expected to be one of the most dynamic and important new tech sectors. If that happens, backward-looking copyright dogma will once again have throttled a promising digital future, just as it has done so often in the recent past.
The EU Commission has been pushing client-side scanning for well over a year. This new intrusion into private communications has been pitched as perhaps the only way to prevent the sharing of child sexual abuse material (CSAM).
Mandates proposed by the EU government would have forced communication services to engage in client-side scanning of content. This would apply to every communication or service provider. But it would only negatively affect providers incapable of snooping on private communications because their services are encrypted.
Encryption — especially end-to-end encryption — protects the privacy and security of users. The EU’s pitch said protecting more than the children was paramount, even if it meant sacrificing the privacy and security of millions of EU residents.
Encrypted services would have been unable to comply with the mandate without stripping the client-side end from their end-to-end encryption. So, while it may have been referred to with the legislative euphemism “chat control” by EU lawmakers, the reality of the situation was that this bill — if passed intact — basically would have outlawed E2EE.
Fortunately, there was a lot of pushback. Some of it came from service providers who informed the EU they would no longer offer their services in EU member countries if they were required to undermine the security they provided for their users.
The more unexpected resistance came from EU member countries who similarly saw the gaping security hole this law would create and wanted nothing to do with it. On top of that, the EU government’s own lawyers told the Commission passing this law would mean violating other laws passed by this same governing body.
This pushback was greeted by increasingly nonsensical assertions by the bill’s supporters. In op-eds and public statements, backers insisted everyone else was wrong and/or didn’t care enough about the well-being of children to subject every user of any communication service to additional government surveillance.
That’s what happened on the front end of this push to create a client-side scanning mandate. On the back end, however, the EU government was trying to dupe people into supporting their own surveillance with misleading ads that targeted people most likely to believe any sacrifice of their own was worth making when children were on the (proverbial) line.
That’s the unsettling news being delivered to us by Vas Panagiotopoulos for Wired. A security researcher based in Amsterdam took a long look at apparently misleading ads that began appearing on Twitter as the EU government amped up its push to outlaw encryption.
Danny Mekić was digging into the EU’s “chat control” law when he began seeing disturbing ads on Twitter. These ads featured young women being (apparently) menaced by sinister men, backed by a similarly dark background and soundtrack. The ads displayed some supposed “facts” about the sexual abuse of children and ended with the notice that the ads had been paid for by the EU Commission.
The ads also cited survey results that supposedly said most European citizens supported client-side scanning of content and communications, apparently willing to sacrifice their own privacy and security for the common good.
But Mekić dug deeper and discovered the cited survey wasn’t on the level.
Following closer inspection, he discovered that these findings appeared biased and otherwise flawed. The survey results were gathered by misleading the participants, he claims, which in turn may have misled the recipients of the ads; the conclusion that EU citizens were fine with greater surveillance couldn’t be drawn from the survey, and the findings clashed with those of independentpolls.
This discovery prompted Mekić to dig even deeper. What Mekić found was that the ads were very tightly targeted — so tightly targeted, in fact, that they could not have been deployed in this manner without violating European laws that are aimed to prevent exactly this sort of targeting, i.e. by using “sensitive data” like religious beliefs and political affiliations.
The ads were extremely targeted, meant to find people most likely to be swayed towards the EU Commission’s side, either because the targets never appeared to distrust their respective governments or because their governments had yet to tell the EU Commission to drop its proposed anti-encryption proposal.
Mekić found that the ads were meant to be seen by select targets, such as top ministry officials, while they were concealed from people interested in Julian Assange, Brexit, EU corruption, Eurosceptic politicians (Marine Le Pen, Nigel Farage, Viktor Orban, Giorgia Meloni), the German right-wing populist party AfD, and “anti-Christians.”
Mekić then found out that the ads, which have garnered at least 4 million views, were only displayed in seven EU countries: the Netherlands, Sweden, Belgium, Finland, Slovenia, Portugal, and the Czech Republic.
The countries targeted by the EU Commission ad campaign are, for the most part, supportive of/indifferent to broken encryption, client-side scanning, and expanded surveillance powers. Slovenia (along with Spain, Cyprus, Lithuania, Croatia, and Hungary) were all firmly in favor of bringing an end to end-to-end encryption.
[…]
While we’re accustomed to politicians airing misleading ads during election runs, this is something different. This is the representative government of several nations deliberately targeting countries and residents it apparently thinks might be receptive to its skewed version of the facts, which comes in the form of the presentation of misleading survey results against a backdrop of heavily-implied menace. And that’s on top of seeming violations of privacy laws regarding targeted ads that this same government body created and ratified.
It’s a tacit admission EU proposal backers think they can’t win this thing on its merits. And they can’t. The EU Commission has finally ditched its anti-encryption mandates after months of backlash. For the moment, E2EE survives in Europe. But it’s definitely still under fire. The next exploitable tragedy will bring with it calls to reinstate this part of the “chat control” proposal. It will never go away because far too many governments believe their citizens are obligated to let these governments shoulder-surf whenever they deem it necessary. And about the only thing standing between citizens and that unceasing government desire is end-to-end encryption.
As soon as you read that legislation is ‘for the kids’ be very very wary – as it’s usually for something completely beyond that remit. And this kind of legislation is the installation of Big Brother on every single communications line you use.
YouTube is no longer preventing just a small subset of its userbase from accessing its videos if they have an ad blocker. The platform has gone all out in its fight against the use of add-ons, extensions and programs that prevent it from serving ads to viewers around the world, it confirmed to Engadget. “The use of ad blockers violate YouTube’s Terms of Service,” a spokesperson told us. “We’ve launched a global effort to urge viewers with ad blockers enabled to allow ads on YouTube or try YouTube Premium for an ad free experience. Ads support a diverse ecosystem of creators globally and allow billions to access their favorite content on YouTube.”
YouTube started cracking down on the use of ad blockers earlier this year. It initially showed pop-ups to users telling them that it’s against the website’s TOS, and then it put a timer on those notifications to make sure people read it. By June, it took on a more aggressive approach and warned viewers that they wouldn’t be able to play more than three videos unless they disable their ad blockers. That was a “small experiment” meant to urge users to enable ads or to try YouTube Premium, which the website has now expanded to its entire userbase. Some people can’t even play videos on Microsoft Edge and Firefox browsers even if they don’t have ad blockers, according to Android Police, but we weren’t able to replicate that behavior. [Note – I was!]
People are unsurprisingly unhappy about the development and have taken to social networks like Reddit to air their grievances. If they don’t want to enable ads, after all, the only way they can watch videos with no interruptions is to pay for a YouTube Premium subscription. Indeed, the notification viewers get heavily promotes the subscription service. “Ads allow YouTube to stay free for billions of users worldwide,” it says. But with YouTube Premium, viewers can go ad-free, and “creators can still get paid from [their] subscription.”
Researchers say they have developed a method to remotely track the movement of objects in a room using mirrors and radio waves, in the hope it could one day help monitor nuclear weapons stockpiles.
According to the non-profit org International Campaign to Abolish Nuclear Weapons, nine countries, including Russia, the United States, China, France, the United Kingdom, Pakistan, India, Israel and North Korea collectively own about 12,700 nuclear warheads.
Meanwhile, over 100 nations have signed the United Nations’ Treaty on the Prohibition of Nuclear Weapons, promising to not “develop, test, produce, acquire, possess, stockpile, use or threaten to use” the tools of mass destruction. Tracking signs of secret nuclear weapons development, or changes in existing warhead caches, can help governments identify entities breaking the rules.
A new technique devised by a team of researchers led by the Max Planck Institute for Security and Privacy (MPI-SP) aims to remotely monitor the removal of warheads stored in military bunkers. The scientists installed 20 adjustable mirrors and two antennae to monitor the movement of a blue barrel stored in a shipping container. One antenna emits radio waves that bounce off each mirror to create a unique reflection pattern detected by the other antenna.
The signals provide information on the location of objects in the room. Moving the objects or mirrors will produce a different reflection pattern. Experiments showed that the system was sensitive enough to detect whether the blue barrel had shifted by just a few millimetres. Now, the team reckons that it could be applied to monitor whether nuclear warheads have been removed from stockpiles.
At this point, readers may wonder why this tech is proposed for the job when CCTV, or Wi-Fi location, or any number of other observation techniques could do the same job.
The paper explains that the antenna-and-mirror technique doesn’t require secure communication channels or tamper-resistant sensor hardware. The paper’s authors argue it is also “robust against major physical and computational attacks.”
“Seventy percent of the world’s nuclear weapons are kept in storage for military reserve or awaiting dismantlement,” Sebastien Philippe, co-author of a research paper published in Nature Communications. Philippe is an associate research scholar at the School of Public and International Affairs at Princeton University, explained.
“The presence and number of such weapons at any given site cannot be verified easily via satellite imagery or other means that are unable to see into the storage vaults. Because of the difficulties to monitor them, these 9,000 nuclear weapons are not accounted for under existing nuclear arms control agreements. This new verification technology addresses this long-standing challenge and contributes to future diplomatic efforts that would seek to limit all nuclear weapon types,” he said in a statement.
In practice, officials from and organisation such as UN-led International Atomic Energy Agency, which promotes peaceful uses of nuclear energy, could install the system in a nuclear bunker and measure the radio waves reflecting off its mirrors. The unique fingerprint signal can then be stored in a database.
They could later ask the government controlling the nuclear stockpile to measure the radio wave signal recorded by its detector antenna and compare it to the initial result to check whether any warheads have been moved.
If both measurements are the same, the nuclear weapon stockpile has not been tampered with. But if they’re different, it shows something is afoot. The method is only effective if the initial radio fingerprint detailing the original configuration of the warheads is kept secret, however.
Unfortunately, it’s not quite foolproof, considering adversaries could technically use machine learning algorithms to predict how the positions of the mirrors generate the corresponding radio wave signal detected by the antenna.
“With 20 mirrors, it would take eight weeks for an attacker to decode the underlying mathematical function,” said Johannes Tobisch, co-author of the study and a researcher at the MPI-SP. “Because of the scalability of the system, it’s possible to increase the security factor even more.”
To prevent this, the researchers said that the verifier and prover should agree to send back a radio wave measurement within a short time frame, such as within a minute or so. “Beyond nuclear arms control verification, our inspection system could find application in the financial, information technology, energy, and art sectors,” they concluded in their paper.
“The ability to remotely and securely monitor activities and assets is likely to become more important in a world that is increasingly networked and where physical travel and on-site access may be unnecessary or even discouraged.”
Under the new agreement, 23andMe will provide GSK with one year of access to anonymized DNA data from the approximately 80% of gene-testing customers who have agreed to share their information for research, 23andMe said in a statement Monday. The genetic-testing company will also provide data-analysis services to GSK.
23andMe is best known for its DNA-testing kits that give customers ancestry and health information. But the DNA it collects is also valuable, including for scientific research. With information from more than 14 million customers, the only data sets that rival the size of the 23andMe library belong to Ancestry.com and the Chinese government. The idea for drugmakers is to comb the data for hints about genetic pathways that might be at the root of disease, which could significantly speed up the long, slow process of drug development. GSK and 23andMe have already taken one potential medication to clinical trials: a cancer drug that works to block CD96, a protein that helps modulate the body’s immune responses. It entered that testing phase in four years, compared to an industry average of about seven years. Overall, the partnership between GSK and 23andMe has produced more than 50 new drug targets, according to the statement.
The new agreement changes some components of the collaboration. Any discoveries GSK makes with the 23andMe data will now be solely owned by the British pharmaceutical giant, while the genetic-testing company will be eligible for royalties on some projects. In the past, the two companies pursued new drug targets jointly. GSK’s new deal with 23andMe is also non-exclusive, leaving the genetic-testing company free to license its database to other drugmakers.
So – you paid for a DNA test and it turns out you didn’t think of the privacy aspect at all. Neither did you think up that you gave up your families DNA. Or that you can’t actually change your DNA either. Well done. It’s being spread all over the place. And no, the data is not anonymous – DNA is the most personal information you can give up ever.
Last week, privacy advocate (and very occasionalReg columnist) Alexander Hanff filed a complaint with the Irish Data Protection Commission (DPC) decrying YouTube’s deployment of JavaScript code to detect the use of ad blocking extensions by website visitors.
On October 16, according to the Internet Archives’ Wayback Machine, Google published a support page declaring that “When you block YouTube ads, you violate YouTube’s Terms of Service.”
“If you use ad blockers,” it continues, “we’ll ask you to allow ads on YouTube or sign up for YouTube Premium. If you continue to use ad blockers, we may block your video playback.”
YouTube’s Terms of Service do not explicitly disallow ad blocking extensions, which remain legal in the US [PDF], in Germany, and elsewhere. But the language says users may not “circumvent, disable, fraudulently engage with, or otherwise interfere with any part of the Service” – which probably includes the ads.
Image of ‘Ad blockers are not allowed’ popup – Click to enlarge
YouTube’s open hostility to ad blockers coincides with the recent trial deployment of a popup notice presented to web users who visit the site with an ad-blocking extension in their browser – messaging tested on a limited audience at least as far back as May.
In order to present that popup YouTube needs to run a script, changed at least twice a day, to detect blocking efforts. And that script, Hanff believes, violates the EU’s ePrivacy Directive – because YouTube did not first ask for explicit consent to conduct such browser interrogation.
[…]
Asked how he hopes the Irish DPC will respond, Hanff replied via email, “I would expect the DPC to investigate and issue an enforcement notice to YouTube requiring them to cease and desist these activities without first obtaining consent (as per [Europe’s General Data Protection Regulation (GDPR)] standard) for the deployment of their spyware detection scripts; and further to order YouTube to unban any accounts which have been banned as a result of these detections and to delete any personal data processed unlawfully (see Article 5(1) of GDPR) since they first started to deploy their spyware detection scripts.”
Hanff’s use of strikethrough formatting acknowledges the legal difficulty of using the term “spyware” to refer to YouTube’s ad block detection code. The security industry’s standard defamation defense terminology for such stuff is PUPs, or potentially unwanted programs.
[…]
Hanff’s contention that ad-blocker detection without consent is unlawful in the EU was challenged back in 2016 by the maker of a detection tool called BlockAdblock. The software maker’s argument is that JavaScript code is not stored in the way considered in Article 5(3), which the firm suggests was intended for cookies.
Hanff disagrees, and maintains that “The Commission and the legislators have been very clear that any access to a user’s terminal equipment which is not strictly necessary for the provision of a requested service, requires consent.
“This is also bound by CJEU Case C-673/17 (Planet49) from October 2019 which *all* Member States are legally obligated to comply with, under the [Treaty on the Functioning of the European Union] – there is no room for deviation on this issue,” he elaborated.
“If a script or other digital technology is strictly necessary (technically required to deliver the requested service) then it is exempt from the consent requirements and as such would pose no issue to publishers engaging in legitimate activities which respect fundamental rights under the Charter.
“It is long past time that companies meet their legal obligations for their online services,” insisted Hanff. “This has been law since 2002 and was further clarified in 2009, 2012, and again in 2019 – enough is enough.”
Ever since Apple re-branded as the “Privacy” company several years back, it’s been rolling out features designed to show its commitment to protecting users. Yet while customers might feel safer using an iPhone, there’s already plenty of evidence that Apple’s branding efforts don’t always match the reality of its products. In fact, a lot of its privacy features don’t actually seem to work.
Case in point: new research shows that one of Apple’s proffered privacy tools—a feature that was supposed to anonymize mobile users’ connections to Wifi—is effectively “useless.” In 2020, Apple debuted a feature that, when switched on, was supposed to hide an iPhone user’s media access control—or MAC—address. When a device connects to a WiFi network, it must first send out its MAC address so the network can identify it; when the same MAC address pops up in network after network, it can be used to by network observers to identify and track a specific mobile user’s movements.
Apple’s feature was supposed to provide randomized MAC addresses for users as a way of stop this kind of tracking from happening. But, apparently, a bug in the feature persisted for years that made the feature effectively useless.
According to a new report from Ars Technica, researchers recently tested the feature to see if it actually concealed their MAC addresses, only to find that it didn’t do that at all. Ars writes:
Despite promises that this never-changing address would be hidden and replaced with a private one that was unique to each SSID, Apple devices have continued to display the real one, which in turn got broadcast to every other connected device on the network.
One of the researchers behind the discovery of the vulnerability, Tommy Mysk, told Ars that, from the jump, “this feature was useless because of this bug,” and that, try as they might, he “couldn’t stop the devices from sending these discovery requests, even with a VPN. Even in the Lockdown Mode.”
What Apple’s justification for advertising a feature that just plainly does not work is, I’m not sure. Gizmodo reached out to the company for comment and will update this story if they respond. A recent update, iOS 17.1, apparently patches the problem and ensures that the feature actually works.
I am so frequently confused by companies that sue other companies for making their own sites and services more useful. It happens quite often. And quite often, the lawsuits are questionable CFAA claims against websites that scrape data to provide a better consumer experience, but one that still ultimately benefits the originating site.
Over the last few years various airlines have really been leading the way on this, with Southwest being particularly aggressive in suing companies that help people find Southwest flights to purchase. Unfortunately, many of these lawsuits are succeeding, to the point that a court has literally said that a travel company can’t tell others how much Southwest flights cost.
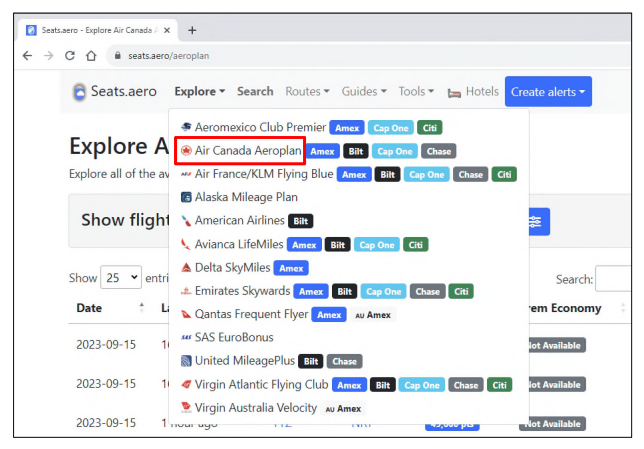
But the latest lawsuit of this nature doesn’t involve Southwest, and is quite possibly the dumbest one. Air Canada has sued the site Seats.aero that helps users figure out the best flights for their frequent flyer miles. Seats.aero is a small operation run by the company with the best name ever: Localhost, meaning that the lawsuit is technically “Air Canada v. Localhost” which sounds almost as dumb as this lawsuit is.
The Air Canada Group brings this action because Mr. Ian Carroll—through Defendant Localhost LLC—created a for-profit website and computer application (or “app”)— both called Seats.aero—that use substantial amounts of data unlawfully scraped from the Air Canada Group’s website and computer systems. In direct violation of the Air Canada Group’s web terms and conditions, Carroll uses automated digital robots (or “bots”) to continuously search for and harvest data from the Air Canada Group’s website and database. His intrusions are frequent and rapacious, causing multiple levels of harm, e.g., placing an immense strain on the Air Canada Group’s computer infrastructure, impairing the integrity and availability of the Air Canada Group’s data, soiling the customer experience with the Air Canada Group, interfering with the Air Canada Group’s business relations with its partners and customers, and diverting the Air Canada Group’s resources to repair the damage. Making matters worse, Carroll uses the Air Canada Group’s federally registered trademarks and logo to mislead people into believing that his site, app, and activities are connected with and/or approved by the real Air Canada Group and lending an air of legitimacy to his site and app. The Air Canada Group has tried to stop Carroll’s activities via a number of technological blocking measures. But each time, he employs subterfuge to fraudulently access and take the data—all the while boasting about his exploits and circumvention online.
Almost nothing in this makes any sense. Having third parties scrape sites for data about prices is… how the internet works. Whining about it is stupid beyond belief. And here, it’s doubly stupid, because anyone who finds a flight via seats.aero is then sent to Air Canada’s own website to book that flight. Air Canada is making money because Carroll’s company is helping people find Air Canada flights they can take.
Why are they mad?
Air Canada’s lawyers also seem technically incompetent. I mean, what the fuck is this?
Through screen scraping, Carroll extracts all of the data displayed on the website, including the text and images.
Carroll also employs the more intrusive API scraping to further feed Defendant’s website.
If the “API scraping” is “more intrusive” than screen scraping, you’re doing your APIs wrong. Is Air Canada saying that its tech team is so incompetent that its API puts more load on the site than scraping? Because, if so, Air Canada should fire its tech team. The whole point of an API is to make it easier for those accessing data from your website without needing to do the more cumbersome process of scraping.
And, yes, this lawsuit really calls into question Air Canada’s tech team and their ability to run a modern website. If your website can’t handle having its flights and prices scraped a few times every day, then you shouldn’t have a website. Get some modern technology, Air Canada:
Defendant’s avaricious data scraping generates frequent and myriad requests to the Air Canada Group’s database—far in excess of what the Air Canada Group’s infrastructure was designed to handle. Its scraping collects a large volume of data, including flight data within a wide date range and across extensive flight origins and destinations—multiple times per day.
Maybe… invest in better infrastructure like basically every other website that can handle some basic scraping? Or, set up your API so it doesn’t fall over when used for normal API things? Because this is embarrassing:
At times, Defendant’s voluminous requests have placed such immense burdens on the Air Canada Group’s infrastructure that it has caused “brownouts.” During a brownout, a website is unresponsive for a period of time because the capacity of requests exceeds the capacity the website was designed to accommodate. During brownouts caused by Defendant’s data scraping, legitimate customers are unable to use or the Air Canada + Aeroplan mobile app, including to search for available rewards, redeem Aeroplan points for the rewards, search for and view reward travel availability, book reward flights, contact Aeroplan customer support, and/or obtain service through the Aeroplan contact center due to the high volume of calls during brownouts.
Air Canada’s lawyers also seem wholly unfamiliar with the concept of nominative fair use for trademarks. If you’re displaying someone’s trademarks for the sake of accurately talking about them, there’s no likelihood of confusion and no concern about the source of the information. Air Canada claiming that this is trademark infringement is ridiculous:
I guarantee that no one using Seats.aero thinks that they’re on Air Canada’s website.
The whole thing is so stupid that it makes me never want to fly Air Canada again. I don’t trust an airline that can’t set up its website/API to handle someone making its flights more attractive to buyers.
But, of course, in these crazy times with the way the CFAA has been interpreted, there’s a decent chance Air Canada could win.
For its part, Carroll says that he and his lawyers have reached out to Air Canada “repeatedly” to try to work with them on how they “retrieve availability information,” and that “Air Canada has ignored these offers.” He also notes that tons of other websites are scraping the very same information, and he has no idea why he’s been singled out. He further notes that he’s always been open to adjusting the frequency of searches and working with the airlines to make sure that his activities don’t burden the website.
But, really, the whole thing is stupid. The only thing that Carroll’s website does is help people buy more flights. It points people to the Air Canada site to buy tickets. It makes people want to fly more on Air Canada.
Why would Air Canada want to stop that other than that it can’t admit that it’s website operations should all be replaced by a more competent team?
This blog has written a number of times about the reaction of creators to generative AI. Legal academic and copyright expert Andres Guadamuz has spotted what may be the first attempt to draw up a new law to regulate generative AI. It comes from French politicians, who have developed something of a habit of bringing in new laws attempting to control digital technology that they rarely understand but definitely dislike.
There are only four articles in the text of the proposal, which are intended to be added as amendments to existing French laws. Despite being short, the proposal contains some impressively bad ideas. The first of these is found in Article 2, which, as Guadamuz summarises, “assigns ownership of the [AI-generated] work (now protected by copyright) to the authors or assignees of the works that enabled the creation of the said artificial work.” Here’s the huge problem with that idea:
How can one determine the author of the works that facilitated the conception of the AI-generated piece? While it might seem straightforward if AI works are viewed as collages or summaries of existing copyrighted works, this is far from the reality. As of now, I’m unaware of any method to extract specific text from ChatGPT or an image from Midjourney and enumerate all the works that contributed to its creation. That’s not how these models operate.
Since there is no way to find out exactly who the creators are whose work helped generate a new piece of AI material using aggregated statistics, Guadamuz suggests that the French lawmakers might want creators to be paid according to their contribution to the training material that went into creating the generative AI system itself. Using his own writings as an example, he calculates what fraction of any given payout he would receive with this approach. For ChatGPT’s output, Guadamuz estimates he might receive 0.00001% of any payout that was made. To give an example, even if the licensing fee for a some hugely popular work generated using AI were €1,000,000, Guadamuz would only receive 10 cents. Most real-life payouts to creators would be vanishingly small.
Article 3 of the French proposal builds on this ridiculous approach by requiring the names of all the creators who contributed to some AI-generated output to be included in that work. But as Guadamuz has already noted, there’s no way to find out exactly whose works have contributed to an output, leaving the only option to include the names of every single creator whose work is present in the training set – potentially millions of names.
Interestingly, Article 4 seems to recognize the payment problem raised above, and offers a way to deal with it. Guadamuz explains:
As it will be not possible to find the author of an AI work (which remember, has copyright and therefore isn’t in the public domain), the law will place a tax on the company that operates the service. So it’s sort of in the public domain, but it’s taxed, and the tax will be paid by OpenAI, Google, Midjourney, StabilityAI, etc. But also by any open source operator and other AI providers (Huggingface, etc). And the tax will be used to fund the collective societies in France… so unless people are willing to join these societies from abroad, they will get nothing, and these bodies will reap the rewards.
In other words, the net effect of the French proposal seems to be to tax the emerging AI giants (mostly US companies) and pay the money to French collecting societies. Guadumuz goes so far as to say: “in my view, this is the real intention of the legislation”. Anyone who thinks this is a good solution might want to read Chapter 7 of Walled Culture the book (free digital versions available), which quotes from a report revealing “a long history of corruption, mismanagement, confiscation of funds, and lack of transparency [by collecting societies] that has deprived artists of the revenues they earned”. Trying to fit generative AI into the straitjacket of an outdated copyright system designed for books is clearly unwise; using it as a pretext for funneling yet more money away from creators and towards collecting societies is just ridiculous.
The Data Privacy Framework (DPF) presents new legal guidance to facilitate personal data sharing between US companies and their counterparts in the EU and the UK. This framework empowers individuals with greater control over their personal data and streamlines business operations by creating common rules around interoperable dataflows. Moreover, the DPF will help enable clear contract terms and business codes of conduct for corporations that collect, use, and transfer personal data across borders.
Any business that collects data related to people in the EU must comply with the EU’s General Data Protection Regulation (GDPR), which is the toughest privacy and security law across the globe. Thus, the DPF helps US corporations avoid potentially hefty fines and penalties by ensuring their data transfers align with GDPR regulations.
Data transfer procedures, which were historically time-consuming and riddled with legal complications, are now faster and more straightforward with the DPF, which allows for more transatlantic dataflows agreed on by US companies and their EU and UK counterparts. On July 10, 2023, the European Commission finalized an adequacy decision that assures the US offers data protection levels similar to the EU’s.
[…]
US companies can register with the DPF through the Department of Commerce DPF website. Companies that previously self-certified compliance with the EU-US Privacy Shield can transition to DPF by recertifying their adherence to DPF principles, including updating privacy policies to reflect any change in procedures and data subject rights that are crucial for this transition. Businesses should develop privacy policies that identify an independent recourse mechanism that can address data protection concerns. To qualify for the DPF the company must fall under the jurisdiction of either the Federal Trade Commission or the US Department of Transportation, though this reach may broaden in the future.
The whole self-certification things seems leaky as a sieve to me… And once data has gone into the US intelligence services you can assume it will go everywhere and there will be no stopping it from the EU side.
Here’s how things went for the world’s most infamous purveyor of facial recognition tech when it came to its dealings with the United Kingdom. In a word: not great.
In addition to supplying its scraped data to known human rights abusers, Clearview was found to have supplied access to a multitude of UK and US entities. At that point (early 2020), it was also making its software available to a number of retailers, suggesting the tool its CEO claimed was instrumental in fighting serious crime (CSAM, terrorism) was just as great at fighting retail theft. For some reason, an anti-human-trafficking charity headed up by author J.K. Rowling was also on the customer list obtained by Buzzfeed.
Clearview’s relationship with the UK government soon soured. In December 2021, the UK government’s Information Commissioner’s Office (ICO) said the company had violated UK privacy laws with its non-consensual scraping of UK residents’ photos and data. That initial declaration from the ICO came with a $23 million fine attached, one that was reduced to a little less than $10 million ($9.4 million) roughly six months later, accompanied by demands Clearview immediately delete all UK resident data in its possession.
This fine was one of several the company managed to obtain from foreign governments. The Italian government — citing EU privacy law violations — levied a $21 million fine. The French government came to the same conclusions and the same penalty, adding another $21 million to Clearview’s European tab.
The facial recognition tech company never bothered to proclaim its innocence after being fined by the UK government. Instead, it simply stated the UK government had no power to enforce this fine because Clearview was a United States company with no physical presence in the United Kingdom.
In addition to engaging in reputational rehab on the UK front, Clearview went to court to challenge the fine levied by the UK government. And it appears to have won this round for the moment, reducing its accounts payable ledger by about $10 million, as Natasha Lomas reports for TechCrunch.
[I]n a ruling issued yesterday its legal challenge to the ICO prevailed on jurisdiction grounds after the tribunal ruled the company’s activities fall outside the jurisdiction of U.K. data protection law owing to an exemption related to foreign law enforcement.
Which is pretty much the argument Clearview made months ago, albeit less elegantly after it was first informed of the fine. The base argument is that Clearview is a US entity providing services to foreign entities and that it’s up to its foreign customers to comply with local laws, rather than Clearview itself.
That argument worked. And it worked because it appears the ICO chose the wrong law to wield against Clearview. The UK’s GDPR does not protect UK residents from actions taken by “competent authorities for law enforcement purposes.” (lol at that entire phrase.) Government customers of Clearview are only subject to the adopted parts of the EU’s Data Protection Act post-Brexit, which means the company’s (alleged) pivot to the public sector puts both its actions — and the actions of its UK law enforcement clients — outside of the reach of the GDPR.
Per the ruling, Clearview argued it’s a foreign company providing its service to “foreign clients, using foreign IP addresses, and in support of the public interest activities of foreign governments and government agencies, in particular in relation to their national security and criminal law enforcement functions.”
That’s enough to get Clearview off the hook. While the GDPR and EU privacy laws have extraterritorial provisions, they also make exceptions for law enforcement and national security interests. GDPR has more exceptions, which made it that much easier for Clearview to walk away from this penalty by claiming it only sold to entities subject to this exception.
Whether or not that’s actually true has yet to be determined. And it might have made more sense for ICO to prosecute this under the parts of EU law the UK government decided to adopt after deciding it no longer wanted to be part of this particular union.
Even if the charges had stuck, it’s unlikely Clearview would ever have paid the fine. According to its CEO and spokespeople, Clearview owes nothing to anyone. Whatever anyone posts publicly is fair game. And if the company wants to hoover up everything on the web that isn’t nailed down, well, that’s a problem for other people to be subjected to, possibly at gunpoint. Until someone can actually make something stick, all they’ve got is bills they can’t collect and a collective GFY from one of the least ethical companies to ever get into the facial recognition business.
It’s pretty much the way of the world: beyond the basic enshittification story that has been so well told over the past year or so about how companies get worse and worse as they get more and more powerful, there’s also the well known concept of successful innovative companies “pulling up the ladder” behind them, using the regulatory process to make it impossible for other companies to follow their own path to success. We’ve talked about this in the sense of political entrepreneurship, which is when the main entrepreneurial effort is not to innovate in newer and better products for customers, but rather using the political system for personal gain and to prevent competitors from havng the same opportunities.
It happens all too frequently. And it’s been happening lately with the big internet companies, which relied on the open internet to become successful, but under massive pressure from regulators (and the media), keep shooting the open internet in the back, each time they can present themselves as “supportive” of some dumb regulatory regime. Facebook did it six years ago by supporting FOSTA wholeheartedly, which was the key tide shift that made the law viable in Congress.
And, now, it appears that Google is going down that same path. There have been hints here and there, such as when it mostly gave up the fight on net neutrality six years ago. However, Google had still appeared to be active in various fights to protect an open internet.
But, last week, Google took a big step towards pulling up the open internet ladder behind it, which got almost no coverage (and what coverage it got was misleading). And, for the life of me, I don’t understand why it chose to do this now. It’s one of the dumbest policy moves I’ve seen Google make in ages, and seems like a complete unforced error.
The “legislative” model is, effectively, California’s Age Appropriate Design Code. Yes, the very law that was just declared unconstitutional just a few weeks before Google basically threw its weight behind the approach. What’s funny is that many, many people have (incorrectly) believed that Google was some sort of legal mastermind behind the NetChoice lawsuits challenging California’s law and other similar laws, when the reality appears to be that Google knows full well that it can handle the requirements of the law, but smaller competitors cannot. Google likes the law. It wants more of them, apparently.
The model includes “age assurance” (which is effectively age verification, though everyone pretends it’s not), greater parental surveillance, and the compliance nightmare of “impact assessments” (we talked about this nonsense in relation to the California law). Again, for many companies this is a good idea. But just because something is a good idea for companies to do does not mean that it should be mandated by law.
But that’s exactly what Google is pushing for here, even as a law that more or less mimics its framework was just found to be unconstitutional. While cynical people will say that maybe Google is supporting these policies hoping that they will continue to be found unconstitutional, I see little evidence to support that. Instead, it really sounds like Google is fully onboard with these kinds of duty of care regulations that will harm smaller competitors, but which Google can handle just fine.
It’s pulling up the ladder behind it.
And yet, the press coverage of this focused on the fact that this was being presented as an “alternative” to a full on ban for kids under 18 to be on social media. The Verge framed this as “Google asks Congress not to ban teens from social media,” leaving out that it was Google asking Congress to basically make it impossible for any site other than the largest, richest companies to be able to allow teens on social media. Same thing with TechCrunch, which framed it as Google lobbying against age verification.
But… it’s not? It’s basically lobbying for age verification, just in the guise of “age assurance,” which is effectively “age verification, but if you’re a smaller company you can get it wrong some undefined amount of time, until someone sues you.” I mean, what’s here is not “lobbying against age verification,” it’s basically saying “here’s how to require age verification.”
A good understanding of user age can help online services offer age-appropriate experiences. That said, any method to determine the age of users across services comes with tradeoffs, such as intruding on privacy interests, requiring more data collection and use, or restricting adult users’ access to important information and services. Where required, age assurance – which can range from declaration to inference and verification – should be risk-based, preserving users’ access to information and services, and respecting their privacy. Where legislation mandates age assurance, it should do so through a workable, interoperable standard that preserves the potential for anonymous or pseudonymous experiences. It should avoid requiring collection or processing of additional personal information, treating all users like children, or impinging on the ability of adults to access information. More data-intrusive methods (such as verification with “hard identifiers” like government IDs) should be limited to high-risk services (e.g., alcohol, gambling, or pornography) or age correction. Moreover, age assurance requirements should permit online services to explore and adapt to improved technological approaches. In particular, requirements should enable new, privacy-protective ways to ensure users are at least the required age before engaging in certain activities. Finally, because age assurance technologies are novel, imperfect, and evolving, requirements should provide reasonable protection from liability for good-faith efforts to develop and implement improved solutions in this space.
Much like Facebook caving on FOSTA, this is Google caving on age verification and other “duty of care” approaches to regulating the way kids have access to the internet. It’s pulling up the ladder behind itself, knowing that it was able to grow without having to take these steps, and making sure that none of the up-and-coming challenges to Google’s position will have the same freedom to do so.
And, for what? So that Google can go to regulators and say “look, we’re not against regulations, here’s our framework”? But Google has smart policy people. They have to know how this plays out in reality. Just as with FOSTA, it completely backfired on Facebook (and the open internet). This approach will do the same.
Not only will these laws inevitably be used against the companies themselves, they’ll also be weaponized and modified by policymakers who will make them even worse and even more dangerous, all while pointing to Google’s “blessing” of this approach as an endorsement.
For years, Google had been somewhat unique in continuing to fight for the open internet long after many other companies were switching over to ladder pulling. There were hints that Google was going down this path in the past, but with this policy framework, the company has now made it clear that it has no intention of being a friend to the open internet any more.
Well, with chrome only support, dns over https and browser privacy sandboxing, Google has been off the do no evil for some time and has been closing off the openness of the web by rebuilding or crushing competition for quite some time
Universal Music has filed a copyright infringement lawsuit against artificial intelligence start-up Anthropic, as the world’s largest music group battles against chatbots that churn out its artists’ lyrics.
Universal and two other music companies allege that Anthropic scrapes their songs without permission and uses them to generate “identical or nearly identical copies of those lyrics” via Claude, its rival to ChatGPT.
When Claude is asked for lyrics to the song “I Will Survive” by Gloria Gaynor, for example, it responds with “a nearly word-for-word copy of those lyrics,” Universal, Concord, and ABKCO said in a filing with a US court in Nashville, Tennessee.
“This copyrighted material is not free for the taking simply because it can be found on the Internet,” the music companies said, while claiming that Anthropic had “never even attempted” to license their copyrighted work.
[…]
Universal earlier this year asked Spotify and other streaming services to cut off access to its music catalogue for developers using it to train AI technology.
So don’t think about memorising or even listening to copyrighted material from them because apparently they will come after you with the mighty and crazy arm of the law!
Credit bureau company, Equifax, has been fined US$13.4 million by The Financial Conduct Authority (FCA), a UK financial watchdog, following its involvement in “one of the largest” data breaches ever.
This cyber security incident took place in 2017 and saw Equifax’s US-based parent company, Equifax Inc., suffer a data breach that saw the personal data of up to 147.9 million customers accessed by malicious actors during the hack. The FCA also revealed that, as this data was stored in company servers in the US, the hack also exposed the personal data of 13.8 million UK customers.
The data accessed during the hack included Equifax membership login details, customer names, dates of birth, partial credit card details and addresses.
According the FCA, the cyber attack and subsequent data breach was “entirely preventable” and exposed UK customers to financial crime.
“There were known weaknesses in Equifax Inc’s data security systems and Equifax failed to take appropriate action in response to protect UK customer data,” the FCA explained.
The authority also noted that the UK arm of Equifax was not made aware that malicious actors had been accessed during the hack until six weeks after the cyber security incident was discovered by Equifax Inc.
The company was fined $60,727 by the British Information Commissioner’s Office (ICO) relating to the data breach in 2018.
On October 13th, Equifax stated that it had fully cooperated with the FCA during the investigation, which has been extensive. The FCA also said that the fine levelled at Equifax Inc had been reduced following the company’s agreement to cooperate with the watchdog and resolve the cyber attack.
Patricio Remon, president for Europe at Equifax, said that since the cyber attack against Equifax in 2017, the company has “invested over $1.5 billion in a security and technology transformation”. Remon also said that “few companies have invested more time and resources than Equifax to ensure that consumers’ information is protected”.