The DMA defines new rules for large online platforms (“gatekeepers”). They now have to:
ensure that unsubscribing from core platform services is just as easy as subscribing
ensure that the basic functionalities of instant messaging services are interoperable, i.e. enable users to exchange messages, send voice messages or files across messaging apps
give business users access to their marketing or advertising performance data on the platform
inform the European Commission of their acquisitions and mergers
But they can no longer:
rank their own products or services higher than those of others (self-preferencing)
pre-install certain apps or software, or prevent users from easily un-installing these apps or software
require the most important software (e.g. web browsers) to be installed by default when installing an operating system
prevent developers from using third-party payment platforms for app sales
reuse private data collected during a service for the purposes of another service
If a large online platform is identified as a gatekeeper, it will have to comply with the rules of the DMA within six months.
If a gatekeeper violates the rules laid down in the DMA, it risks a fine of up to 10% of its total worldwide turnover. For a repeat offence, a fine of up to 20% of its worldwide turnover may be imposed.
If a gatekeeper systematically fails to comply with the DMA, i.e. it violates the rules at least threetimes in eightyears, the European Commission can open a market investigation and, if necessary, impose behavioural or structural remedies.
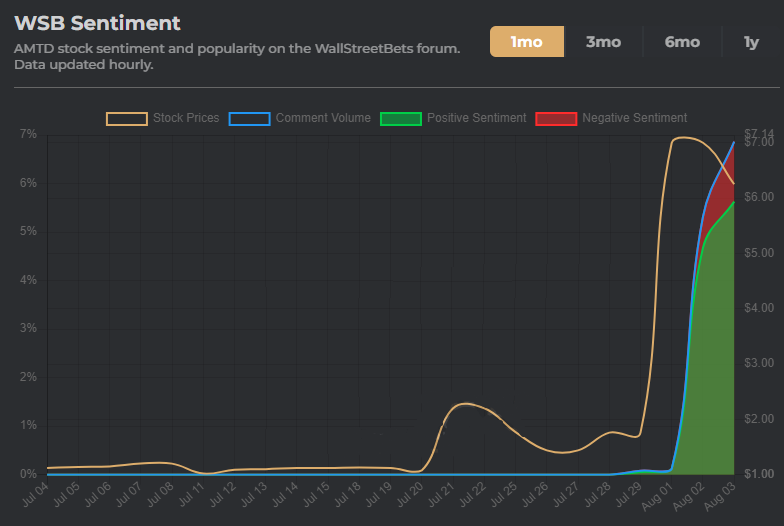
HKD, a spinoff IPO with 51 employees within the space of a few days had a stock price explosion up to around $2555 per stock from around $75 starting on 28th July. No buy button was disabled (as was the case with Gamestop / $GME) and within a few days the rug was pulled on 3rd of August leading to a (current) value of around $1000. This is around the time of the very confusing $GME stock dividend split (splividend) which has caused chaos with brokers not issuing the split shares or dividend to clients with $GME stock. Redditors were caught completely flat footed by this, but the media has been blaming Reddit with headlines like the following
Redditors are affronted that this stock is being treated differently from $GME – a stock that was being short squeezed for no reason apart from monetary gains for huge institutional investors such as Ken Griffin and Citadel and many more.
TLDR: They took over an insurer in HK (Hong Kong) when China took over. They also bought up a couple insurers in Singapore. They may offer some fintech services and possibly a small media platform for some SE Asia internet celebs. Their “SpiderNet” is, according to them, their most profitable system. It appears to just be a business network that you have to pay to be a part of. It all sounds like a corporate crime syndicate straight out of a comic book.
They mention a “controlling shareholder” a few times, which I assume is AMTD Idea Group, a holding company. They’ve been investigated for some very fradulastic crap, which I will be writing up next. (https://hindenburgresearch.com/ebang/)
This stock just IPO’d, is based in a foreign country, and has run 30,000% in two weeks on very low volume. Translation: Please do not read this and conclude, “Wow, what a great stock that I should definitely buy!” — That is absolutely NOT what we’re saying here
the website’s explanation of SpiderNet is extremely vague.
What can be gleaned from the website is:
AMTD provides investment banking and asset management services to clients on an international basis
AMTD Digital raised $125M in its New York IPO — the largest listing by a Chinese company in 2022
It owns the SpiderNet platform
That’s really all the website explains. After digging through a few press releases, we were able to determine that the SpiderNet platform intends to provide capital and technology to digital startups, as well as provide networking services to other digital startups. In turn, SpiderNet collects a fee from its members, which is where it gets almost all of its revenue.
In short: AMTD Digital is a Hong Kong based fintech play which essentially provides loans and services to startups in exchange for fees.
Will Cathcart, who has been at parent company Meta for more than 12 years and head of WhatsApp since 2019, told the BBC that the popular communications service wouldn’t downgrade or bypass its end-to-end encryption (EE2E) just for British snoops, saying it would be “foolish” to do so and that WhatsApp needs to offer a consistent set of standards around the globe.
“If we had to lower security for the world, to accommodate the requirement in one country, that … would be very foolish for us to accept, making our product less desirable to 98 percent of our users because of the requirements from 2 percent,” Cathcart told the broadcaster. “What’s being proposed is that we – either directly or indirectly through software – read everyone’s messages. I don’t think people want that.”
Strong EE2E ensures that only the intended sender and receiver of a message can read it, and not even the provider of the communications channel nor anyone eavesdropping on the encrypted chatter. The UK government is proposing that app builders add an automated AI-powered scanner in the pipeline – ideally in the client app – to detect and report illegal content, in this case child sex abuse material (CSAM).
When activated, repair mode prevents a range of behaviors – from casual snooping to outright lifting of personal data – by blocking access to photos, messages, and account information.
The mode provides technicians with the access they require to make a fix, including the apps a user employs. But repairers won’t see user data in apps, so content like photos, texts and emails remains secure.
When users enable repair mode their device reboots. To exit, the user reboots again after logging in their normal way and turning the setting off.
Samsung said it is rolling out repair mode via software update, initially on the Galaxy S21 series within South Korea, with more models, and perhaps locations, getting the functionality over time.
Samsung has not explained how the feature works. Android devices already offer the chance to establish accounts for different users, so perhaps Samsung has created a role for repair technicians and made that easier to access.
Most repair technicians won’t want to view or steal a customer’s personal data – but it does happen.
Apple was forced to pay millions last year after two iPhone repair contractors allegedly stole and posted a woman’s nudes to the internet. That fiasco was in no way an isolated incident. In 2019 a Genius Bar employee allegedly texted himself explicit images taken from an iPhone he repaired and was subsequently fired.
Over the weekend, the Indonesian government began the task of blocking any website or service that had failed to register as part of new “internet control” laws. That ended up being a lot, including everything from Steam to the Epic Games Store to Nintendo Online to EA and Ubisoft’s platforms.
Indonesia’s Ministry of Communication and Information Technology (Kominfo) took the steps after the introduction of strict new laws, which the government says is part of a crackdown on anything appearing online that is “deemed unlawful,” and which would require any online service platform or provider hosting any such “unlawful” content to remove it within 24 hours (or four if it is deemed to be “urgent”).
In order to abide by those laws, international companies operating in Indonesia needed to have signed up by the weekend, and unsurprisingly given the sweeping powers at play, many have chosen not to, at least for now. As a response, non-participating services have been blocked to Indonesian IPs, which means alongside wider, more mainstream companies like PayPal and Yahoo, a host of gaming platforms have also been cut off.
While PayPal was temporarily reinstated (in order to allow customers to get their money off the platform), the gaming stores and platforms have remained dark since the weekend (the new law’s registration deadline passed on July 27).
As Global Voices sums up, these laws have been opposed both within and outside of Indonesia since they were first announced:
The mandatory registration of private electronic systems operators (ESOs) is stipulated in the Ministerial Regulation 5 (MR5) issued in December 2020. Its amended version, Ministerial Regulation 10 (MR10), was released in May 2021.
Both MR5 and MR10 have been consistently opposed by the media, civil society groups, and human rights advocates for containing provisions that pose a threat to freedom of expression.
MR5 is deeply problematic, granting government authorities overly broad powers to regulate online content, access user data, and penalize companies that fail to comply…Ministerial Regulation 5 is a human rights disaster that will devastate freedom of expression in Indonesia, and should not be used in its current form.
While this isn’t a market that’s normally in the headlines, this is important news, because with its large population (at 270 million it’s the fourth most-populous nation on Earth) Indonesia is a huge market for online services. As The Diplomatpoints out, “Indonesia remains one of the largest internet markets in the world, with the third-largest population of Facebook users and also comes in the top 10 for users of YouTube, TikTok, Twitter, Instagram, and WhatsApp.”
None of the services currently affected are banned; they’re technically just restricted until either they sign up to Kominfo or the law is modified (or repealed). Some of the companies that have signed up include Google, Roblox and Riot Games (League of Legends, Valorant). And while direct access to services like Steam are currently not available, Indonesian gamers are already reportedly getting around this by using a VPN.
Twitter has published its 20th transparency report, and the details still aren’t reassuring to those concerned about abuses of personal info. The social network saw “record highs” in the number of account data requests during the July-December 2021 reporting period, with 47,572 legal demands on 198,931 accounts. The media in particular faced much more pressure. Government demands for data from verified news outlets and journalists surged 103 percent compared to the last report, with 349 accounts under scrutiny.
The largest slice of requests targeting the news industry came from India (114), followed by Turkey (78) and Russia (55). Governments succeeded in withholding 17 tweets.
As in the past, US demands represented a disproportionately large chunk of the overall volume. The country accounted for 20 percent of all worldwide account info requests, and those requests covered 39 percent of all specified accounts. Russia is still the second-largest requester with 18 percent of volume, even if its demands dipped 20 percent during the six-month timeframe.
The company said it was still denying or limiting access to info when possible. It denied 31 percent of US data requests, and either narrowed or shut down 60 percent of global demands. Twitter also opposed 29 civil attempts to identify anonymous US users, citing First Amendment reasons. It sued in two of those cases, and has so far had success with one of those suits. There hasn’t been much success in reporting on national security-related requests in the US, however, and Twitter is still hoping to win an appeal that would let it share more details.
A Russian court fined Google $374 million on Monday for its failure to remove prohibited content, according to the country’s internet watchdog Roskomnadzor.
The Tagansky District Court of Moscow took exception to YouTube content it claimed contained “fakes about the course of a special military operation in Ukraine” and discredited Russia’s armed forces. The court also claimed some material promoted extremism and/or terrorism. Google also stands convicted an “indifferent attitude to the life and health of minors” that the court feels are worthy of protest by Russian citizens.
The court also alleged Google systemically violated Russian law.
As punishment, Google users will receive warnings of the company’s alleged misdeeds, and won’t be permitted to buy ads tied to Google Search results or on YouTube.
Investigators raised alarm bells when they learned Homeland Security bureaus were buying phone location data to effectively bypass the Fourth Amendment requirement for a search warrant, and now it’s clearer just how extensive those purchases were. TechCrunchnotes the American Civil Liberties Union has obtained records linking Customs and Border Protection, Immigration and Customs Enforcement and other DHS divisions to purchases of roughly 336,000 phone location points from the data broker Venntel. The info represents just a “small subset” of raw data from the southwestern US, and includes a burst of 113,654 points collected over just three days in 2018.
The dataset, delivered through a Freedom of Information Act request, also outlines the agencies’ attempts to justify the bulk data purchases. Officials maintained that users voluntarily offered the data, and that it included no personally identifying information. As TechCrunch explains, though, that’s not necessarily accurate. Phone owners aren’t necessarily aware they opted in to location sharing, and likely didn’t realize the government was buying that data. Moreover, the data was still tied to specific devices — it wouldn’t have been difficult for agents to link positions to individuals.
Some Homeland Security workers expressed internal concerns about the location data. One senior director warned that the Office of Science and Technology bought Venntel info without getting a necessaryPrivacy Threshold Assessment. At one point, the department even halted all projects using Venntel data after learning that key legal and privacy questions had gone unanswered.
More details could be forthcoming, as Homeland Security is still expected to provide more documents in response to the FOIA request. We’ve asked Homeland Security and Venntel for comment. However, the ACLU report might fuel legislative efforts to ban these kinds of data purchases, including the Senate’s bipartisan Fourth Amendment is Not For Sale Act as well as the more recently introduced Health and Location Data Protection Act.
A proposed class-action lawsuit filed on behalf of payment card issuers accuses Apple of illegally profiting from Apple Pay and breaking antitrust laws. Iowa’s Affinity Credit Union is listed as the plaintiff in the complaint, filed today in the US District Court for the Northern District of California. The lawsuit alleges that by restricting contactless payments on iOS devices to Apple Pay and charging payment card issuers fees to use the mobile wallet, the iPhone maker is engaging in anti-competitive behavior.
While Android users have options for contactless mobile wallets, iOS users can only use tap-to-pay technology through Apple Pay. In other words, while iPhone users can download the Google Pay app, they can’t use it to make contactless payments in stores. Android doesn’t charge payment card issuers for use of any supported mobile wallet. But it’s a different story for Apple Pay, which charges card issuers a 0.15% fee on credit transactions and half of a cent on debit transactions. These fees have brought in up to $1 billion annually for Apple, the lawsuit alleges.
“In the Android ecosystem, where multiple digital wallets compete, there are no issuer fees whatsoever, ” said the complaint. “The upshot is that card issuers pay a reported $1 billion annually in fees on Apple Pay and $0 for accessing functionally identical Android wallets. If Apple faced competition, it could not sustain these substantial fees.”
The suit alleges that by restricting iOS users to only Apple Pay for contactless payments, Apple is blocking competing mobile wallets from the market. Payment card issuers are essentially forced to pay Apple’s transaction fees if they want to offer their service to iPhone users.
Apple is facing a similar challenge over its payment system in the EU, where an antitrust commission in May said that the tech giant is illegally blocking third-party developers from enabling contactless payments. Apple has denied the EU’s allegations, arguing that giving third-party developers access would be a security risk. This is an argument that Apple has used before as a reason why it doesn’t open up its platform, such as in the case of third-party app stores.
Engadget has reached out to Apple for comment on the lawsuit and will update if we hear back.
While we were just discussing how everyone occasionally gets reminded that for many digital goods these days you simply don’t actually own what you’ve bought, all thanks to Sony disappearing a bunch of purchased movies and shows from its PlayStation platform, this conversation has been going on for a long, long time. Whereas the expectation by many people is that buying a digital good carries similar ownership rights as it would a physical good, instead there are discussions of “licensing” buried in the Ts and Cs that almost nobody reads. The end result is a massive disconnect between what people think they’re paying for and what they actually are paying for.
Take Ubisoft DLC for instance. Lots of people bought DLC for titles like Assassin’s Creed 3 or Far Cry 3 for the PC versions of those games… and recently found out that all that purchased DLC is simply going away with Ubisoft shutting game servers down.
According to Ubisoft’s announcement, “the installation and access to downloadable content (DLC) will be unavailable” on the PC versions of the following games as of September 1, 2022:
Assassin’s Creed 3 Assassin’s Creed: Brotherhood Driver San Francisco Far Cry 3 Prince of Persia: The Forgotten Sands Silent Hunter 5
DLC for the console versions of these games (which is verified through the console platform stores and not Ubisoft’s UPlay platform) will be unaffected, when applicable. Assassin’s Creed III and Far Cry 3 are also available on PC in remastered re-releases that will not be affected by this server shutdown (though the remastered “Classic Edition” of Far Cry 3 is currently unavailable for purchase from Ubisoft’s own website).
A notable addition to all of this is that the full version of Assassin’s Creed Liberation HD was on sale merely days ago on Steam’s Summer Sale, but that title is going to disappear from Steam entirely on September 1st as well. Read that again. The public bought a game title on Steam for 75% off, thinking it was a great deal, only to subsequently learn that they have 60 days to play the damned thing before it becomes unplayable.
This is not tenable. The consumer can only be jerked around so much before a clapback occurs and losing purchased assets based on the whim of the company that sold them isn’t going to be tolerated forever. And while I’m loathe to be one of the “there should be a law!” guys, well, there should be legal ramifications for this sort of thing. There are other options out there that would not remove purchased items from people, be it local installations, allowing fans in the public to host their own servers, etc.
Instead, Ubisoft appears to be joining a list of companies that believes it can sell you something and then take it away, all while including that same something in some bundled release afterwards.
Ring is rejecting the request of a U.S. senator to introduce privacy-enhancing changes to its flagship doorbell video camera after product testing showed the device capable of recording conversations well beyond the doorsteps of its many millions of customers. Security and privacy experts expressed alarm at the quality of the distant recordings, raising concerns about the potential for blackmail, stalking, and other forms of invasion
In a letter to the company last month, Sen. Ed Markey, a Democrat of Massachusetts, said Ring was capturing “significant amounts of audio on private and public property adjacent to dwellings with Ring doorbells,” putting the right to “assemble, move, and converse without being tracked” at risk.
Markey did not asked the company to adjust the range of the device, but adjust the doorbell’s settings so audio wouldn’t be recorded by default. Ring, which was acquired by retail giant Amazon in 2018, rejected the idea, arguing that doing so would be a “negative experience” for customers, who might easily get confused by the settings “in an emergency situation.” What’s more, Ring appeared to reject a request never to link the devices to voice recognition software, offering only that it hasn’t done so thus far.
Experts such as Matthew Guariglia, a policy analyst at the Electronic Frontier Foundation, have said the device is particularly harmful to the privacy of individuals who live in close quarters — think apartment buildings and condos — where they may be unknowingly recorded the moment they open their doors.
Ring, the maker of internet-connected video doorbells and security cameras, said in its latest transparency report that it turned over a record amount of doorbell footage and other information to U.S. authorities last year.
The Amazon-owned company said in two biannual reports covering 2021 that it received 3,147 legal demands, an increase of about 65% on the year earlier, up from about 1,900 legal demands in 2020.
More than 85% of the legal demands processed were by way of court-issued search warrants, allowing Ring to turn over both information about a Ring user and video footage from those accounts. Ring said it turned over user content in response to about four out of 10 demands it received during the year.
Transparency reports allow U.S. companies to disclose the number of legal law orders they are given over a particular time period, often six-months or a year. But Ring has been criticized for having unusually cozy relationships with about 2,200 police departments around the United States, latest figures show, allowing police to request video doorbell camera footage from homeowners.
Ring said it also notified 648 users during the year that their user information had been requested by law enforcement. According to its law enforcement guidelines, Ring notifies users before disclosing their user information, such as name, address, email address and billing information, unless it is prohibited by way of a secrecy order.
In a new breakout, Ring also revealed it received 2,774 preservation orders, which allow police departments and law enforcement agencies to ask Amazon — not demand — to preserve a user’s account for up to six months to allow the requesting agency to gather enough information to a court-issued order, such as a search warrant.
Amazon executive Brian Huseman told lawmakers in a letter published Wednesday that Ring shared doorbell footage at least 11 times with U.S. authorities so far in 2022 without the consent of the device’s owner, reports Politico. According to the letter, Amazon said it “made a good-faith determination that there was an imminent danger of death or serious physical injury to a person requiring disclosure of information without delay.” Under emergency disclosure orders, companies can respond with data when a requesting agency doesn’t have the time to obtain a court order.
Ring has not yet revealed how many times it has disclosed user data under emergency circumstances in previous years, including its most recent transparency report.
A data leak from ride-sharing app Uber revealed activities allegedly geared to avoid regulation and law enforcement – including a “kill switch” that would remotely cut computer access to servers at its headquarters in San Francisco in case of a raid – according to weekend media.
The leak was provided to The Guardian and shared with the nonprofit International Consortium of Investigative Journalists (ICIJ) which helped work though the 124,000 records, which include 83,000 emails, iMessages and WhatsApp exchanges.
The records detail internal conversations within Uber, plus interactions between Uber executives and government officials. The trove contains documents detailing interactions with 30 countries and cover the period 2013 to 2017, when Uber was on the rise and confronting pushback from both regulators and the taxi industry.
The 18.7GB cache reveals that the kill switch used to block authorities from probing Uber’s IT systems – which was already known to a lesser extent – was actually deployed at least 12 times in France, the Netherlands, Belgium, India, Hungary and Romania.
The first instances known of the kill switch being used were in late 2014 in France during two separate raids. A November raid took only 13 minutes between email instructing the action to an IT engineer in Denmark and access being cut.
Emails show the kill switch was used at the command of top-level executives, including none other than former CEO Travis Kalanick, as well as legal staff. Both execs and legal staff were often copied in to emails instructing access cuts.
The kill switch, known internally as Ripley, was used in conjunction with a remote-control program called Casper that cut network access after devices were confiscated by authorities. Because Uber was fond of these justice-obstructing programs and their code names, there was also of course Greyball, revealed in 2017, which blocked cops from booking cabs, lest they were interested in busting unregulated drivers.
Uber learned to predict and prepare for raids, and even issued a manual to employees containing 66 bullet points on how to respond. Titled “Dawn Raid Manual”, it instructed employees to stall by escorting regulators to meeting rooms without files and never to leave them alone.
Employees were also advised to “play dumb” as systems severed their connections to the company’s main IT systems whenever police searched their equipment, as documented in a text exchange between former EMEA head of public policy Mark McGann and current global head of sustainability Thibaud Simphal.
The trove of files goes beyond the technical systems in place to stymie investigations. It also details lobbying efforts, close relationships between execs and public officials including France’s then-economy minister Emmanuel Macron, use of Bermuda as a tax haven, public relations efforts to use violence against its drivers to garner public sympathy, and more.
Amazon (AMZN.O) has offered to share marketplace data with sellers and boost the visibility of rival products on its platform, trying to persuade EU antitrust regulators to close their investigations without a fine by the end of the year, people familiar with the matter said.
The world’s largest online retailer is hoping its concessions will stave off a potential European Union fine that could be as much as 10% of its global turnover, Reuters reported last year. read more
The European Commission in 2020 charged Amazon with using its size, power and data to push its own products and gain an unfair advantage over rival merchants that sell on its online platform.
It also launched an investigation into Amazon’s possible preferential treatment of its own retail offers and those of marketplace sellers that use its logistics and delivery services.
Amazon’s process for choosing which retailer appears in the “buy box” on its website and which generates the bulk of its sales also came under the spotlight.
Amazon has now proposed to allow sellers access to some marketplace data while its commercial arm will not be able to use seller data collected by its retail unit, the people said.
The company will also create a second buy box for rival products in the event an Amazon product appears in the first buy box, the people said.
No way that this is enough. A marketplace owner has no business offering products on their own marketplace at all. That’s always going to be unfair competition. It also fails to address many of the other monopoly problems, like forcing sellers to exclusively use Amazon or downgrading their search results, forcing sellers to use the Amazon delivery options as well as forcing other delivery parties out of business by delivering under cost price.
The Cyberspace Administration of China’s (CAC) policy was first floated in October 2021 and requires businesses that transfer data offshore to conduct a security review. The requirements kick in when an organization transfers data describing more than 100,000 individuals, or information about critical infrastructure – including that related to communications, finance and transportation. Sensitive data such as fingerprints also trigger the requirement, at a threshold of 10,000 sets of prints.
A Thursday announcement added a detail to the policy: the cutoff date after which the CAC will start counting towards the 100,000 and 10,000 thresholds. Oddly, that date is January 1 … of 2021.
A state official explained in Chinese state-owned media on Thursday that the efforts were necessary due to the digital economy expanding cross-border data activities, and that differences in international legal systems have increased data export security risks, thereby affecting national security and social interest.
The official detailed that the security review should occur prior to signing a contract that includes exporting data overseas. Any approved data export will be valid for two years, at which point the entity must apply again.
Michael E. Karpeles, Program Lead on OpenLibrary.org at the Internet Archive, spotted an interesting blog post by Michael Kozlowski, the editor-in-chief of Good e-Reader. It concerns Amazon and its audiobook division, Audible:
Amazon owned Audible ceased selling individual audiobooks through their Android app from Google Play a couple of weeks ago. This will prevent anyone from buying audio titles individually. However, Audible still sells subscriptions through the app (…)
Karpeles points out that this is yet another straw in the wind indicating that the ownership of digital goods is being replaced with a rental model. He wrote a post last year exploring the broader implications, using Netflix as an example:
What content landlords like Netflix are trying to do now is eliminate our “purchase” option entirely. Without it, renting become the only option and they are thus free to arbitrarily hike up rental fees , which we have to pay over and over again without us getting any of these aforementioned rights and freedoms. It’s a classic example of getting less for more.
He goes on to underline four extremely serious consequences of this shift. One is the end of “forever access”. If the company adopting the rental model goes out of business, customers lose access to everything they were paying for. With the ownership of goods, even if the supplier goes bankrupt, you still have the product they sold to you.
Secondly, the rental model effectively means the end of the public domain for material offered in that way. In theory, books, music, films and the rest that are under copyright should enter the public domain after a certain time – typically around a century after they first appeared. But when these digital goods are offered using the rental model, they usually come wrapped up in digital locks – digital rights management (DRM) – to prevent people exiting from the rental model by making a personal copy. That means that even if the company offering the digital goods is still around when the copyright expires, this content will remain locked-away even when it enters the public domain because it is illegal under copyright laws like the US DMCA and EU Information Society Directive to circumvent those locks.
Thirdly, Karpeles notes, the rental model means the end of personal digital freedom in this sphere. Since you access everything through the service provider, the latter knows what you are doing with the rented material and when. How much it chooses to spy on you will depend on the company, but you probably won’t know unless you live somewhere like the EU where you can make a request to the company for the personal data that it holds about you.
Finally, and perhaps least obviously, it means the end of the library model that has served us so well for hundreds of years. Increasingly, libraries are unable to buy copies of ebooks outright, but must rent them. This means that they must follow the strict licensing conditions imposed by publishers on how those ebooks are lent out by the library. For example, some publishers license ebooks for a set period of time – typically a year or two – with no guarantee that renewal will be possible at the end of that time. Others have adopted a metered approach that counts how many times an ebook is lent out, and blocks access after a preset number. Karpeles writes:
Looking to the future, as more books become only available for lease as eBooks, I see no clear option which allows libraries to sustainably serve their important roles as reliable, long-term public access repositories of cultural heritage and human knowledge. It used to be the case that a library would purchase a book once and it would serve the public for decades. Instead, now at the end of each year, a library’s eBooks simply vanish unless libraries are able to find enough quarters to re-feed the meter.
The option to own new digital goods or to access the digital holdings of public libraries may not be available much longer – enjoy them while you can.
LIBE committee member and Pirate Party MEP Patrick Breyer said that during the meeting last week, the committee discovered that the UK – and three EU member states, though their identities were not revealed – had already signed up to reintroduce US visa requirements which grant access to police biometric databases.
In the UK, the Home Office declined the opportunity to deny it was signing up for the scheme. A spokesperson said: “The UK has a long-standing and close partnership with the USA which includes sharing data for specific purposes. We are in regular discussion with them on new proposals or initiatives to improve public safety and enable legitimate travel.”
Under UK law the police can retain an individual’s DNA profile and fingerprint record for up to three years from the date the samples were taken, even if the individual was arrested but not charged, provided the Biometrics Commissioner agrees. Police can also apply for a two-year extension. The same applies to those charged, but not convicted.
According to reports, the US Enhanced Border Security Partnership (EBSP) initiative will be voluntary initially but is set to become mandatory under the US Visa Waiver Program (VWP), which allows visa-free entry into the United States for up to 90 days, by 2027.
MEP Breyer said that when asked exactly what data the US wanted to tap into, the answer was as much as possible. When asked what would happen at US borders if a traveler was known to the police in participating states, it was said that this would be decided by the US immigration officer on a case-by-case basis.
[…]
“If necessary, the visa waiver program must be terminated by Europe as well. Millions of innocent Europeans are listed in police databases and could be exposed to completely disproportionate reactions in the USA.
“The US lacks adequate data and fundamental rights protection. Providing personal data to the US exposes our citizens… to the risk of arbitrary detention and false suspicion, with possible dire consequences, in the course of the US ‘war on terror’. We must protect our citizens from these practices,” Breyer said.
[…] Mickey Mouse will enter the public domain in the year 2024, almost 95 years after his creation on 1 October 1928 – the length of time after which the copyright on an anonymous or pseudo-anonymous body of artistic work expires.
Daniel Mayeda is the associate director of the Documentary Film Legal Clinic at UCLA School of Law, as well as a longtime media and entertainment lawyer. He said the copyright expiration does not come without limitations.
“You can use the Mickey Mouse character as it was originally created to create your own Mickey Mouse stories or stories with this character. But if you do so in a way that people will think of Disney – which is kind of likely because they have been investing in this character for so long – then in theory, Disney could say you violated my trademark.”
[…]
According to the National Museum of American History: “Over the years, Mickey Mouse has gone through several transformations to his physical appearance and personality. In his early years, the impish and mischievous Mickey looked more rat-like, with a long pointy nose, black eyes, a smallish body with spindly legs and a long tail.”
While this first rat-like iteration of Mickey will be stripped of its copyright, Mayeda said Disney retains its copyright on any subsequent variations in other films or artwork until they reach the 95-year mark.
[…]
Honey-loving bear Winnie the Pooh from the Hundred-acre Woods and most of his animal friends entered public domain in January this year and some have wasted no time in capitalizing on the beloved characters.
Actor Ryan Reynolds made a playful nod to the now free-to-use Winnie the Pooh in a Mint Mobile commercial. In the advertisement, Reynolds reads a children’s book about ‘Winnie the Screwed,’ a bear with a costly phone bill.
[…] Pooh and his close pal Piglet are now the stars of Winnie the Pooh: Blood and Honey, a soon-to-be released horror film, written and directed by Rhys Waterfield, that sees the two go on a bloody rampage of killing after being abandoned by their old friend, Christopher Robin.
[…]
“Copyrights are time-limited,” Mayeda said. “Trademarks are not. So Disney could have a trademark essentially in perpetuity, as long as they keep using various things as they’re trademarked, whether they’re words, phrases, characters or whatever.”
Disney may still maintain trademarks on certain catchphrases or signature outfits worn by the characters, such as Pooh’s red shirt, which Waterfield intentionally avoided using in his movie.
[…]
The Walt Disney Company has a long history with US copyright law. Suzanne Wilson, once deputy general counsel for the Walt Disney Company for nearly a decade, now heads the US Copyright Office, underscoring the company’s relationship with the government.
In yetanotherexample of T-Mobile being The Worst with its customer’s data, the company announced a new money-making scheme this week: selling its customers’ app download data and web browsing history to advertisers.
The package of data is part of the company’s new “App Insights” adtech product that was in beta for the last year but formally rolled out this week. According to AdExchanger, which first reported news of the announcement from the Cannes Festival, the new product will let marketers track and target T-Mobile customers based on the apps they’ve downloaded and their “engagement patterns”—meaning when or how
These same “patterns” also include the types of domains a person visits in their mobile web browser. All of this data gets bundled up into what the company calls “personas,” which let marketers microtarget someone by their phone habits. One example that T-Mobile’s head of ad products, Jess Zhu, told AdExchanger was that a person with a human resources app on their phone who also tends to visit, say, Expedia’s website, might be grouped as a “business traveler.” The company noted that there’s no personas built on “gender or cultural identity”—so a person who visits a lot of, say, Christian websites and has a Bible app or two installed won’t be profiled based on that.
“App Insights transforms this data into actionable insights. Marketers can see app usage, growth, and retention and compare activity between brands and product categories,” a T-Mobile statement read.
T-Mobile (and Sprint, by association) certainly aren’t the only carriers pawning off this data; as Ars Technica first noted last year, Verizon overrode customer’s privacy preferences to sell off their browsing and app-usage data. And while AT&T had initially planned to sell access to similar data nearly a decade ago, the company currently claims that it exclusively uses “non-sensitive information” like your age range and zip code to serve up targeted ads.
But T-Mobile also won’t stop marketers from taking things into their own hands. One ad agency exec that spoke with AdExchanger said that one of the “most exciting” things about this new ad product is the ability to microtarget members of the LGBTQ community. Sure, that’s not one of the prebuilt personas offered in the App Insights product, “but a marketer could target phones with Grindr installed, for example, or use those audiences for analytics,” the original interview notes.
Riot Games will begin background evaluation of recorded in-game voice communications on July 13th in North America, in English. In a brief statement (opens in new tab) Riot said that the purpose of the recording is ultimately to “collect clear evidence that could verify any violations of behavioral policies.”
For now, however, recordings will be used to develop the evaluation system that may eventually be implemented. That means training some kind of language model using the recordings, says Riot, to “get the tech in a good enough place for a beta launch later this year.”
Riot also makes clear that voice evaluation from this test will not be used for reports. “We know that before we can even think of expanding this tool, we’ll have to be confident it’s effective, and if mistakes happen, we have systems in place to make sure we can correct any false positives (or negatives for that matter),” said Riot.
The judges sided, by a two-to-one majority, with the IPO, which had told him to list a real person as the inventor.
“Only a person can have rights – a machine cannot,” wrote Lady Justice Laing in her judgement.
“A patent is a statutory right and it can only be granted to a person.”
But the IPO also said it would “need to understand how our IP system should protect AI-devised inventions in the future” and committed to advancing international discussions, with a view to keeping the UK competitive.
In July 2021, in a case also brought by Mr Thaler, an Australian court decided AI systems could be recognised as inventors for patent purposes.
Days earlier, South Africa had issued a similar ruling.
Many AI systems are trained on large amounts of data copied from the internet.
And, on Tuesday, the IPO also announced plans to change copyright law to allow anyone with lawful access – rather than only those conducting non-commercial research, as now – to do this, to “promote the use of AI technology, and wider ‘data mining’ techniques, for the public good”.
Rights holders will still be able to control and charge for access to their works but no longer charge extra for the ability to mine them.
An increasing number of people are using AI tools such as DALL.E 2 to create images resembling a work of human art.
And Mr Thaler has recently sued the US Copyright Office over its refusal to recognise a software system as the “author” of an image, the Register reported.
Coinbase Tracer, the analytics arm of the cryptocurrency exchange Coinbase, has signed a contract with U.S. Immigrations and Customs Enforcement that would allow the agency access to a variety of features and data caches, including “historical geo tracking data.”
Coinbase Tracer, according to the website, is for governments, crypto businesses, and financial institutions. It allows these clients the ability to trace transactions within the blockchain. It is also used to “investigate illicit activities including money laundering and terrorist financing” and “screen risky crypto transactions to ensure regulatory compliance.”
The deal was originally signed September 2021, but the contract was only now obtained by watchdog group Tech Inquiry. The deal was made for a maximum amount of $1.37 million, and we knew at the time that this was a three year contract for Coinbase’s analytic software. The now revealed contract allows us to look more into what this deal entails.
This deal will allow ICE to track transactions made through twelve different currencies, including Ethereum, Tether, and Bitcoin. Other features include “Transaction demixing and shielded transaction analysis,” which appears to be aimed at preventing users from laundering funds or hiding transactions. Another feature is the ability to “Multi-hop link analysis for incoming and outgoing funds” which would give ICE insight into the transfer of the currencies. The most mysterious one is access to “historical geo tracking data,” and ICE gave a little insight into how this tool may be used.
Google is to pay $90 million to settle a class-action lawsuit with US developers over alleged anti-competitive behavior regarding the Google Play Store.
Eligible for a share in the $90 million fund are US developers who earned two million dollars or less in annual revenue through Google Play between 2016 and 2021. “A vast majority of US developers who earned revenue through Google Play will be eligible to receive money from this fund,” said Google.
Law firm Hagens Berman announced the settlement this morning, having been one of the first to file a class case. The legal firm was one of four that secured a $100 million settlement from Apple in 2021 for US iOS developers.
The accusations that will be settled are depressing familiar – attorneys had alleged that Google excluded competing app stores from its platform and that the search giant charged app developers eye-watering fees.
Google said it “and a group of US developers have reached a proposed settlement that allows both parties to move forward and avoids years of uncertain and distracting litigation.”
If the court gives the go-ahead, developers that qualify will be notified.
As well as the settlement [PDF], Google has promised changes to Android 12 to make it easier for other app stores to be used on devices and to revise its Developer Distribution Agreement to clarify that developers can use contact information obtained in-app to direct users to offers on a rival app store or the developer’s own site.
The lawsuit goes back to 2020, when Hagens Berman and Sperling & Slater filed in the US District Court for the Northern District of California. Back then, much was made of a default 30 percent commission levied by Google on Play Store app purchases and in-app transactions. Google currently has a tiered model, implemented in 2021, where the first $1 million in annual revenue was subject to a reduced 15 per cent, but it appears this has been insufficient to keep the lawyers at bay.
The Software Freedom Conservancy (SFC), a non-profit focused on free and open source software (FOSS), said it has stopped using Microsoft’s GitHub for project hosting – and is urging other software developers to do the same.
In a blog post on Thursday, Denver Gingerich, SFC FOSS license compliance engineer, and Bradley M. Kuhn, SFC policy fellow, said GitHub has over the past decade come to play a dominant role in FOSS development by building an interface and social features around Git, the widely used open source version control software.
In so doing, they claim, the company has convinced FOSS developers to contribute to the development of a proprietary service that exploits FOSS.
“We are ending all our own uses of GitHub, and announcing a long-term plan to assist FOSS projects to migrate away from GitHub,” said Gingerich and Kuhn.
We will no longer accept new member projects that do not have a long-term plan to migrate away from GitHub
The SFC mostly uses self-hosted Git repositories, they say, but the organization did use GitHub to mirror its repos.
The SFC has added a Give Up on GitHub section to its website and is asking FOSS developers to voluntarily switch to a different code hosting service.
[…]
For the SFC, the break with GitHub was precipitated by the general availability of GitHub Copilot, an AI coding assistant tool. GitHub’s decision to release a for-profit product derived from FOSS code, the SFC said, is “too much to bear.”
Copilot, based on OpenAI’s Codex, suggests code and functions to developers as they’re working. It’s able to do so because it was trained “on natural language text and source code from publicly available sources, including code in public repositories on GitHub,” according to GitHub.
[…]
Gingerich and Kuhn see that as a problem because Microsoft and GitHub have failed to provide answers about the copyright ramifications of training its AI system on public code, about why Copilot was trained on FOSS code but not copyrighted Windows code, and whether the company can specify all the software licenses and copyright holders attached to code used in the training data set.
Kuhn has written previously about his concerns that Copilot’s training may present legal risks and others have raised similar concerns. Last week, Matthew Butterick, a designer, programmer, and attorney, published a blog post stating that he agrees with those who argue that Copilot is an engine for violating open-source licenses.
“Copilot completely severs the connection between its inputs (= code under various open-source licenses) and its outputs (= code algorithmically produced by Copilot),” he wrote. “Thus, after 20+ years, Microsoft has finally produced the very thing it falsely accused open source of being: a black hole of IP rights.”
Such claims have not been settled and likely won’t be until there’s actual litigation and judgment. Other lawyers note that GitHub’s Terms of Service give it the right to use hosted code to improve the service. And certainly legal experts at Microsoft and GitHub believe they’re off the hook for license compliance, which they pass on to those using Copilot to generate code.
With the release of Firefox 102, Mozilla has added the new ‘Query Parameter Stripping’ feature that automatically strips various query parameters used for tracking from URLs when you open them, whether that be by clicking on a link or simply pasting the URL into the address bar.
Once enabled, Mozilla Firefox will now strip the following tracking parameters from URLs when you click on links or paste an URL into the address bar:
Olytics: oly_enc_id=, oly_anon_id=
Drip: __s=
Vero: vero_id=
HubSpot: _hsenc=
Marketo: mkt_tok=
Facebook: fbclid=, mc_eid=
[…]
To enable Query Parameter Stripping, go into the Firefox Settings, click on Privacy & Security, and then change ‘Enhanced Tracking Protection’ to ‘Strict.’
Mozilla Firefox’s Enhanced Tracking Protection set to Strict Source: BleepingComputer
However, these tracking parameters will not be stripped in Private Mode even with Strict mode enabled.
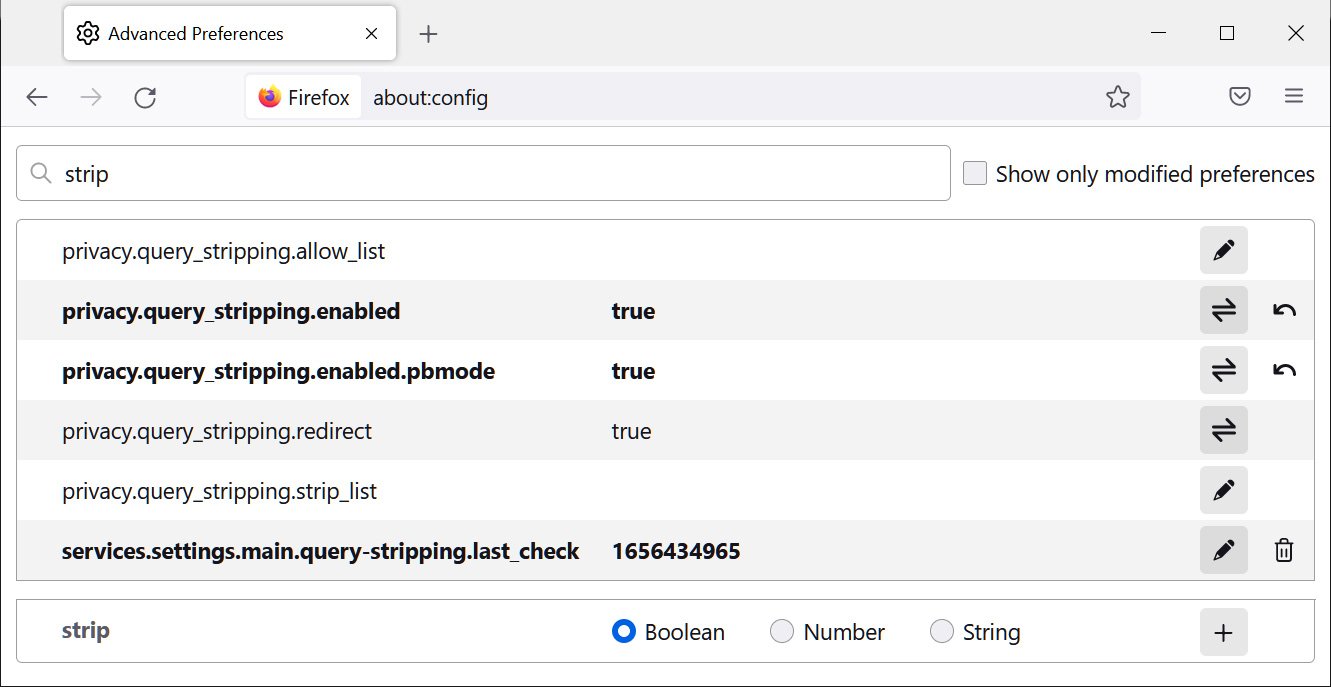
To also enable the feature in Private Mode, enter about:config in the address bar, search for strip, and set the ‘privacy.query_stripping.enabled.pbmode‘ option to true, as shown below.
It should be noted that setting Enhanced Tracking Protection to Strict could cause issues when using particular sites.
If you enable this feature and find that sites are not working correctly, just set it back to Standard (disables this feature) or the Custom setting, which will require some tweaking.