On Thursday, the EU Council is scheduled to vote on a legislative proposal that would attempt to protect children online by disallowing confidential communication.
The vote had been set for Wednesday but got pushed back [PDF].
Known to detractors as Chat Control, the proposal seeks to prevent the online dissemination of child sexual abuse material (CSAM) by requiring internet service providers to scan digital communication – private chats, emails, social media messages, and photos – for unlawful content.
The proposal [PDF], recognizing the difficulty of explicitly outlawing encryption, calls for “client-side scanning” or “upload moderation” – analyzing content on people’s mobile devices and computers for certain wrongdoing before it gets encrypted and transmitted.
The idea is that algorithms running locally on people’s devices will reliably recognize CSAM (and whatever else is deemed sufficiently awful), block it, and/or report it to authorities. This act of automatically policing and reporting people’s stuff before it’s even had a chance to be securely transferred rather undermines the point of encryption in the first place.
We’ve been here before. Apple announced plans to implement a client-side scanning scheme back in August 2021, only to face withering criticism from the security community and civil society groups. In late 2021, the iGiant essentially abandoned the idea.
Europe’s planned “regulation laying down rules to prevent and combat child sexual abuse” is not the only legislative proposal that contemplates client-side scanning as a way to front-run the application of encryption. The US Earn-It Act imagines something similar.
In the UK, the Online Safety Act of 2023 includes a content scanning requirement, though with the government’s acknowledgement that enforcement isn’t presently feasible. While it does allow telecoms regulator Ofcom to require online platforms to adopt an “accredited technology” to identify unlawful content, there is currently no such technology and it’s unclear how accreditation would work.
With the EU proposal vote approaching, opponents of the plan have renewed their calls to shelve the pre-crime surveillance regime.
In an open letter [PDF] on Monday, Meredith Whittaker, CEO of Signal, which threatened to withdraw its app from the UK if the Online Safety Act disallowed encryption, reiterated why the EU client-side scanning plan is unworkable and dangerous.
“There is no way to implement such proposals in the context of end-to-end encrypted communications without fundamentally undermining encryption and creating a dangerous vulnerability in core infrastructure that would have global implications well beyond Europe,” wrote Whittaker.
European countries continue to play rhetorical games. They’ve come back to the table with the same idea under a new label
“Instead of accepting this fundamental mathematical reality, some European countries continue to play rhetorical games.
“They’ve come back to the table with the same idea under a new label. Instead of using the previous term ‘client-side scanning,’ they’ve rebranded and are now calling it ‘upload moderation.’
“Some are claiming that ‘upload moderation’ does not undermine encryption because it happens before your message or video is encrypted. This is untrue.”
The Internet Architecture Board, part of the Internet Engineering Task Force, offered a similar assessment of client-side scanning in December.
Encrypted comms service Threema published its open variation on this theme on Monday, arguing that mass surveillance is incompatible with democracy, is ineffective, and undermines data security.
“Should it pass, the consequences would be devastating: Under the pretext of child protection, EU citizens would no longer be able to communicate in a safe and private manner on the internet,” the biz wrote.
EU citizens would no longer be able to communicate in a safe and private manner on the internet
“The European market’s location advantage would suffer a massive hit due to a substantial decrease in data security. And EU professionals like lawyers, journalists, and physicians could no longer uphold their duty to confidentiality online. All while children wouldn’t be better protected in the least bit.”
Threema said if it isn’t allowed to offer encryption, it will leave the EU.
And on Tuesday, 37 Members of Parliament signed an open letter to the Council of Europe urging legislators to reject Chat Control.
“We explicitly warn that the obligation to systematically scan encrypted communication, whether called ‘upload-moderation’ or ‘client-side scanning,’ would not only break secure end-to-end encryption, but will to a high probability also not withstand the case law of the European Court of Justice,” the MEPs said. “Rather, such an attack would be in complete contrast to the European commitment to secure communication and digital privacy, as well as human rights in the digital space.” ®
The mysterious brightening of a galaxy far, far away has been traced to the heart of the star system and the sudden awakening of a giant black hole 1m times more massive than the sun.
Decades of observations found nothing remarkable about the distant galaxy in the constellation of Virgo, but that changed at the end of 2019 when astronomers noticed a dramatic surge in its luminosity that persists to this day.
Researchers now believe they are witnessing changes that have never been seen before, with the black hole at the galaxy’s core putting on an extreme cosmic light show as vast amounts of material fall into it.
“We discovered this source at the moment it started to show these variations in luminosity,” said Dr Paula Sánchez-Sáez, a staff astronomer at the European Southern Observatory headquarters in Garching, Germany. “It’s the first time we’ve see this in real time.”
The galaxy, which goes by the snappy codename SDSS1335+0728 and lies 300m light years away, was flagged to astronomers in December 2019 when an observatory in California called the Zwicky Transient Facility recorded a sudden rise in its brightness.
The alert prompted a flurry of new observations and checks of archived measurements from ground- and space-based telescopes to understand more about the galaxy and its past behaviour.
The scientists discovered the galaxy had recently doubled in brightness in mid-infrared wavelengths, become four times brighter in the ultraviolet, and at least 10 times brighter in the X-ray range.
What triggered the sudden brightening is unclear, but writing in Astronomy and Astrophysics, the researchers say the most likely explanation is the creation of an “active galactic nucleus” where a vast black hole at the centre of a galaxy starts actively consuming the material around it.
Active galactic nuclei emit a broad spectrum of light as gas around the black hole heats up and glows, and surrounding dust particles absorb some wavelengths and re-radiate others.
But it is not the only possibility. The team has not ruled out an exotic form of “tidal disruption event”, a highly restrained phrase to describe a star that is ripped apart after straying too close to a black hole.
Tidal disruption events tend to be brief affairs, brightening a galaxy for no more than a few hundred days, but more measurements are needed to rule out the process. “With the data we have at the moment, it’s impossible to disentangle which of these scenarios is real,” said Sánchez-Sáez. “We need to keep monitoring the source.”
Apple and the satellite-based broadband service Starlink each recently took steps to address new research into the potential security and privacy implications of how their services geo-locate devices. Researchers from the University of Maryland say they relied on publicly available data from Apple to track the location of billions of devices globally — including non-Apple devices like Starlink systems — and found they could use this data to monitor the destruction of Gaza, as well as the movements and in many cases identities of Russian and Ukrainian troops.
At issue is the way that Apple collects and publicly shares information about the precise location of all Wi-Fi access points seen by its devices. Apple collects this location data to give Apple devices a crowdsourced, low-power alternative to constantly requesting global positioning system (GPS) coordinates.
Both Apple and Google operate their own Wi-Fi-based Positioning Systems (WPS) that obtain certain hardware identifiers from all wireless access points that come within range of their mobile devices. Both record the Media Access Control (MAC) address that a Wi-FI access point uses, known as a Basic Service Set Identifier or BSSID.
Periodically, Apple and Google mobile devices will forward their locations — by querying GPS and/or by using cellular towers as landmarks — along with any nearby BSSIDs. This combination of data allows Apple and Google devices to figure out where they are within a few feet or meters, and it’s what allows your mobile phone to continue displaying your planned route even when the device can’t get a fix on GPS.
[…]
In essence, Google’s WPS computes the user’s location and shares it with the device. Apple’s WPS gives its devices a large enough amount of data about the location of known access points in the area that the devices can do that estimation on their own.
That’s according to two researchers at the University of Maryland, who theorized they could use the verbosity of Apple’s API to map the movement of individual devices into and out of virtually any defined area of the world. The UMD pair said they spent a month early in their research continuously querying the API, asking it for the location of more than a billion BSSIDs generated at random.
They learned that while only about three million of those randomly generated BSSIDs were known to Apple’s Wi-Fi geolocation API, Apple also returned an additional 488 million BSSID locations already stored in its WPS from other lookups.
[…]
Plotting the locations returned by Apple’s WPS between November 2022 and November 2023, Levin and Rye saw they had a near global view of the locations tied to more than two billion Wi-Fi access points. The map showed geolocated access points in nearly every corner of the globe, apart from almost the entirety of China, vast stretches of desert wilderness in central Australia and Africa, and deep in the rainforests of South America.
A “heatmap” of BSSIDs the UMD team said they discovered by guessing randomly at BSSIDs.
The researchers said that by zeroing in on or “geofencing” other smaller regions indexed by Apple’s location API, they could monitor how Wi-Fi access points moved over time. Why might that be a big deal? They found that by geofencing active conflict zones in Ukraine, they were able to determine the location and movement of Starlink devices used by both Ukrainian and Russian forces.
The reason they were able to do that is that each Starlink terminal — the dish and associated hardware that allows a Starlink customer to receive Internet service from a constellation of orbiting Starlink satellites — includes its own Wi-Fi access point, whose location is going to be automatically indexed by any nearby Apple devices that have location services enabled.
A heatmap of Starlink routers in Ukraine. Image: UMD.
The University of Maryland team geo-fenced various conflict zones in Ukraine, and identified at least 3,722 Starlink terminals geolocated in Ukraine.
“We find what appear to be personal devices being brought by military personnel into war zones, exposing pre-deployment sites and military positions,” the researchers wrote. “Our results also show individuals who have left Ukraine to a wide range of countries, validating public reports of where Ukrainian refugees have resettled.”
[…]
The researchers also focused their geofencing on the Israel-Hamas war in Gaza, and were able to track the migration and disappearance of devices throughout the Gaza Strip as Israeli forces cut power to the country and bombing campaigns knocked out key infrastructure.
“As time progressed, the number of Gazan BSSIDs that are geolocatable continued to decline,” they wrote. “By the end of the month, only 28% of the original BSSIDs were still found in the Apple WPS.”
In late March 2024, Apple quietly updated its website to note that anyone can opt out of having the location of their wireless access points collected and shared by Apple — by appending “_nomap” to the end of the Wi-Fi access point’s name (SSID). Adding “_nomap” to your Wi-Fi network name also blocks Google from indexing its location.
[…]
Rye said Apple’s response addressed the most depressing aspect of their research: That there was previously no way for anyone to opt out of this data collection.
“You may not have Apple products, but if you have an access point and someone near you owns an Apple device, your BSSID will be in [Apple’s] database,” he said. “What’s important to note here is that every access point is being tracked, without opting in, whether they run an Apple device or not. Only after we disclosed this to Apple have they added the ability for people to opt out.”
The researchers said they hope Apple will consider additional safeguards, such as proactive ways to limit abuses of its location API.
[…]
“We observe routers move between cities and countries, potentially representing their owner’s relocation or a business transaction between an old and new owner,” they wrote. “While there is not necessarily a 1-to-1 relationship between Wi-Fi routers and users, home routers typically only have several. If these users are vulnerable populations, such as those fleeing intimate partner violence or a stalker, their router simply being online can disclose their new location.”
The researchers said Wi-Fi access points that can be created using a mobile device’s built-in cellular modem do not create a location privacy risk for their users because mobile phone hotspots will choose a random BSSID when activated.
[…]
For example, they discovered that certain commonly used travel routers compound the potential privacy risks.
“Because travel routers are frequently used on campers or boats, we see a significant number of them move between campgrounds, RV parks, and marinas,” the UMD duo wrote. “They are used by vacationers who move between residential dwellings and hotels. We have evidence of their use by military members as they deploy from their homes and bases to war zones.”
A copy of the UMD research is available here (PDF).
The visualisation of US vs EU spending on NATO going the rounds is pretty suspect: The Blue area contains not just the USA, but also Canada. The US defence budget is incorrect. It fails to take into account that the US is a global player with ambitions and commitments beyond NATO. It doesn’t show that EU defence spending is larger than that of Russia and China. There is no mention of the pressure the USA exerts on it’s NATO allies to Buy American – and the staggering amount the US shop window filled with pretty poor products (such as the F-35) is valued at. There is no mention of the years of fragmentation inflicted on the EU by the US to insure that the EU was never able to create economies of scale, or even a common security and defence policy. Finally, the scale of US defence spending comes at a cost. Social and welfare spending is much much lower in the US than in the EU, which helps explain the low levels of education, happiness, social mobility, etc in the US. A sacrifice the EU does not seem to want to make.
[…] the moral high ground on which the United States stands to shame allies on defense spending is partly an illusion. There is no question Washington spends significant resources on defense, but likening total US defense expenditures to those of its allies is not an appropriate comparison. Unlike most other NATO nations, the United States is a global actor with commitments extending to the Middle East and IndoPacific as well as Europe. Most European defense capabilities are expended in theater or in direct support of NATO missions like in Afghanistan, whereas only a portion of the US defense budget is dedicated to transatlantic security.[…] the common pretense in US policy circles that the entirety of US defense spending is counted toward European security is logically unsound.
[…] In addition, continental US territory falls under NATO’s collective-defence commitment, so US forces devoted to US continental defence also in effect amount to a NATO commitment to defend the Alliance’s largest member. The same goes particularly for Canada’s commitment to North American defence. But that commitment is Alliance-wide, and – as has been often remarked – the one activation of NATO’s Article 5 collective-defence undertaking was in the aftermath of the 9/11 attacks on the US, when the rest of the Alliance quickly supplemented US air defences with Alliance-operated AWACS airborne early-warning aircraft.
However, America is spending its defence dollars principally for its own security needs, as well as to support a range of interests and allies in other regions around the world, not exclusively Europe. As one can see, the balance sheet is complicated to say the least – those assets and resources are developed first and foremost for national interests and therefore have a dual US/external-security use. […]
This focus on US security needs is particularly visible when you look at the amount of troops the US commits to United Nations peacekeeping operations.
The U.S. [….] currently has only 27 personnel in the peacekeepers, as of November 2023. Of them, 21 are staff officers, four are “experts on mission,” and two are police; none are troops.
Other countries that have zero “boots on the ground” include: Canada, Japan, and Australia.
US Spending is about equal to Asian spending, and only slightly higher than the largest EU contributors
This lack of actual boots on the ground but amount of expenditure points to what the United States is really supporting: it’s defence industry.
US Business interests winning – Coercion by the US to buy US products
The US uses strong arm tactics to sell their products to countries that have an indigenous arms industry – usually composed of better and cheaper to operate products. The US, however, won’t take no for an answer – and US companies profit massively. How massively? See below.
[…] NATO creates a market for defence sales. Over the last two years, NATO Allies have agreed to purchase 120 billion dollars’ worth of weapons from U.S. defence companies. Including thousands of missiles to the U.K, Finland and Lithuania, Hundreds of Abrams tanks to Poland and Romania, And hundreds of F-35 aircraft across many European Allied nations – a total of 600 by 2030. From Arizona to Virginia, Florida to Washington state, American jobs depend on American sales to defence markets in Europe and Canada. What you produce keeps people safe. What Allies buy keeps American businesses strong. So NATO is a good deal for the United States. […]
The U.S. alone represents a quarter of the world economy. But together, with NATO Allies, we represent half of the world’s economic might. And half of the world’s military might. Together, we have world-class militaries, vast intelligence networks, more defence spending, and unique diplomatic leverage.[…]
A total of 23 per cent of US arms exports went to states in Europe in 2018–22, up from 11 per cent in 2013–17. Three of the USA’s North Atlantic 4 sipri fact sheet Treaty Organization (NATO) partners in the region were among the 10 largest importers of US arms in 2018–22: the UK accounted for 4.6 per cent of US arms exports, the Netherlands for 4.4 per cent and Norway for 4.2 per cent.
[…]
Arms imports by European states were 47 per higher in 2018–22 than in 2013–17. The biggest European arms importer in 2018–22 was the UK, which was the 13th largest arms importer in the world, followed by Ukraine (see box 2) and Norway, ranking 14th and 15th respectively. The USA accounted for 56 per of the region’s arms imports in 2018–22, Russia for 5.8 per (mainly to Belarus) and Germany for 5.1 per cent.
European NATO states Largely in response to the deteriorating security environment in the region, NATO states in Europe increased their arms imports by 65 per cent between 2013–17 and 2018–22. The USA accounted for 65 per cent of total arms imports by European NATO states and the NATO organization itself (see table 2) in 2018–22. The next biggest suppliers were France (8.6 per cent) and South Korea (4.9 per cent). The arms imports of European NATO states are expected to continue to rise in the coming years, based on existing programmes for arms imports. These include orders placed before the February 2022 Russian invasion of Ukraine and several large orders announced afterwards. Some of the orders placed in 2022 were the result of accelerated procurement processes implemented in response to the war in Ukraine. For example, in the first four years of the period (2018–21), Poland’s most notable arms import orders included 32 combat aircraft and 4 missile and air defence systems from the USA; however, in 2022 Poland announced new orders for 394 tanks, 96 combat helicopters and 12 missile and air defence systems from the USA; 48 combat aircraft, 1000 tanks, 672 self-propelled guns and 288 multiple rocket launchers from South Korea; and 3 frigates from the UK. After an accelerated procurement process, Germany ordered 35 combat aircraft from the USA in late 2022. These are specifically for carrying nuclear weapons owned by the USA and will replace existing aircraft that have this task.
And if you don’t buy US equipment, or don’t want to? You are leant on before you buy and after you buy. The following show rare but explicitly how the US conducts ‘business’
The U.S. government expressed disappointment with the Czech Republic and Hungary for their December moves toward acquiring non-American-made fighter jets. The rare public criticism of U.S. NATO allies comes as Poland also considers purchasing new fighter jets for its air force.
Speaking December 18, State Department spokesman Richard Boucher said that the Czech Republic, Hungary, and Poland—all of which joined NATO in 1999—should not jeopardize more urgent military needs and reforms necessary for the three countries to work more effectively with NATO’s other 16 members by purchasing advanced fighter jets, which can cost up to tens of millions of dollars apiece.
But Boucher continued by saying, “If you’re going to buy [combat aircraft], buy American.” Adding that “we think we make the best,” he said that Secretary of State Colin Powell “has raised the interest of American companies in selling airplanes” during meetings with officials from the three countries. […]
The Pentagon estimated in June that a sale of 60 U.S. F-16 fighters to Poland would cost $4.3 billion. This price tag includes missiles and bombs to arm the aircraft as well as U.S. training.
MR. BOUCHER: The Secretary has been a staunch supporter of American aircraft sales, and in his meetings from the very beginning of the Administration, he has raised the fortunes of American companies and the fact that we make the best airplanes in the world. He has pressed that in a variety of meetings. So we are disappointed that the Czech Republic and Hungary recently took steps forward in procuring advanced supersonic fighter aircraft […] The Secretary has raised these issues about the cost, the spending, the implication for other programs. But in the end, he has always said if you’re going to buy airplanes, you ought to buy American ones
QUESTION: So do you think that their purchase of these jets and using them could affect badly — adversely affect NATO in some way?
MR. BOUCHER: We have — I think we have tried to make clear all along that, as nations address these force requirements and these purchases, they needed to consider the overall impact on military reform programs and abilities to meet their broader global force obligations to NATO. And those are important questions that we think need to be considered.
[…]
MR. BOUCHER: Yes. If you’re going to buy, buy American. But consider carefully how you can meet your overall obligations.
QUESTION: Richard, you seem to be saying — let me get this straight. Do you think it was unwise of these two governments to decide to buy planes instead of doing something else with the money?
MR. BOUCHER: I don’t think I would use your language. I think I will stick to my language, thanks.
QUESTION: What was your language — you think it was what, then? You think —
MR. BOUCHER: As I said, we think that they should avoid major defense procurements, which could jeopardize other urgently needed military reforms.
QUESTION: But if they are going to make them, they should buy from the States and not from —
MR. BOUCHER: Yes
[…]
QUESTION: I don’t understand the interoperability thing that you just brought up with Barry. Because, I mean, are you saying that, say, French aircraft or British aircraft are not interoperable within the NATO scheme of things? I mean, these countries fly their own planes. Why can’t — why do the Czechs have to buy your planes, and why can’t they buy from someone — I mean, I can understand if they were buying from China, or from — (laughter) — what’s the deal?
[…]
MR. BOUCHER: Nobody said they can’t buy some other airplane. We haven’t argued that these other airplanes cannot be interoperable with NATO — with American airplanes or NATO airplanes or other airplanes that NATO maintains in its inventory. Our view has been that when it comes to airplanes, first of all, we make the best ones. And second of all, we make airplanes that have been deployed throughout the world, that have been proven in combat, that have been proven in lots of different situations. And they have a demonstrated record of interoperability, as well as performance. And we think we make the best. So we make that clear to other countries when we talk to them.
QUESTION: But can’t you let, you know, Boeing and Lockheed Martin make their own sales pitch for them?
MR. BOUCHER: We like to support American workers, American companies.
QUESTION: All right.
QUESTION: Sort of related to that. Can you just expand on how the Secretary has raised the fortunes of American aircraft companies? I’m just — that was what you said originally —
MR. BOUCHER: Perhaps it’s not the best phrase. He has raised the interests of American aircraft companies in selling airplanes.
QUESTION: But he didn’t — I just want to —
MR. BOUCHER: I didn’t say he — that he — I didn’t mean to say that he brought more money their way. No.
QUESTION: Okay. I just —
MR. BOUCHER: That was a bad — perhaps a bad choice of words. But that was not the implication. He has raised the interest of American companies in selling airplanes.
The following excerpts show the US way of thinking re common EU defence policy. The US has spent decades strong arming the EU into not working together. They used scare tactics and nonsense texts in order to assure US supremacy within NATO as well as globally. Of course, there is a lot to be said that the EU allowed themselves to be bossed around, and the weak spines of the EU politicians (and of course their wallets, as they were still paying back the Marshall Plan to uncertain terms) can be shown. At the same time, their military advisors were playing in terms of self interest – they wanted to keep playing with US toys and at US facilities and at the scale the US exercises were held and didn’t see that if they had a single EU defence policy, they would be able to play at that scale – but with toys and capabilities they got to design themselves, instead of riding on US coat tails.
From a military standpoint, the European Union’s Security and Defense Policy (ESDP) defies logic. Why would the European allies seek to create a competing military force outside NATO when worried about American isolationism and when unable and unwilling to dedicate the necessary resources? This article suggests an alternative motive behind the European Union’s establishment of a defense program—the development and enhancement of a “European identity.” In short, the ESDP is designed in no small part to further the project of nation-building in a broadening European Union. This article proposes a social-constructivist framework for analyzing this development.
The level of Europe’s defense spending and the size of its collective forces in uniform should make it a global power with one of the strongest militaries in the world. But Europe does not act as one on defense, even though it formed a political union almost 30 years ago. Europe’s military strength today is far weaker than the sum of its parts. This is not just a European failure; it is also fundamentally a failure of America’s post-Cold War strategy toward Europe—a strategy that remains virtually unchanged since the 1990s.
Europe’s dependence on the United States for its security means that the United States possesses a de facto veto on the direction of European defense. Since the 1990s, the United States has typically used its effective veto power to block the defense ambitions of the European Union. This has frequently resulted in an absurd situation where Washington loudly insists that Europe do more on defense but then strongly objects when Europe’s political union—the European Union—tries to answer the call. This policy approach has been a grand strategic error—one that has weakened NATO militarily, strained the trans-Atlantic alliance, and contributed to the relative decline in Europe’s global clout. As a result, one of America’s closest partners and allies of first resort is not nearly as powerful as it could be.
[…]
U.S. policy has consistently opposed EU defense efforts since the late 1990s, arguing that EU defense efforts would undermine NATO. State Department officials’ oft-repeated claim, virtually unchanged over the past three decades, is that an EU defense structure would “duplicate” NATO, making the treaty organization obsolete. Democratic and Republican administrations have repeated the mantra “no duplication” so often that it has become U.S. policy doctrine.5 But rarely, if ever, is the concern about possible duplication actually unpacked and assessed.
[…]
The limited nature of current EU defense efforts is no doubt the fault of the EU. But the immense agency the United States has on European defense questions is also undeniable. Since the 1990s, the United States has wielded its influence, often by mobilizing EU members that are most dependent on U.S. security guarantees to block or constrain EU efforts.
Thus, for nearly 25 years, the United States has opposed the federalization of European foreign and defense policy at the EU level.
[…]
in December 1998, Secretary of State Madeleine Albright struck a different tone than her predecessor 45 years earlier.13 In just a few short sentences, she laid out Washington’s concerns. She explained that the effort to create a European Security and Defense Identity (ESDI) must avoid “de-linking ESDI from NATO, avoid duplicating existing efforts, and avoid discriminating against non-EU members.” Secretary Albright’s address became known as the “three Ds”—no duplicating, discriminating, or delinking.
Secretary Albright’s speech was prompted by what seemed, at the time, like a stunning European breakthrough on defense. Just four days prior, a remarkable agreement was signed by U.K. Prime Minister Tony Blair and French President Jacques Chirac in St. Malo, France. There, the two largest European military powers agreed to support the formation of a 60,000 strong European force.
[…]
Secretary Albright’s “three Ds,” if rigidly interpreted, left little room for the EU to expand into defense. The speech became a de facto doctrine that has been rigidly adhered to ever since, even if that was not the original intent. The subsequent two decades have shown that any EU effort could be accused of being duplicative or discriminating against non-EU states.
[…]
U.S. Secretary of Defense William Cohen warned in his final NATO summit in 2000—in what The Washington Post described as an “unusually passionate speech” at a NATO Defense Ministerial—that “there will be no EU caucus in NATO” and that NATO could become “a relic of the past” should the EU move forward with its proposal to set up a rapid reaction force.16
[…]
Indeed, when the Bush administration took office in 2001, it pushed NATO to create an alternative to the EU’s rapid reaction force proposal, the NATO Response Force.
[…]
In a letter that caught Brussels completely off guard, the State Department’s Under Secretary of State Andrea Thompson and Under Secretary of Defense Ellen Lord warned the EU of retribution if it did not include the United States or third parties to participate in PESCO projects.33 Returning to the concerns that Secretary Albright had voiced 20 years prior, they argued that there was a risk of “EU capabilities developing in a manner that produces duplication, non-interoperable military systems, diversion of scarce defense resources, and unnecessary competition between NATO and the EU.”34 Yet the inclusion that the Trump administration demanded is not reciprocal, as the United States would not allow European defense companies similar access to the U.S. defense procurements.35 The U.S. Congress wants American taxpayer dollars to go to American companies, and yet the United States expects the EU to operate differently.
The Trump administration maintained U.S. opposition to EU defense, less to preserve NATO equities and more for petty, parochial purposes: the interests of U.S. defense companies. As Nick Witney of the European Council on Foreign Relations (ECFR) points out, the United States “aggressively lobbied against Europeans’ efforts to develop their defence industrial and technological base.”36 This exposes the contradictory nature of U.S. policy: The United States expects Europe to get its act together on defense but to not spend its taxpayer euros on European companies. Indeed, it is hard to see Europeans spending robustly on defense if that spending does not support European jobs and innovation.
[…]
The problem with the current state of European defense is not fundamentally about spending. Collectively, European defense spending levels should actually be enough to put forth a fighting force roughly on par with other global powers. While it is difficult to compare in absolute numbers given the differences in purchasing power, when taken together, the EU spends more on defense than either Russia or China, at nearly $200 billion per year.38
RAND is enormously respected and see the fear instigated in each of their possible scenarios for a common EU defence policy – they apparently lead to greater conflict in the world and otherwise NATO suffers.
This study explored three possible futures of European strategic autonomy in defence to understand their policy implications
[….] Experts varied in their views of which scenario was most plausible, with European interviewees tending to lean towards Scenario 1, which envisages development of a strong European pillar of NATO, on the basis of current trends; and US interviewees expressing some scepticism of this being plausible in the short term (next five years or so). As a result, several US interviewees noted that elements of Scenario 2, which envisage a faltering EU defence integration and transatlantic fragmentation, might be more plausible. A strong Europe that does not rely on NATO for access to military capabilities and structures, as envisaged in Scenario 3, was generally perceived as implausible in the short (five year) term considered by this study
A militarily stronger EU has clear benefits for NATO and the U.S., but the path towards it is not without risks – particularly if it diverges from NATO
A strong European pillar within NATO was largely seen by experts as advantageous for all actors considered: bringing greater military strength to NATO, while creating a militarily stronger partner to the U.S. in a time of intense global competition. Conversely, a capable EU that duplicates or disregards NATO was seen as a threat to transatlantic relations. A number of US interviewees also perceived a risk that the U.S. would lose influence in Europe and would risk divergence of foreign and security policy. This was seen as particularly concerning vis-à-vis other countries the U.S. perceives as competitors and adversaries (e.g. China, Russia) but which some in the EU may not perceive in the same way. The risks accompanying such divergence due to a militarily independent EU were seen as not too dissimilar to those of the opposite extreme of a fragmented Europe.vi A militarily fragmented EU, then, could weaken NATO in terms of defence capabilities but could also mean a further relative increase in US influence within NATO, potentially driving greater coherence of the Alliance. Overall, however, NATO’s credibility – tightly knit with the strength, effectiveness and coordination of military capabilities of the 30 allies – would likely suffer in this scenario. This is because most EU member states are also NATO members and the forces and capabilities they have are the same – whether used for EU CSDP missions or operations through NATO. US foreign and security policy ambitions could also suffer if one of its crucial allies were to become fragmented and militarily weak
As you can tell, the EU seems to care a lot more for it’s citizens.
The EU also believes in prevention. Delivering Official development assistance (ODA) is a way to prevent conflicts globally. The EU spends around EUR 50 billion per year on ODA, the US requested $10.5 billion in bolstering humanitarian assistance 2023. The EU is also set to spend around EUR 578 billion on climate spending in the period between 2021 – 2027, around 82.5 billion per year. The US around $2.3 billion in 2023. Climate change affects refugee streams, changing ecosystems and their economic attractiveness. It also makes working conditions harder for people in the defence industry:
The security threats of climate change
With the alarming acceleration of global warming and weather extremes across the globe, environmental issues have become more severe and climate change has become a defining issue of our time. Climate change causes complications for fresh water management and water scarcity, as well as health issues, biodiversity loss and demographic challenges. Other consequences like famine, drought and marine environmental degradation lead to loss of land and livelihood, and have a disproportionate impact on women and girls, and poor and vulnerable populations.
Climate change is also a threat multiplier that affects NATO security, operations and missions both in the Euro-Atlantic area and in the Alliance’s broader neighbourhood. It makes it harder for militaries to carry out their tasks. It also shapes the geopolitical environment, leading to instability and geostrategic competition and creating conditions that can be exploited by state and non-state actors that threaten or challenge the Alliance. Increasing surface temperatures, thawing permafrost, desertification, loss of sea ice and glaciers, and the opening up of shipping lanes may cause volatility in the security environment. As such, the High North is one of the epicentres of climate change.
Climate change affects the current and future operating environment, and the military will need to ensure its operational effectiveness in increasingly harsh conditions. Greater temperature extremes, sea level rise, significant changes in precipitation patterns and extreme weather events test the resilience of militaries and infrastructure. For example, increases in ambient temperatures coupled with changing air density (pressure altitude) can have a detrimental impact on fixed- and rotary-wing aircraft performance and air transport capability. Similarly, preventing the overheating of military aircraft, especially the sensitive electronic and airbase installations, requires an increased logistical effort and higher energy consumption. Many transport routes are located on coastal roads, which are particularly vulnerable to weather extremes. These are not only challenges to engineering and technology development, but must also be factored into operational planning scenarios.
The US does indeed spend more than the EU on its’ armed forces, but the amount ‘spent on NATO’ is not a true reflection. The US budget also includes homeland forces as well as the expeditionary ambitions of the USA. It also turns out that the USA thwarts attempts by Europe to form a common security and defence policy, both through their vocal stance against “duplication” by the EU of NATO forces and their strong arm tactics that force the EU to buy American to the detriment of the EU arms industry.
The US budget props up an arms based economy, to the detriment of the US population. US citizens notably less happy than EU citizens, most likely due to the relatively tiny amount that the US spends on social protections, relative to the EU countries.
ASUS has suddenly agreed “to overhaul its customer support and warranty systems,” writes the hardware review site Gamers Nexus — after a three–videoseries on its YouTube channel documented bad and “potentially illegal” handling of customer warranties for the channel’s 2.2 million viewers.
The Verge highlights ASUS’s biggest change: If you’ve ever been denied a warranty repair or charged for a service that was unnecessary or should’ve been free, Asus wants to hear from you at a new email address. It claims those disputes will be processed by Asus’ own staff rather than outsourced customer support agents…. The company is also apologizing today for previous experiences you might have had with repairs. “We’re very sorry to anyone who has had a negative experience with our service team. We appreciate your feedback and giving us a chance to make amends.” It started five weeks ago when Gamers Nexus requested service for a joystick problem, according to a May 10 video. First they’d received a response wrongly telling them their damage was out of warranty — which also meant Asus could add a $20 shipping charge for the requested repair. “Somehow that turned into ASUS saying the LCD needs to be replaced, even though the joystick is covered under their repair policies,” the investigators say in the video. [They also note this response didn’t even address their original joystick problem — “only that thing that they had decided to find” — and that ASUS later made an out-of-the-blue reference to “liquid damage.”] The repair would ultimately cost $191.47, with ASUS mentioning that otherwise “the unit will be sent back un-repaired and may be disassembled.” ASUS gave them four days to respond, with some legalese adding that an out-of-warranty repair fee is non-refundable, yet still “does not guarantee that repairs can be made.”
Even when ASUS later agreed to do a free “partial” repair (providing the requested in-warranty service), the video’s investigators still received another email warning of “pending service cancellation” and return of the unit unless they spoke to “Invoice Quotation Support” immediately. The video-makers stood firm, and the in-warranty repair was later performed free — but they still concluded that “It felt like ASUS tried to scam us.” ASUS’s response was documented in a second video, with ASUS claiming it had merely been sending a list of “available” repairs (and promising that in the future ASUS would stop automatically including costs for the unrequested repair of “cosmetic imperfections” — and that they’d also change their automatic emails.)
ASUS promises it’s “created a Task Force team to retroactively go back through a long history of customer surveys that were negative to try and fix the issues.” (The third video from Gamers Nexus warned ASUS was already on the government’s radar over its handling of warranty issues.)
ASUS also announced their repairs centers were no longer allowed to claim “customer-induced damage” (which Gamers Nexus believes “will remove some of the financial incentive to fail devices” to speed up workloads).
ASUS is creating a new U.S. support center allowing customers to choose either a refurbished board or a longer repair.
Gamers Nexus says they already have devices at ASUS repair centers — under pseudonyms — and that they “plan to continue sampling them over the next 6-12 months so we can ensure these are permanent improvements.” And there’s one final improvement, according to Gamers Nexus. “After over a year of refusing to acknowledge the microSD card reader failures on the ROG Ally [handheld gaming console], ASUS will be posting a formal statement next week about the defect.”
The AWARE program, a project of the US Defense Advanced Research Projects Agency (DARPA), aims to develop a new version of dextroamphetamine that can be activated or deactivated through exposure to near-infrared light. This would enable near-infrared light emitters in a helmet to selectively activate the stimulant in the brain’s prefrontal cortex, and then switch it off when not needed – allowing US military pilots to maintain maximum alertness on duty and catch up on sleep more easily afterward.
If it succeeds, DARPA’s AWARE technology could specifically avoid activating the stimulant in parts of the brain where it might cause unwanted side effects, such as anxiety or euphoria. A euphoric response can also increase the risk of addiction, another unwanted outcome. This may allow military personnel to activate smaller quantities of dextroamphetamine molecules in order to “truly tailor the dosage to the pilot in a personalised way”, says Pedro Irazoqui, program manager for the AWARE project.
The US military has used dextroamphetamine for decades, since the Vietnam War. When a US-led coalition defeated the Iraqi invasion of Kuwait in 1991, a survey showed most F-15 Eagle fighter pilots reported using the stimulants during combat air patrols. But in addition to its addictive potential, the drug’s side effects “can adversely impact team performance”, and the long-lasting stimulant effect can prevent military personnel from taking advantage of naps, according to the DARPA program description. The Air Force suspended stimulant use between 1996 and 2001. However, pilots flying B-2 Spirit bombers were once again using dextroamphetamine during the US invasion of Iraq in 2003.
[…]
Some of the main challenges involve modifying the dextroamphetamine molecule so one portion changes only in the presence of a specific band of near-infrared light, along with making sure that this “PhotoDex” version cannot work in the absence of such light, says Irazoqui. DARPA also plans to work closely with both helmet manufacturers and the US Air Force to ensure the wearable light emitters are compatible with US military headgear.
No photoswitchable drugs have made it into clinical use yet, says Rafael Gómez-Bombarelli at the Massachusetts Institute of Technology. But his research group has used artificial intelligence to design such drugs, and he says technologies exist to help achieve DARPA’s goal.
The DARPA program’s work, which will involve technological development along with safety and efficacy testing in animals, is expected to begin in the fall of 2024 and continue until the fall of 2027. Then the US Air Force plans to take over and begin experiments with humans.
Controversial facial recognition company Clearview AI has agreed to an unusual settlement to a class action lawsuit, The New York Times reports. Rather than paying cash, the company would provide a 23 percent stake in its company to any Americans in its database. Without the settlement, Clearview could go bankrupt, according to court documents.
If you live in the US and have ever posted a photo of yourself publicly online, you may be part of the class action. The settlement could amount to at least $50 million according to court documents, It still must be approved by a federal judge.
Clearview AI, which counts billionaire Peter Thiel as a backer, says it has over 30 billion images in its database. Those can be accessed and cross-referenced by thousands of law enforcement departments including the US FBI and Department of Homeland Security.
Shortly after its identity was outed, Clearview was hit with lawsuits in Illinois, California, Virginia, New York and elsewhere, which were all brought together as a class action suit in a federal Chicago court. The cost of the litigation was said to be draining the company’s reserves, forcing it to seek a creative way to settle the suit.
The relatively small sum divided by the large number of users likely to be in the database means you won’t be receiving a windfall. In any case, it would only happen if the company goes public or is acquired, according to the report. Once that occurs, lawyers would take up to 39 percent of the settlement, meaning the final amount could be reduced to about 30 million. If a third of Americans were in the database (about 110 million), each would get about 27 cents.
That does beg the question of whether it would be worth just over a quarter to see one of the creepiest companies of all time to go bankrupt. To cite a small litany of the actions taken against it (on top of the US class action):
It was sued by the ACLU in 2020 (Clearview agreed to permanently halt sales of its biometric database to private companies in the US as part of the settlement.
Italy slapped a €20 million fine on the company in 2022 and banned it from using images of Italians in its database
Privacy groups in Europe filed complaints against it for allegedly breaking privacy laws (2021)
UK’s privacy watchdog slapped it with a £7.55 million fine and ordered it to delete data from any UK resident
It’s been a rocky couple of months for Sonos — so much so that CEO Patrick Spence now has a canned autoreply for customers emailing him to vent about the redesigned app. But as the company works to right the ship, restore trust, and get the new Sonos Ace headphones off to a strong start, it finds itself in the middle of yet another controversy.
As highlighted by repair technician and consumer privacy advocate Louis Rossmann, Sonos has made a significant change to its privacy policy, at least in the United States, with the removal of one key line. The updated policy no longer contains a sentence that previously said, “Sonos does not and will not sell personal information about our customers.” That pledge is still present in other countries, but it’s nowhere to be found in the updated US policy, which went into effect earlier this month.
Now, some customers, already feeling burned by the new Sonos app’s unsteady performance, are sounding off about what they view as another poor decision from the company’s leadership. For them, it’s been one unforced error after another from a brand they once recommended without hesitation.
[…]
As part of its reworked app platform, Sonos rolled out web-based access for all customer systems — giving the cloud an even bigger role in the company’s architecture. Unfortunately, the web app currently lacks any kind of two-factor authentication, which has also irked users; all it takes is an email address and password to remotely control Sonos devices.
Mozilla has reinstated certain add-ons for Firefox that earlier this week had been banned in Russia by the Kremlin.
The browser extensions, which are hosted on the Mozilla store, were made unavailable in the Land of Putin on or around June 8 after a request by the Russian government and its internet censorship agency, Roskomnadzor.
Among those extensions were three pieces of code that were explicitly designed to circumvent state censorship – including a VPN and Censor Tracker, a multi-purpose add-on that allowed users to see what websites shared user data, and a tool to access Tor websites.
The day the ban went into effect, Roskomsvoboda – the developer of Censor Tracker – took to the official Mozilla forums and asked why his extension was suddenly banned in Russia with no warning.
[…]
“In alignment with our commitment to an open and accessible internet, Mozilla will reinstate previously restricted listings in Russia,” the group declared. “Our initial decision to temporarily restrict these listings was made while we considered the regulatory environment in Russia and the potential risk to our community and staff.
“We remain committed to supporting our users in Russia and worldwide and will continue to advocate for an open and accessible internet for all.”
The Mozilla Foundation, the entity behind the web browser Firefox, is blocking various censorship circumvention add-ons for its browser, including ones specifically to help those in Russia bypass state censorship. The add-ons were blocked at the request of Russia’s federal censorship agency, Roskomnadzor — the Federal Service for Supervision of Communications, Information Technology, and Mass Media — according to a statement by Mozilla to The Intercept.
“Following recent regulatory changes in Russia, we received persistent requests from Roskomnadzor demanding that five add-ons be removed from the Mozilla add-on store,” a Mozilla spokesperson told The Intercept in response to a request for comment. “After careful consideration, we’ve temporarily restricted their availability within Russia. Recognizing the implications of these actions, we are closely evaluating our next steps while keeping in mind our local community.”
“It’s a kind of unpleasant surprise because we thought the values of this corporation were very clear in terms of access to information.”
Stanislav Shakirov, the chief technical officer of Roskomsvoboda, a Russian open internet group, said he hoped it was a rash decision by Mozilla that will be more carefully examined.
“It’s a kind of unpleasant surprise because we thought the values of this corporation were very clear in terms of access to information, and its policy was somewhat different,” Shakirov said. “And due to these values, it should not be so simple to comply with state censors and fulfill the requirements of laws that have little to do with common sense.”
Developers of digital tools designed to get around censorship began noticing recently that their Firefox add-ons were no longer available in Russia.
On June 8, the developer of Censor Tracker, an add-on for bypassing internet censorship restrictions in Russia and other former Soviet countries, made a post on the Mozilla Foundation’s discussion forums saying that their extension was unavailable to users in Russia.
The developer of another add-on, Runet Censorship Bypass, which is specifically designed to bypass Roskomnadzor censorship, posted in the thread that their extension was also blocked. The developer said they did not receive any notification from Mozilla regarding the block.
Two VPN add-ons, Planet VPN and FastProxy — the latter explicitly designed for Russian users to bypass Russian censorship — are also blocked. VPNs, or virtual private networks, are designed to obscure internet users’ locations by routing users’ traffic through servers in other countries.
The Intercept verified that all four add-ons are blocked in Russia. If the webpage for the add-on is accessed from a Russian IP address, the Mozilla add-on page displays a message: “The page you tried to access is not available in your region.” If the add-on is accessed with an IP address outside of Russia, the add-on page loads successfully.
[…]
According to Mozilla’s Pledge for a Healthy Internet, the Mozilla Foundation is “committed to an internet that includes all the peoples of the earth — where a person’s demographic characteristics do not determine their online access, opportunities, or quality of experience.” Mozilla’s second principle in their manifesto says, “The internet is a global public resource that must remain open and accessible.”
[…]
The same four censorship circumvention add-ons also appear to be available for other web browsers without being blocked by the browsers’ web stores. Censor Tracker, for instance, remains available for the Google Chrome web browser, and the Chrome Web Store page for the add-on works from Russian IP addresses. The same holds for Runet Censorship Bypass, VPN Planet, and FastProxy.
This idealistic commitment Mozilla has is one of the reasons I use Firefox as my standard browser (apart from that it’s a really really good technology; has good addons; is anti-monopoly; doesn’t own the copyright of everything you type in it; doesn’t spy on you; etc), so to see them cave in to a country like Russia is a real disappointment.
It is hard to imagine the world without the Web. Collectively, we routinely access billions of Web pages without thinking about it. But we often take it for granted that the material we want to access will be there, both now and in the future. We all hit the dreaded “404 not found” error from time to time, but merely pass on to other pages. What we tend to ignore is how these online error messages are a flashing warning signal that something bad is happening to the World Wide Web. Just how bad is revealed in a new report from the Pew Research Center, based on an examination of half a million Web pages, which found:
A quarter of all webpages that existed at one point between 2013 and 2023 are no longer accessible, as of October 2023. In most cases, this is because an individual page was deleted or removed on an otherwise functional website.
For older content, this trend is even starker. Some 38% of webpages that existed in 2013 are not available today, compared with 8% of pages that existed in 2023.
This digital decay occurs at slightly different rates for different online material:
23% of news webpages contain at least one broken link, as do 21% of webpages from government sites. News sites with a high level of site traffic and those with less are about equally likely to contain broken links. Local-level government webpages (those belonging to city governments) are especially likely to have broken links.
54% of Wikipedia pages contain at least one link in their “References” section that points to a page that no longer exists.
These figures show that the problem we discussed a few weeks ago – that access to academic knowledge is at risk – is in fact far wider, and applies to just about everything that is online. Although the reasons for material disappearing vary greatly, the key obstacle to addressing that loss is the same across all fields. The copyright industry’s obsessive control of material, and the punitive laws that can be deployed against even the most trivial copyright infringement, mean that routine and multiple backup copies of key or historic online material are rarely made.
The main exception to that rule is the sterling work carried out by the Internet Archive, which was founded by Brewster Kahle, whose Kahle/Austin Foundation supports this blog. At the time of writing the Internet Archive holds copies of an astonishing 866 billion Web pages, many in multiple versions that chart their changes over time. It is a unique and invaluable resource.
It is also being sued by publishers for daring to share in a controlled way some of its holdings. That is, the one bulwark against losing vast swathes of our digital culture is being attacked by an industry that is largely to blame for the problem the Internet Archive is trying to solve. It’s another important reason why we must move away from the copyright system, and nullify the power it has to destroy, rather than create, our culture.
One of the arguments sometimes made in defence of copyright is that without it, creators would be unable to compete with the hordes of copycats that would spring up as soon as their works became popular. Copyright is needed, supporters say, to prevent less innovative creators from producing works that are closely based on new, successful ideas. However, this approach has led to constant arguments and court cases over how close a “closely based” work can be before it infringes on the copyright of others. A good example of this is the 2022 lawsuit involving Ed Sheeran, where is was argued that using just four notes of a scale constituted copyright infringement of someone else’s song employing the same tiny motif. A fascinating new paper looks at things from a different angle. It draws on the idea of “first-mover advantage”, the fact that:
individuals that move to a new market niche early on (“first movers”) obtain advantages that may lead to larger success, compared to those who move to this niche later. First movers enjoy a temporary near-monopoly: since they enter a niche early, they have little to no competition, and so they can charge larger prices and spend more time building a loyal customer base.
The paper explores the idea in detail for the world of music. Here, first-mover advantage means:
The artists and music producers who recognize the hidden potential of a new artistic technique, genre, or style, have bigger chances of reaching success. Having an artistic innovation that your competitors do not have or cannot quickly acquire may become advantageous on the winner-take-all artistic market.
Analysing nearly 700,000 songs across 110 different musical genres, the researchers found evidence that first-mover advantage was present in 91 of the genres. The authors point out that there is also anecdotal evidence of first-mover advantage in other arts:
For example, Agatha Christie—one of the recognized founders of “classical” detective novel—is also one of the best-selling authors ever. Similarly, William Gibson’s novel Neuromancer—a canonical work in the genre of cyberpunk—is also one of the earliest books in this strand of science fiction. In films, the cult classic The Blair Witch Project is the first recognized member of the highly successful genre of found-footage horror fiction.
Although copyright may be present, first-mover advantage does not require it to operate – it is simply a function of being early with a new idea, which means that competition is scarce or non-existent. If further research confirms the wider presence of first-mover advantage in the creative world – for example, even where sharing-friendly CC licences are used – it will knock down yet another flimsy defence of copyright’s flawed and outdated intellectual monopoly
[…] medicine quite literally regrows teeth and was developed by a team of Japanese researchers, as reported by New Atlas. The research has been led by Katsu Takahashi, head of dentistry and oral surgery at Kitano Hospital. The intravenous drug deactivates the uterine sensitization-associated gene-1 (USAG-1) protein that suppresses tooth growth. Blocking USAG-1 from interacting with other proteins triggers bone growth and, voila, you got yourself some brand-new chompers. Pretty cool, right?
Human trials start in September, but the drug has been highly successful when treating ferrets and mice and did its job with no serious side effects. Of course, the usual caveat applies. Humans are not mice or ferrets, though researchers seem confident that it’ll work on homo sapiens. This is due to a 97 percent similarity in how the USAG-1 protein works when comparing humans to other species.
September’s clinical trial will include adults who are missing at least one molar but there’s a secondary trial coming aimed at children aged two to seven. The kids in the second trial will all be missing at least four teeth due to congenital tooth deficiency. Finally, a third trial will focus on older adults who are missing “one to five permanent teeth due to environmental factors.”
Takahashi and his fellow researchers are so optimistic about this drug that they predict the medicine will be available for everyday consumers by 2030. So in six years we can throw our toothbrushes away and eat candy bars all day and all night without a care in the world (don’t actually do that.)
While this is the first drug that can fully regrow missing teeth, the science behind it builds on top of years of related research. Takahashi, after all, has been working on this since 2005. Recent advancements in the field include regenerative tooth fillings to repair diseased teeth and stem cell technology to regrow the dental tissue of children.
Nearly a third of U.S. adults have tattoos, so plenty of you listeners can probably rattle off the basic guidelines of tattoo safety: Make sure you go to a reputable tattoo artist who uses new, sterile needles. Stay out of the ocean while you’re healing so you don’t pick up a smidgen of flesh-eating bacteria. Gently wash your new ink with soap and water, avoid sun exposure and frequently apply an unscented moisturizer—easy-peasy.
But body art enthusiasts might face potential risks from a source they don’t expect: tattoo inks themselves. Up until relatively recently tattoo inks in the U.S. were totally unregulated. In 2022 the federal government pulled tattoo inks under the regulatory umbrella of cosmetics, which means the Food and Drug Administration can oversee these products. But now researchers are finding that many commercial inks contain ingredients they’re not supposed to. Some of these additives are simply compounds that should be listed on the packaging and aren’t. But others could pose a risk to consumers.
For Science Quickly, I’m Rachel Feltman. I’m joined today by John Swierk, an assistant professor of chemistry at Binghamton University, State University of New York. His team is trying to figure out exactly what goes into each vial of tattoo ink—and how tattoos actually work in the first place—to help make body art safer, longer-lasting and maybe even cooler.
[…]
one of the areas we got really interested in was trying to understand why light causes tattoos to fade. This is a huge question when you think about something with laser tattoo removal, where you’re talking about an industry on the scale of $1 billion a year.
And it turns out we really don’t understand that process. And so starting to look at how the tattoo pigments change when you expose them to light, what that might be doing in the skin, then led us to a lot of other questions about tattoos that we realized weren’t well understood—even something as simple as what’s actually in tattoo ink.
[…]
recently we’ve been looking at commercial tattoo inks and sort of surprised to find that in the overwhelming majority of them, we’re seeing things that are not listed as part of the ingredients….Now that doesn’t necessarily mean the things that are in these inks are unsafe, but it does cause a huge problem if you want to try to understand something about the safety of tattoos.
[…]
I think most people would agree that it would be great to know that tattoo inks are safe [and] being made safely, you know? And of course, that’s not unique to tattoo inks; cosmetics and supplements have a lot of similar problems that we need to work on.
But, if we’re going to get a better grasp on the chemistry and even the immunology of tattoos, that’s not just going to help us make them safer but, you know, potentially improve healing, appearance, longevity.
I mean, I think about that start-up that promised “ephemeral tattoos” that now folks a few years later are coming out and saying, “These tattoos have not gone away,” and thinking about how much potential there is for genuine innovation if we can start to answer some of these questions.
[…]
we can start to think about designing new pigments that might have better colorfastness, less reactivity, less sort of bleeding of the lines, right, over time. But all of those things can only happen if we actually understand tattoos, and we really just don’t understand them that well at the moment.
[…]
We looked at 54 inks, and of the 54, 45 had what we consider to be major discrepancies—so these were either unlisted pigments, unlisted additives.
And that was really concerning to us, right? You’re talking about inks coming from major, global, industry-leading manufacturers all the way down to smaller, more niche inks—that there were problems across the board.
So we found things like incorrect pigments being listed. We found issues of some major allergens being used—these aren’t necessarily compounds that are specifically toxic, but to some people they can generate a really pronounced allergic response.
And a couple of things: we found an antibiotic that’s most commonly used for urinary tract infections.
We found a preservative that the FDA has cautioned nursing mothers against, you know, having exposure to—so things that at a minimum, need to be disclosed so that consumers could make informed choices.
[…]
if somebody’s thinking about getting a tattoo, they should be working with an artist who is experienced, who has apprenticed under experienced artists, who is really following best practices in terms of sanitation, aftercare, things like that. That’s where we know you can have a problem. Beyond that, I think it’s a matter of how comfortable you are with some degree of risk.
The point I always really want to emphasize is that, you know, our work isn’t saying anything about whether tattoos are safe or not.
It’s the first step in that process. Just because we found some stuff in the inks doesn’t mean that you shouldn’t get a tattoo or that you have a new risk for skin cancer or something like that…. it’s that this is the process of how science grows, right—that we have to start understanding the basics and the fundamentals so that we can build the next questions on top of that.
And our understanding of tattoos in the body is still at such an early level that we don’t really even understand what the risk factors would be, “What should we be looking for?”
So I think it’s like with anything in life: if you’re comfortable with a degree of risk, then, yeah, go ahead and get the tattoo. People get tattoos for lots of reasons that are important and meaningful and very impactful in a positive way in their life. And I think a concern over a hypothetical risk is probably not worth the potential positives of getting a tattoo.
We know that light exposure— particularly the sunlight—is not great for the tattoo, and if we have concerns about long-term pigment breakdown, ultraviolet light is probably going to enhance that, so keeping your tattoo covered, using sunscreen when you can’t keep it covered—that’s probably very important. If you’re really concerned about the risk, we can think about the size of the tattoo. So somebody with a relatively small piece of line art on their back is in a very different potential risk category than somebody who is fully sleeved and, you know, covered from, say, neck to ankle in tattoos.
And again we’re not saying that either those people have a significant risk that they need to be worried about, but if somebody is concerned, the person with the small line art on the back is much less likely to have to worry about the risk than somebody with a huge tattoo.
We also know that certain colors, like yellow in particular, fade much more readily. That suggests that those pigments are interacting with the body a lot more.
Staying away from bright colors and focusing on black inks might be a more prudent option there, but again, right, a lot of these are hypothetical and we don’t want to alarm people or scare them.
[…]
We’re also still working on understanding what tattoo pigments break down into.
We really don’t understand a lot about laser tattoo removal, and if there is some aspect of tattooing that gives me pause, it’s probably that part. It’s a very reasonable concern, I think, that you may have pigments that are entirely safe in the skin, but once you start zapping them with high-powered lasers, we don’t know what you do to the chemistry, and so that could change the dynamic a lot. And so we’re trying to figure out how to do that and, I think, making some progress there. And then the last area—which is, is new to us but kind of fun—is actually just looking at the biomechanics of tattooing. You would think that we’d really understand how the ink goes into the skin, how it stays in the skin, but the picture there is a little bit hazy
[…]
One of the interesting things, when you talk to ink manufacturers and artists, is that they sort of have this intuitive feel for … sort of what the viscosity of the ink should be like and how much pigment is in there but can’t necessarily articulate why a particular viscosity is good or why a particular pigment loading is good. And so we think if we understand something about the process by which the ink goes…and so we think understanding the biomechanics could really open some interesting possibilities and lead to better, more interesting tattoos down the road as well.
An unknown financially motivated crime crew has swiped a “significant volume of records” from Snowflake customers’ databases using stolen credentials, according to Mandiant.
“To date, Mandiant and Snowflake have notified approximately 165 potentially exposed organizations,” the Google-owned threat hunters wrote on Monday, and noted they track the perps as “UNC5537.”
“Mandiant is investigating the possibility that a member of UNC5537 collaborated with UNC3944 on at least one past intrusion in the past six months, but we don’t have enough data to confidently link UNC5537 to a broader group at this time,” senior threat analyst Austin Larsen told The Register.
Mandiant – one of the incident response firms hired by Snowflake to help investigate its recent security incident – also noted that there’s no evidence a breach of Snowflake’s own enterprise environment was to blame for its customers’ breaches.
“Instead, every incident Mandiant responded to associated with this campaign was traced back to compromised customer credentials,” the Google-owned threat hunters confirmed.
The earliest detected attack against a Snowflake customer instance happened on April 14. Upon investigating that breach, Mandiant says it determined that UNC5537 used legitimate credentials – previously stolen using infostealer malware – to break into the victim’s Snowflake environment and exfiltrate data. The victim did not have multi-factor authentication turned on.
About a month later, after uncovering “multiple” Snowflake customer compromises, Mandiant contacted the cloud biz and the two began notifying affected organizations. By May 24 the criminals had begun selling the stolen data online, and on May 30 Snowflake issued its statement about the incidents.
After gaining initial access – which we’re told occurred through the Snowflake native web-based user interface or a command-line-interface running on Windows Server 2002 – the criminals used a horribly named utility, “rapeflake,” which Mandiant has instead chosen to track as “FROSTBITE.”
UNC5537 has used both .NET and Java versions of this tool to perform reconnaissance against targeted Snowflake customers, allowing the gang to identify users, their roles, and IP addresses.
The crew also sometimes uses DBeaver Ultimate – a publicly available database management utility – to query Snowflake instances.
Several of the initial compromises occurred on contractor systems that were being used for both work and personal activities.
“These devices, often used to access the systems of multiple organizations, present a significant risk,” Mandiant researchers wrote. “If compromised by infostealer malware, a single contractor’s laptop can facilitate threat actor access across multiple organizations, often with IT and administrator-level privileges.”
All of the successful intrusions had three things in common, according to Mandiant. First, the victims didn’t use MFA.
Second, the attackers used valid credentials, “hundreds” of which were stolen thanks to infostealer infections – some as far back as 2020. Common variants used included VIDAR, RISEPRO, REDLINE, RACOON STEALER, LUMMA and METASTEALER. But even in these years-old thefts, the credentials had not been updated or rotated.
Almost 80 percent of the customer accounts accessed by UNC5537 had prior credential exposure, we’re told.
Finally, the compromised accounts did not have network allow-lists in place. So if you are a Snowflake customer, it’s time to get a little smarter.
Oddly enough, they don’t mention the Ticketmaster 560m+ account hack confirmed in what seems to be a spree hitting Snowflake customers considering the size of the hack! Also, oddly enough, when you Google Snowflake, you get the corporate page, some wikipedia entries, but not very much about the hack. Considering the size and breadth of the problem, this is surprising. But perhaps not, considering it’s a part of Google.
A Finnish startup called Flow Computing is making one of the wildest claims ever heard in silicon engineering: by adding its proprietary companion chip, any CPU can instantly double its performance, increasing to as much as 100x with software tweaks.
If it works, it could help the industry keep up with the insatiable compute demand of AI makers.
Flow is a spinout of VTT, a Finland state-backed research organization that’s a bit like a national lab. The chip technology it’s commercializing, which it has branded the Parallel Processing Unit, is the result of research performed at that lab (though VTT is an investor, the IP is owned by Flow).
The claim, Flow is first to admit, is laughable on its face. You can’t just magically squeeze extra performance out of CPUs across architectures and code bases. If so, Intel or AMD or whoever would have done it years ago.
But Flow has been working on something that has been theoretically possible — it’s just that no one has been able to pull it off.
Central Processing Units have come a long way since the early days of vacuum tubes and punch cards, but in some fundamental ways they’re still the same. Their primary limitation is that as serial rather than parallel processors, they can only do one thing at a time. Of course, they switch that thing a billion times a second across multiple cores and pathways — but these are all ways of accommodating the single-lane nature of the CPU. (A GPU, in contrast, does many related calculations at once but is specialized in certain operations.)
“The CPU is the weakest link in computing,” said Flow co-founder and CEO Timo Valtonen. “It’s not up to its task, and this will need to change.”
CPUs have gotten very fast, but even with nanosecond-level responsiveness, there’s a tremendous amount of waste in how instructions are carried out simply because of the basic limitation that one task needs to finish before the next one starts. (I’m simplifying here, not being a chip engineer myself.)
What Flow claims to have done is remove this limitation, turning the CPU from a one-lane street into a multi-lane highway. The CPU is still limited to doing one task at a time, but Flow’s PPU, as they call it, essentially performs nanosecond-scale traffic management on-die to move tasks into and out of the processor faster than has previously been possible.
[…]
This type of thing isn’t brand new, says Valtonen. “This has been studied and discussed in high-level academia. You can already do parallelization, but it breaks legacy code, and then it’s useless.”
So it could be done. It just couldn’t be done without rewriting all the code in the world from the ground up, which kind of makes it a non-starter. A similar problem was solved by another Nordic compute company, ZeroPoint, which achieved high levels of memory compression while keeping data transparency with the rest of the system.
Flow’s big achievement, in other words, isn’t high-speed traffic management, but rather doing it without having to modify any code on any CPU or architecture that it has tested.
[…]
Therein lies the primary challenge to Flow’s success as a business: Unlike a software product, Flow’s tech needs to be included at the chip-design level, meaning it doesn’t work retroactively, and the first chip with a PPU would necessarily be quite a ways down the road. Flow has shown that the tech works in FPGA-based test setups, but chipmakers would have to commit quite a lot of resources to see the gains in question.
[…]
Further performance gains come from refactoring and recompiling software to work better with the PPU-CPU combo. Flow says it has seen increases up to 100x with code that’s been modified (though not necessarily fully rewritten) to take advantage of its technology. The company is working on offering recompilation tools to make this task simpler for software makers who want to optimize for Flow-enabled chips.
Analyst Kevin Krewell from Tirias Research, who was briefed on Flow’s tech and referred to as an outside perspective on these matters, was more worried about industry uptake than the fundamentals.
[…]
Flow is just now emerging from stealth, with €4 million (about $4.3 million) in pre-seed funding led by Butterfly Ventures, with participation from FOV Ventures, Sarsia, Stephen Industries, Superhero Capital and Business Finland.
Hackers working for the Chinese government gained access to more than 20,000 VPN appliances sold by Fortinet using a critical vulnerability that the company failed to disclose for two weeks after fixing it, Netherlands government officials said.
The vulnerability, tracked as CVE-2022-42475, is a heap-based buffer overflow that allows hackers to remotely execute malicious code. It carries a severity rating of 9.8 out of 10. A maker of network security software, Fortinet silently fixed the vulnerability on November 28, 2022, but failed to mention the threat until December 12 of that year, when the company said it became aware of an “instance where this vulnerability was exploited in the wild.” On January 11, 2023—more than six weeks after the vulnerability was fixed—Fortinet warned a threat actor was exploiting it to infect government and government-related organizations with advanced custom-made malware.
Enter CoatHanger
The Netherlands officials first reported in February that Chinese state hackers had exploited CVE-2022-42475 to install an advanced and stealthy backdoor tracked as CoatHanger on Fortigate appliances inside the Dutch Ministry of Defense. Once installed, the never-before-seen malware, specifically designed for the underlying FortiOS operating system, was able to permanently reside on devices even when rebooted or receiving a firmware update. CoatHanger could also escape traditional detection measures, the officials warned. The damage resulting from the breach was limited, however, because infections were contained inside a segment reserved for non-classified uses.
On Monday, officials with the Military Intelligence and Security Service (MIVD) and the General Intelligence and Security Service in the Netherlands said that to date, Chinese state hackers have used the critical vulnerability to infect more than 20,000 FortiGate VPN appliances sold by Fortinet. Targets include dozens of Western government agencies, international organizations, and companies within the defense industry.
“Since then, the MIVD has conducted further investigation and has shown that the Chinese cyber espionage campaign appears to be much more extensive than previously known,” Netherlands officials with the National Cyber Security Center wrote. “The NCSC therefore calls for extra attention to this campaign and the abuse of vulnerabilities in edge devices.”
Monday’s report said that exploitation of the vulnerability started two months before Fortinet first disclosed it and that 14,000 servers were backdoored during this zero-day period. The officials warned that the Chinese threat group likely still has access to many victims because CoatHanger is so hard to detect and remove.
[…]
Fortinet’s failure to timely disclose is particularly acute given the severity of the vulnerability. Disclosures are crucial because they help users prioritize the installation of patches. When a new version fixes minor bugs, many organizations often wait to install it. When it fixes a vulnerability with a 9.8 severity rating, they’re much more likely to expedite the update process. Given the vulnerability was being exploited even before Fortinet fixed it, the disclosure likely wouldn’t have prevented all of the infections, but it stands to reason it could have stopped some.
Fortinet officials have never explained why they didn’t disclose the critical vulnerability when it was fixed. They have also declined to disclose what the company policy is for the disclosure of security vulnerabilities. Company representatives didn’t immediately respond to an email seeking comment for this post.
After having upgraded to a graphics card that can handle 4k and 120Hz, I spent a LOT of time figuring out why I couldn’t find (or create) that mode on my PC. Support first told me the monitor had 110Hz, but that (or lower) didn’t work either. Support then told me – nope: it’s only 60 Hz.
It turns out that this is indeed buried in the manual on page 15.
The customer support rep was sorry for me, but that’s it. There is no way to take a company like LG to task apart from writing about it.
Possibly I haven’t learnt from my own posts: Don’t Buy an HDMI 2.1 TV Before You Read the Fine Print – The HDMI 2.1 specification is crazy and as long as any one of the components in the system is 2.1 compatible the rest don’t have to be, but you still get the label.
Billions of records detailing people’s personal information may soon be dumped online after being allegedly obtained from a Florida firm that handles background checks and other requests for folks’ private info.
A criminal gang that goes by the handle USDoD put the database up for sale for $3.5 million on an underworld forum in April, and rather incredibly claimed the trove included 2.9 billion records on all US, Canadian, and British citizens. It’s believed one or more miscreants using the handle SXUL was responsible for the alleged exfiltration, who passed it onto USDoD, which is acting as a broker.
The pilfered information is said to include individuals’ full names, addresses, and address history going back at least three decades, social security numbers, and people’s parents, siblings, and relatives, some of whom have been dead for nearly 20 years. According to USDoD, this info was not scraped from public sources, though there may be duplicate entries for people in the database.
Fast forward to this month, and the infosec watchers at VX-Underground say they’ve not only been able to view the database and verify that at least some of its contents are real and accurate, but that USDoD plans to leak the trove. Judging by VX-Underground’s assessment, the 277.1GB file contains nearly three billion records on people who’ve at least lived in the United States – so US citizens as well as, say, Canadians and Brits.
This info was allegedly stolen or otherwise obtained from National Public Data, a small information broker based in Coral Springs that offers API lookups to other companies for things like background checks. The biz did not respond to The Register‘s inquiries.
There is a small silver lining, according to the VX team: “The database DOES NOT contain information from individuals who use data opt-out services. Every person who used some sort of data opt-out service was not present.” So, we guess this is a good lesson in opting out.
USDoD is the same crew that previously peddled a 3GB-plus database from TransUnion containing financial information on 58,505 people.
And last September, the same criminals touted personal information belonging to 3,200 Airbus vendors after the aerospace giant fell victim to an intrusion
Computer hardware manufacturer Cooler Master has suffered a data breach after a threat actor breached the company’s website and claimed to steal the Fanzone member information of 500,000 customers.
Cooler Master is a hardware manufacturer based in Taiwan that is known for its computer cases, cooling devices, gaming chairs, and other computer peripherals.
Yesterday, a threat actor by the alias ‘Ghostr’ contacted BleepingComputer and claimed to have stolen 103 GB of data from Cooler Master on May 18th, 2024.
“This data breach included cooler master corporate, vendor, sales, warranty, inventory and hr data as well as over 500,000 of their fanzone members personal information, including name, address, date of birth, phone, email + plain unencrypted credit card information containing name, credit card number, expiry and 3 digits cc code,” the threat actor told BleepingComputer.
Cooler Master’s Fanzone site is used to register a product’s warranty, submit return merchandise authorization (RMA) requests, contact support, and register for news updates.
In a conversation with BleepingComputer, Ghostr told BleepingComputer that the data was stolen by breaching one of the company’s front-facing websites, allowing them to download numerous databases, including the one containing Fanzone information.
The threat actor said they attempted to contact the company for payment not to leak or sell the data, but Cooler Master did not respond.
However, they did share a link to a small sample of allegedly stolen data in the form of comma-separated values files (CSV) that appear to have been exported from Cooler Master’s Fanzone site.
Samples of stolen data Source: BleepingComputer
These CSV files contain a wide variety of data, including product, vendor, customer, and employee information.
One of the files contains approximately 1,000 records of what appear to be recent customer support tickets and RMA requests, which include customers’ names, email addresses, date of birth, physical addresses, phone numbers, and IP addresses.
BleepingComputer has confirmed with numerous Cooler Master customers in this file that the listed data is correct and that they opened an RMA or support ticket on the date specified in the leaked sample.
The Japanese government is pushing ahead with a plan to make Japan’s publicly funded research output free to read. From a report: In June, the science ministry will assign funding to universities to build the infrastructure needed to make research papers free to read on a national scale. The move follows the ministry’s announcement in February that researchers who receive government funding will be required to make their papers freely available to read on the institutional repositories from January 2025. The Japanese plan “is expected to enhance the long-term traceability of research information, facilitate secondary research and promote collaboration,” says Kazuki Ide, a health-sciences and public-policy scholar at Osaka University in Suita, Japan, who has written about open access in Japan.
The nation is one of the first Asian countries to make notable advances towards making more research open access (OA) and among the first countries in the world to forge a nationwide plan for OA. The plan follows in the footsteps of the influential Plan S, introduced six years ago by a group of research funders in the United States and Europe known as cOAlition S, to accelerate the move to OA publishing. The United States also implemented an OA mandate in 2022 that requires all research funded by US taxpayers to be freely available from 2026. When the Ministry of Education, Culture, Sports, Science and Technology (MEXT) announced Japan’s pivot to OA in February, it also said that it would invest around $63 million to standardize institutional repositories — websites dedicated to hosting scientific papers, their underlying data and other materials — ensuring that there will be a mechanism for making research in Japan open.
Google has accidentally collected childrens’ voice data, leaked the trips and home addresses of car pool users, and made YouTube recommendations based on users’ deleted watch history, among thousands of other employee-reported privacy incidents, according to a copy of an internal Google database which tracks six years worth of potential privacy and security issues obtained by 404 Media. From the report: Individually the incidents, most of which have not been previously publicly reported, may only each impact a relatively small number of people, or were fixed quickly. Taken as a whole, though, the internal database shows how one of the most powerful and important companies in the world manages, and often mismanages, a staggering amount of personal, sensitive data on people’s lives.
The data obtained by 404 Media includes privacy and security issues that Google’s own employees reported internally. These include issues with Google’s own products or data collection practices; vulnerabilities in third party vendors that Google uses; or mistakes made by Google staff, contractors, or other people that have impacted Google systems or data. The incidents include everything from a single errant email containing some PII, through to substantial leaks of data, right up to impending raids on Google offices. When reporting an incident, employees give the incident a priority rating, P0 being the highest, P1 being a step below that. The database contains thousands of reports over the course of six years, from 2013 to 2018. In one 2016 case, a Google employee reported that Google Street View’s systems were transcribing and storing license plate numbers from photos. They explained that Google uses an algorithm to detect text in Street View imagery.
Adobe has decided that if you use its software, it can re-use anything you create. Considering you pay to use the software, that’s a bit grating.
4.2 Licenses to Your Content. Solely for the purposes of operating or improving the Services and Software, you grant us a non-exclusive, worldwide, royalty-free sublicensable, license, to use, reproduce, publicly display, distribute, modify, create derivative works based on, publicly perform, and translate the Content. For example, we may sublicense our right to the Content to our service providers or to other users to allow the Services and Software to operate as intended, such as enabling you to share photos with others. Separately, section 4.6 (Feedback) below covers any Feedback that you provide to us.
Cloud storage provider Snowflake said that accounts belonging to multiple customers have been hacked after threat actors obtained credentials through info-stealing malware or by purchasing them on online crime forums.
Ticketmaster parent Live Nation—which disclosed Friday that hackers gained access to data it stored through an unnamed third-party provider—told TechCrunch the provider was Snowflake. The live-event ticket broker said it identified the hack on May 20, and a week later, a “criminal threat actor offered what it alleged to be Company user data for sale via the dark web.”
Ticketmaster is one of six Snowflake customers to be hit in the hacking campaign, said independent security researcher Kevin Beaumont, citing conversations with people inside the affected companies. Australia’s Signal Directorate said Saturday it knew of “successful compromises of several companies utilizing Snowflake environments.” Researchers with security firm Hudson Rock said in a now-deleted post that Santander, Spain’s biggest bank, was also hacked in the campaign. The researchers cited online text conversations with the threat actor. Last month, Santander disclosed a data breach affecting customers in Chile, Spain, and Uruguay.
“The tl;dr of the Snowflake thing is mass scraping has been happening, but nobody noticed, and they’re pointing at customers for having poor credentials,” Beaumont wrote on Mastodon. “It appears a lot of data has gone walkies from a bunch of orgs.”
Word of the hacks came weeks after a hacking group calling itself ShinyHunters took credit for breaching Santander and Ticketmaster and posted data purportedly belonging to both as evidence. The group took to a Breach forum to seek $2 million for the Santander data, which it said included 30 million customer records, 6 million account numbers, and 28 million credit card numbers. It sought $500,000 for the Ticketmaster data, which the group claimed included full names, addresses, phone numbers, and partial credit card numbers for 560 million customers.
Enlarge/ Post by ShinyHunters seeking $2 million for Santander data.
Enlarge/ Post by ShinyHunters seeking $500,000 for Ticketmaster data.
Beaumont didn’t name the group behind the attacks against Snowflake customers but described it as “a teen crimeware group who’ve been active publicly on Telegram for a while and regularly relies on infostealer malware to obtain sensitive credentials.
The group has been responsible for hacks on dozens of organizations, with a small number of them including:
According to Snowflake, the threat actor used already compromised account credentials in the campaign against its customers. Those accounts weren’t protected by multifactor authentication (MFA).
Snowflake also said that the threat actor used compromised credentials to a former employee account that wasn’t protected by MFA. That account, the company said, was created for demonstration purposes.
“It did not contain sensitive data,” Snowflake’s notification stated. “Demo accounts are not connected to Snowflake’s production or corporate systems.”
The company urges all customers to ensure all their accounts are protected with MFA. The statement added that customers should also check their accounts for signs of compromise using these indicators.
“Throughout the course of our ongoing investigation, we have promptly informed the limited number of customers who we believe may have been impacted,” the company said in the post.
Snowflake and the two security firms it has retained to investigate the incident—Mandiant and Crowdstrike—said they have yet to find any evidence the breaches are a result of a “vulnerability, misconfiguration, or breach of Snowflake’s platform.” But Beaumont said the cloud provider shares some of the responsibility for the breaches because setting up MFA on Snowflake is too cumbersome. He cited the breach of the former employee’s demo account as support.
“They need to, at an engineering and secure by design level, go back and review how authentication works—as it’s pretty transparent that given the number of victims and scale of the breach that the status quo hasn’t worked,” Beaumont wrote. “Secure authentication should not be optional. And they’ve got to be completely transparent about steps they are taking off the back of this incident to strengthen things.”
If you contact Spotify’s customer service with a valid receipt, the company will refund your Car Thing purchase. That’s the latest development reported by Engadget. When Spotify first announced that it would brick every Car Thing device on December 9, 2024, it said that it wouldn’t offer owners any subscription credit or automatic refund. From the report: Spotify has taken some heat for its announcement last week that it will brick every Car Thing device on December 9, 2024. The company described its decision as “part of our ongoing efforts to streamline our product offerings” (read: cut costs) and that it lets Spotify “focus on developing new features and enhancements that will ultimately provide a better experience to all Spotify users.”
TechCrunch reports that Gen Z users on TikTok have expressed their frustration in videos, while others have complained directed toward Spotify in DMs on X (Twitter) and directly through customer support. Some users claimed Spotify’s customer service agents only offered several months of free Premium access, while others were told nobody was receiving refunds. It isn’t clear if any of them contacted them after last Friday when it shifted gears on refunds.
Others went much further. Billboard first reported on a class-action lawsuit filed in the US District Court for the Southern District of New York on May 28. The suit accuses Spotify of misleading Car Thing customers by selling a $90 product that would soon be obsolete without offering refunds, which sounds like a fair enough point. It’s worth noting that, according to Spotify, it began offering the refunds last week, while the lawsuit was only filed on Tuesday. If the company’s statement about refunds starting on May 24 is accurate, the refunds aren’t a direct response to the legal action. (Although it’s possible the company began offering them in anticipation of lawsuits.)Editor’s note: As a disgruntled Car Thing owner myself, I can confirm that Spotify is approving refund requests. You’ll just have to play the waiting game to get through to a Spotify Advisor and their “team” that approves these requests. You may have better luck emailing customer service directly at support@spotify.com.


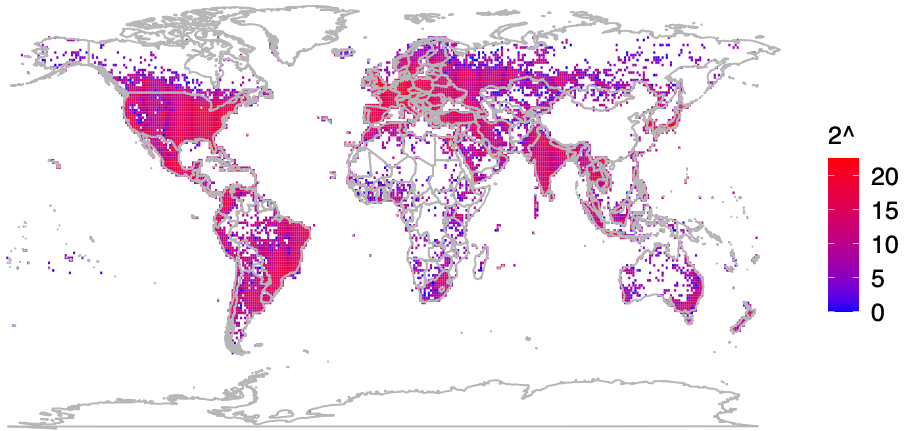
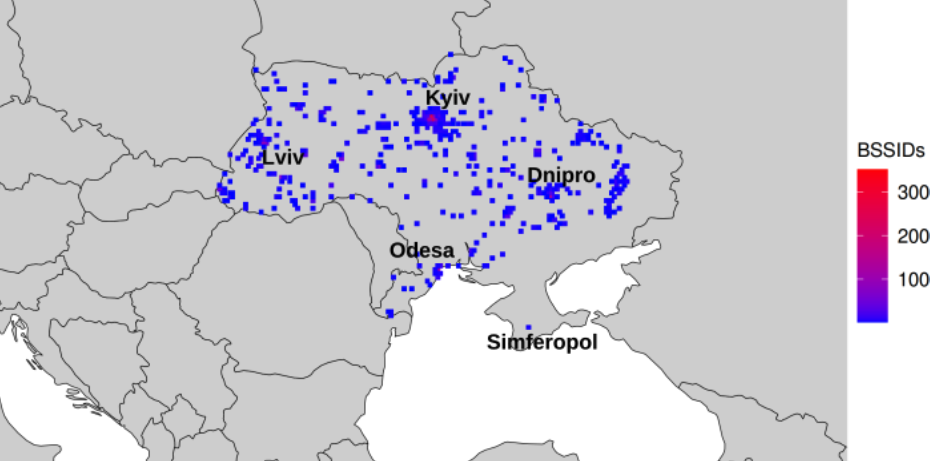
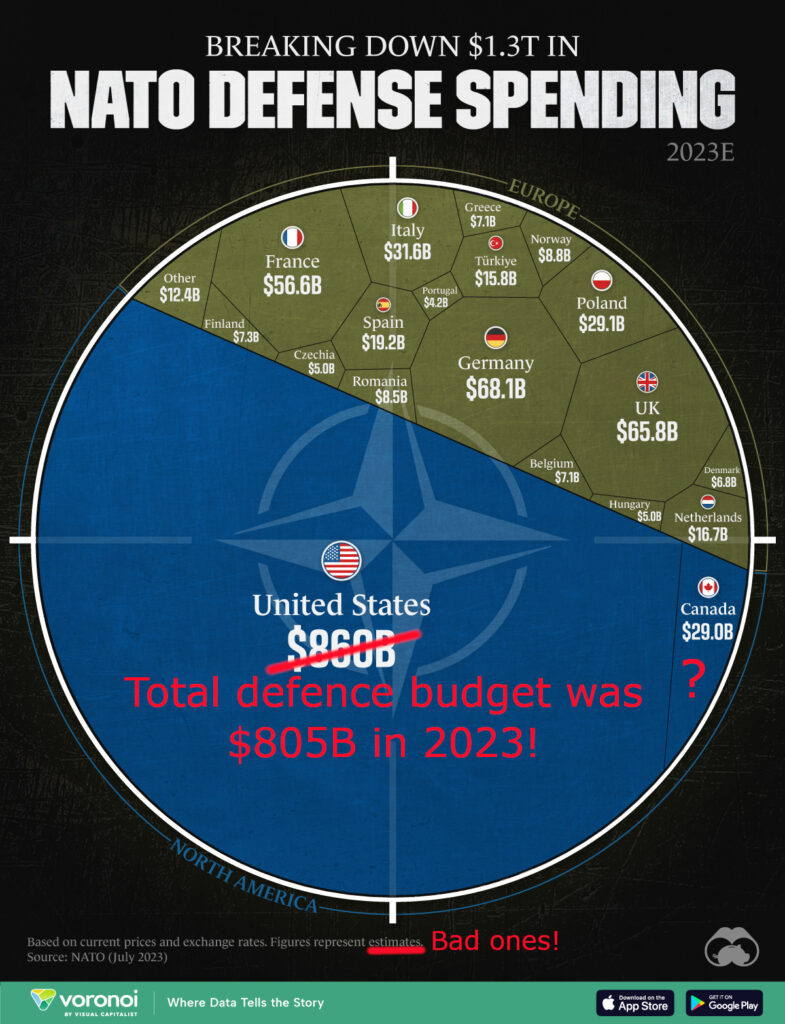
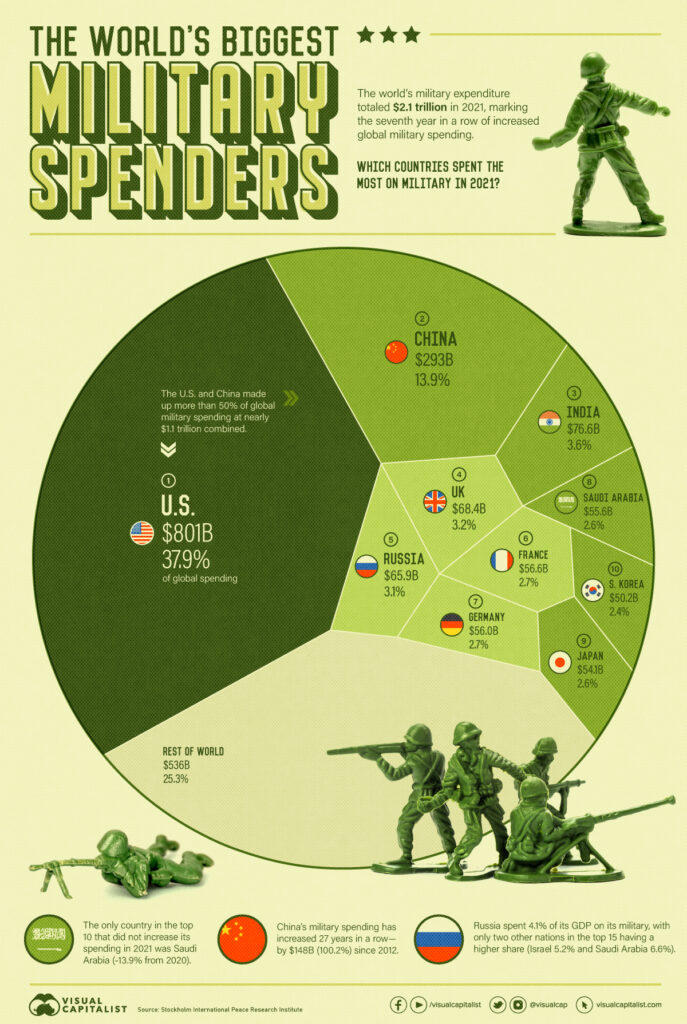
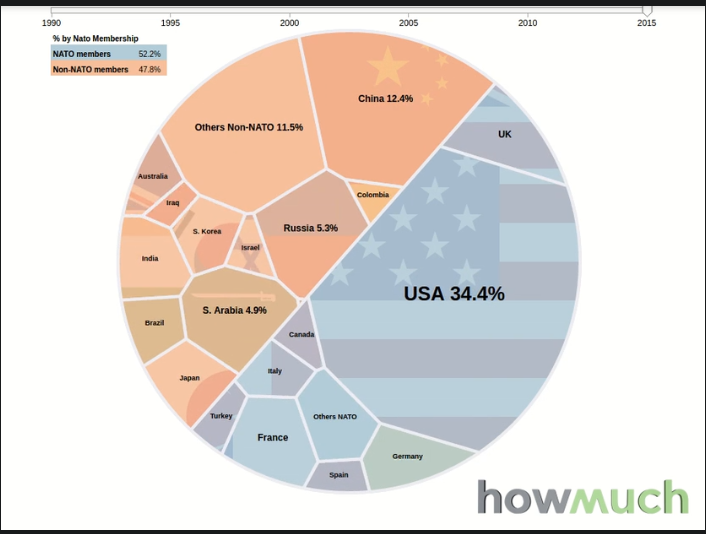
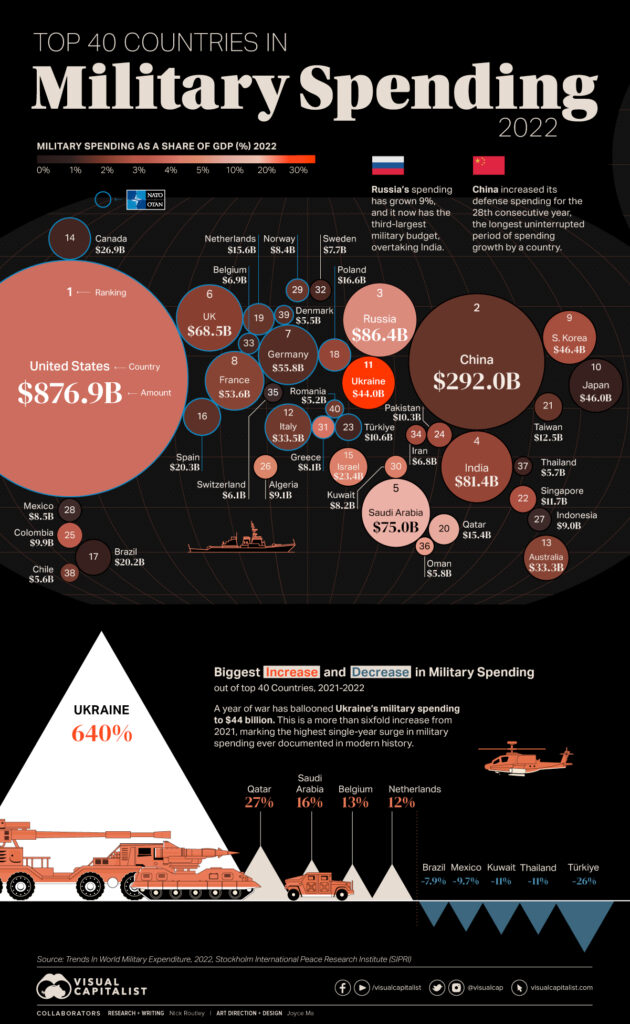
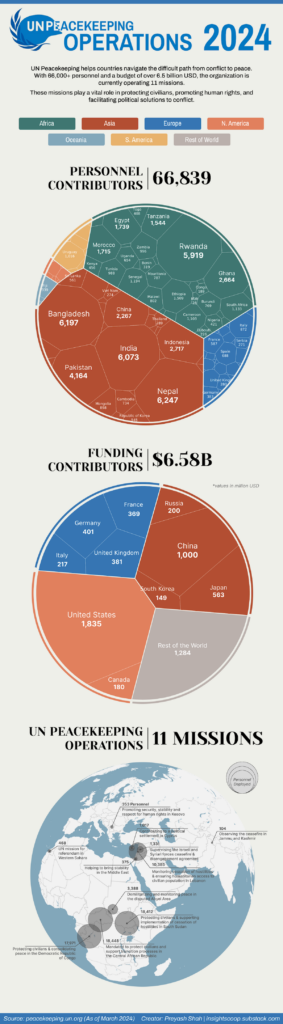
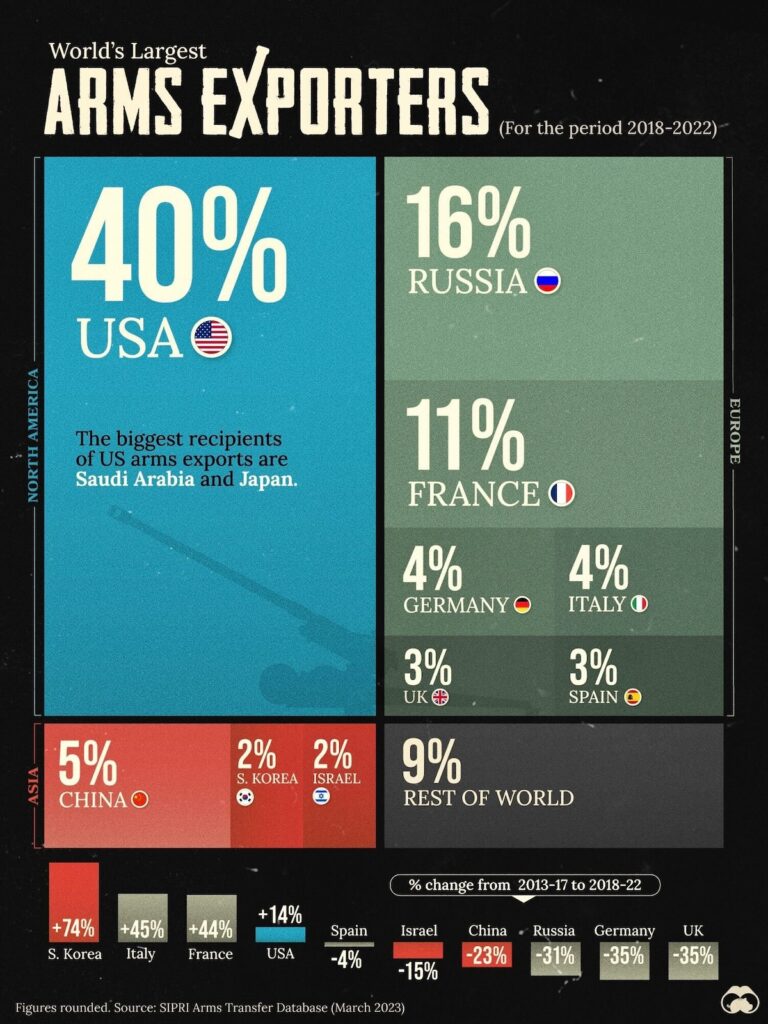
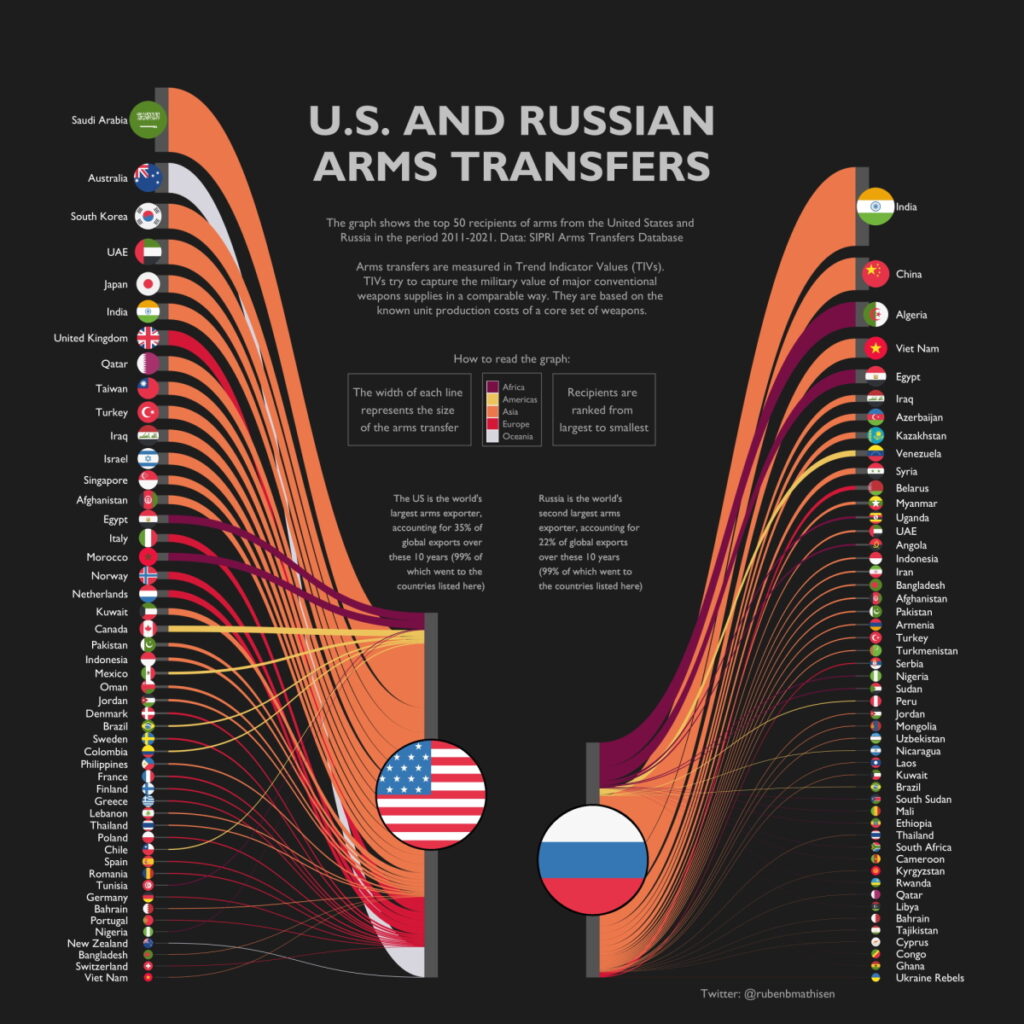
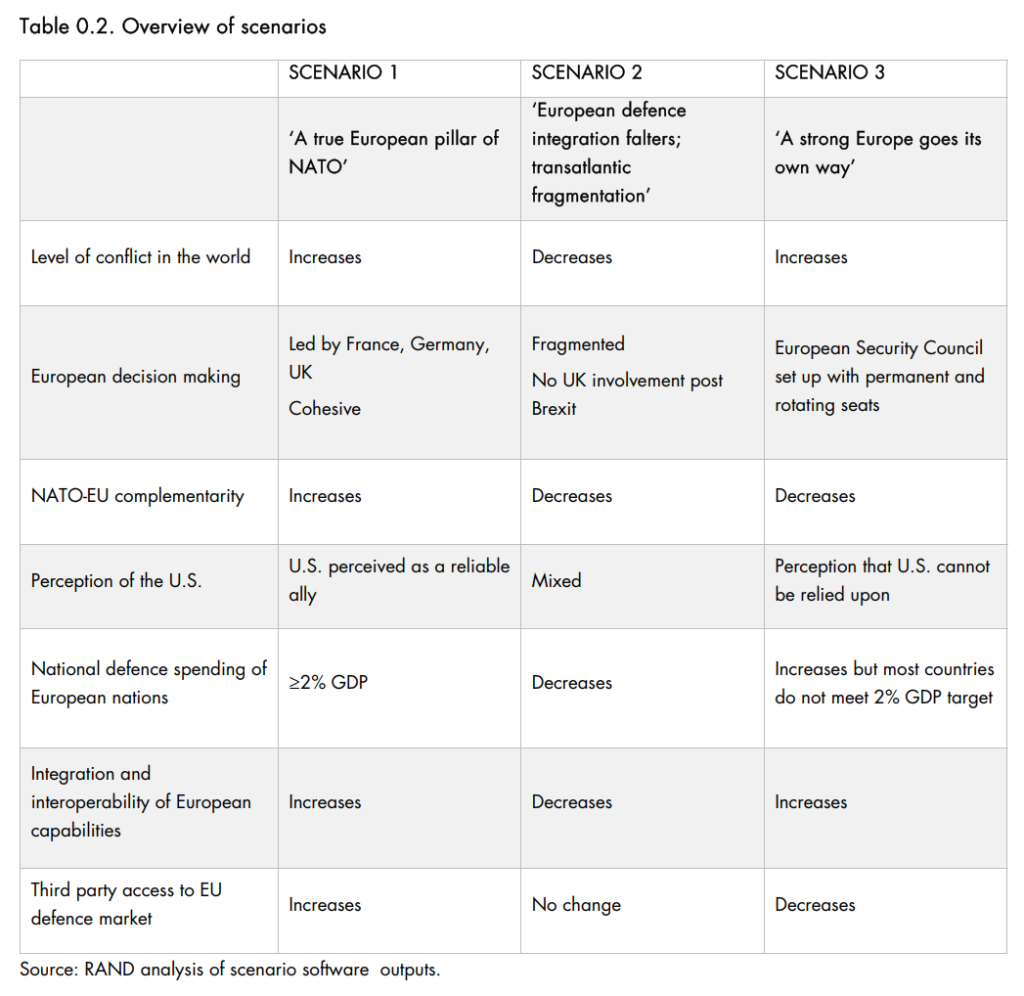
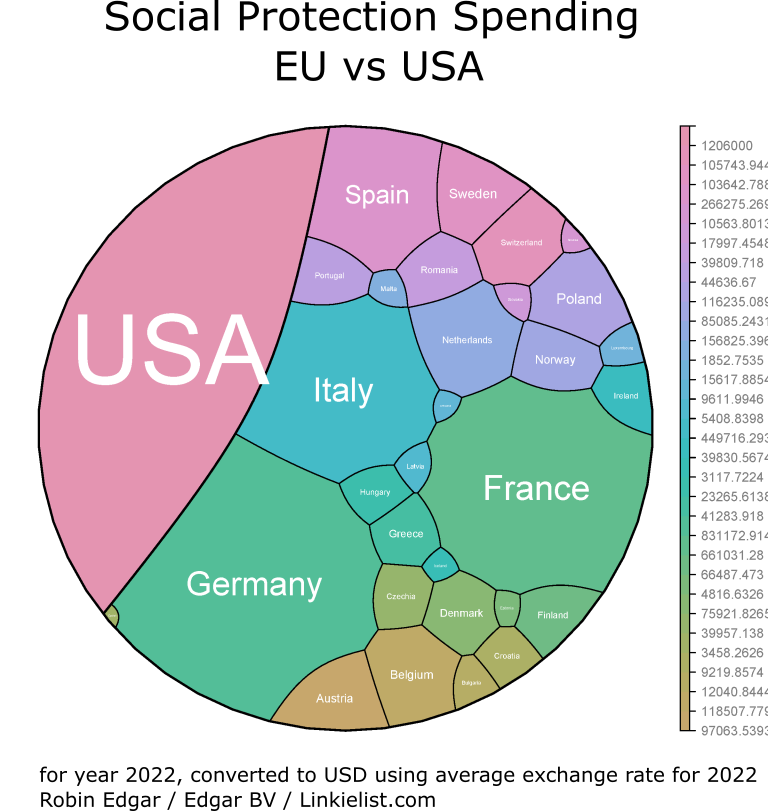







 Cloud storage provider Snowflake said that accounts belonging to multiple customers have been hacked after threat actors obtained credentials through info-stealing malware or by purchasing them on online crime forums.
Cloud storage provider Snowflake said that accounts belonging to multiple customers have been hacked after threat actors obtained credentials through info-stealing malware or by purchasing them on online crime forums.