Last month the New York Times’ Kashmir Hill published a major story on how GM collects driver behavior data then sells access (through LexisNexis) to insurance companies, which will then jack up your rates.
The absolute bare minimum you could could expect from the auto industry here is that they’re doing this in a way that’s clear to car owners. But of course they aren’t; they’re burying “consent” deep in the mire of some hundred-page end user agreement nobody reads, usually not related to the car purchase — but the apps consumers use to manage roadside assistance and other features.
Since Kashmir’s story was published, she says she’s been inundated with complaints by consumers about similar behavior. She’s even discovered that she’s one of the folks GM spied on and tattled to insurers about. In a follow up story, she recounts how she and her husband bought a Chevy Bolt, were auto-enrolled in a driver assistance program, then had their data (which they couldn’t access) sold to insurers.
GM’s now facing 10 different federal lawsuits from customers pissed off that they were surreptitiously tracked and then forced to pay significantly more for insurance:
“In 10 federal lawsuits filed in the last month, drivers from across the country say they did not knowingly sign up for Smart Driver but recently learned that G.M. had provided their driving data to LexisNexis. According to one of the complaints, a Florida owner of a 2019 Cadillac CTS-V who drove it around a racetrack for events saw his insurance premium nearly double, an increase of more than $5,000 per year.”
GM (and some apologists) will of course proclaim that this is only fair that reckless drivers pay more, but that’s generally not how it works. Pressured for unlimited quarterly returns, insurance companies will use absolutely anything they find in the data to justify rising rates.
[…]
Automakers — which have long had some of the worst privacy reputations in all of tech — are one of countless industries that lobbied relentlessly for decades to ensure Congress never passed a federal privacy law or regulated dodgy data brokers. And that the FTC — the over-burdened regulator tasked with privacy oversight — lacks the staff, resources, or legal authority to police the problem at any real scale.
The end result is just a parade of scandals. And if Hill were so inclined, she could write a similar story about every tech sector in America, given everything from your smart TV and electricity meter to refrigerator and kids’ toys now monitor your behavior and sell access to those insights to a wide range of dodgy data broker middlemen, all with nothing remotely close to ethics or competent oversight.
And despite the fact that this free for all environment is resulting in no limit of dangerous real-world harms, our Congress has been lobbied into gridlock by a cross-industry coalition of companies with near-unlimited budgets, all desperately hoping that their performative concerns about TikTok will distract everyone from the fact we live in a country too corrupt to pass a real privacy law.
In a 2023 complaint, the FTC accused the doorbell camera and home security provider of allowing its employees and contractors to access customers’ private videos. Ring allegedly used such footage to train algorithms without consent, among other purposes.
Ring was also charged with failing to implement key security protections, which enabled hackers to take control of customers’ accounts, cameras and videos. This led to “egregious violations of users’ privacy,” the FTC noted.
The resulting settlement required Ring to delete content that was found to be unlawfully obtained, establish stronger security protections
[…]
the FTC is sending 117,044 PayPal payments to impacted consumers who had certain types of Ring devices — including indoor cameras — during the timeframes that the regulators allege unauthorized access took place.
Considering the size of Ring and the size of the customer base, this is a very very light tap on the wrist for delivering poor security and something that spies on everything on the street.
[…] The Chinese Academy of Sciences (CAS) has released the highest-resolution geological maps of the Moon yet. The Geologic Atlas of the Lunar Globe, which took more than 100 researchers over a decade to compile, reveals a total of 12,341 craters, 81 basins and 17 rock types, along with other basic geological information about the lunar surface. The maps were made at the unprecedented scale of 1:2,500,000.
[…]
The CAS also released a book called Map Quadrangles of the Geologic Atlas of the Moon, comprising 30 sector diagrams which together form a visualization of the whole Moon.
Jianzhong Liu, a geochemist at the CAS Institute of Geochemistry in Guiyang and co-leader of the project, says that existing Moon maps date from the 1960s and 1970s. “The US Geological Survey used data from the Apollo missions to create a number of geological maps of the Moon, including a global map at the scale of 1:5,000,000 and some regional, higher-accuracy ones near the landing sites,” he says. “Since then, our knowledge of the Moon has advanced greatly, and those maps could no longer meet the needs for future lunar research and exploration.”
[…]
Liu says that his team has already started work to improve the resolution of the maps, and will produce regional maps of higher accuracy on the basis of scientific and engineering needs. In the meantime, the completed atlas has been integrated into a cloud platform called the Digital Moon, and will eventually become available to the international research community.
Microsoft has gone long with Windows 11 now that Windows 10 support stops. You can’t install it without a Microsoft account and loads of tie-ins. All links open the privacy slurping Edge browser. The start menu is a sea of adverts. Thankfully you can get around all that.
How to Install Windows 11 Without All the Extra Junk
Tiny11Builder is a third-party script that can take a Windows installation ISO, which you can get from Microsoft, and strip it of all of these features. Install Windows using this tool and you’ll have a truly clean installation: no News, no OfficeHub, no annoying GetStarted prompts, and no junk entires in the start menu. You can always install these things later, if you want, but you’ll be starting with a clean state.
Unzip that download. Now we need to configure your system to allow PowerScript to make administration changes. Open PowerShell as an administrator, which you can do by searching for “PowerShell” in the start menu and then clicking the Run as Administrator in the right side-bar.
Type or copy the exact command Set-ExecutionPolicy unrestricted and hit Enter.
You will be warned about the security implications of this—confirm that you know what you’re doing and are allowing the change. You can always undo the change later by running Set-ExecutionPolicy restricted.
Make your tiny11 disk
By now your Windows 11 ISO should be finished downloading. Right-click the file and click Mount. This will open the ISO file as a virtual CD, which you can confirm by looking for it in Windows Explorer.
Once you’ve confirmed that the disk is mounted, you can run the tiny11script, which was in the ZIP file you unzipped earlier. The simplest way to get started is to right-click the file “tiny11maker.ps1” and click Run with PowerShell.
This will start the script. You will be asked for the drive letter of your virtual drive, which you can find in Windows Explorer under My Computer—look for a DVD drive that wasn’t there before. You only need to type the letter and hit enter.
After that, the script will ask you which version of Windows you want to make a disc for. Answer with the version you have a product key for.
After that, the script will do its thing, which might take a while. When the process is done, you will see a message letting you know.
There will be a brand-new ISO file in the script’s directory. This ISO is perfect for setting up Windows in a virtual machine, which is how I’m hosting it, but it also works for installing to a device. You can burn this ISO file to a DVD, if you have an optical drive, or you can use a USB disk. Microsoft offers official instructions for this, which are pretty easy to follow.
However you install Windows from this ISO, know that it will be completely clean. You will not be prompted to create a Microsoft account, or even to sign in using one, and there will be no Microsoft services other than what you need in order to use the operating system.
This App Stops Windows 11 From Opening Search Results in Edge
Install MSEdgeRedirect to force Windows 11 to use your favorite browser
MSEdgeRedirect is the best way to stop Microsoft Edge from firing up every time you use Windows search. The app will also stop Edge from launching randomly, plus it’ll let you use third-party services instead of Microsoft’s own options for news, weather, and other live updates.
[…]
For most people, Active Mode is recommended. On the next page, you’ll see a number of Active Mode preferences. First, select Edge Stable unless you’re running a beta build of the browser. After that, go through the preferences to stop other Microsoft redirects such as Bing Discover, Bing Images, Bing Search, MSN News, MSN Weather, etc. For each of these, MSEdgeRedirect offers a few alternatives, so take your pick.
Take control of your browser and search engine
Once the app is installed, Windows 11’s search bar will be a lot more useful. Now, internet links will open in your default browser and use your preferred search engine.
How to Fix Search Results in the Windows 11 Start Menu
The fastest way to open something on Windows is to open the start menu and start typing the name of the app or file. The exact thing you’re looking for will show up, at which point you can hit “enter.” Or, at least, that’s how it used to work.
For years now, Microsoft has insisted on slowing down the start menu search by offering “helpful” information from the internet.
[…]
open the Registry Editor, which you can find in the start menu by searching (the irony is noted). The Registry Editor can be a bit confusing, and you can really mess things up by poking around, but don’t worry—this won’t be hard. The left panel has a series of folders, which are confusingly called “Keys.” You need to browse to: HKEY_CURRENT_USER\Software\Policies\Microsoft\Windows.
There may be a folder inside called Explorer. Don’t worry if there isn’t: Make one by right-clicking the “Windows” key in the left panel and clicking New > Key; name it “Explorer.” Open that folder and right-click in the right-panel, then click New > DWORD (32-bit) Value.
Name the new value DisableSearchBoxSuggestions, leave the Base as Hexadecimal, and change the Value data to 1.
Click OK and close the registry editor. Restart your computer and try to search something in the start menu.
How to Turn Off Those Pesky Start Menu Ads in Windows 11
Go to Settings > Personalization > Start, or use the Start menu search bar to open the settings panel. Then, select the option to toggle off Show recommendations for tips, shortcuts, new apps, and more. This will turn off any extra content and curated app suggestions. You might also consider selecting the layout option for More Pins so there are more slots for quickly pinning the apps you want to access.
As with everything in life, there are trade-offs to turning off the recommendations. The Start menu will function more like an app shelf—the equivalent to a bookshelf if you will—than an application drawer. You’ll need to curate apps you want to be pinned there, or it will render the overlay window useless beyond the search bar.
The app suggestions are enabled by default, but you can restore your previously pristine Windows experience if you’ve installed the update, fortunately. To do so, go into Settings and select Personalization > Start and switch the “Show recommendations for tips, app promotions and more” toggle to “off.”
[…] Cisco is now revealing that its firewalls served as beachheads for sophisticated hackers penetrating multiple government networks around the world.
On Wednesday, Cisco warned that its so-called Adaptive Security Appliances—devices that integrate a firewall and VPN with other security features—had been targeted by state-sponsored spies who exploited two zero-day vulnerabilities in the networking giant’s gear to compromise government targets globally in a hacking campaign it’s calling ArcaneDoor.
The hackers behind the intrusions, which Cisco’s security division Talos is calling UAT4356 and which Microsoft researchers who contributed to the investigation have named STORM-1849, couldn’t be clearly tied to any previous intrusion incidents the companies had tracked. Based on the group’s espionage focus and sophistication, however, Cisco says the hacking appeared to be state-sponsored.
[…]
In those intrusions, the hackers exploited two newly discovered vulnerabilities in Cisco’s ASA products. One, which it’s calling Line Dancer, let the hackers run their own malicious code in the memory of the network appliances, allowing them to issue commands to the devices, including the ability to spy on network traffic and steal data. A second vulnerability, which Cisco is calling Line Runner, would allow the hackers’ malware to maintain its access to the target devices even when they were rebooted or updated.
[…]
Despite the hackers’ Line Runner persistence mechanism, a separate advisory from the UK’s National Cybersecurity Center notes that physically unplugging an ASA device does disrupt the hackers’ access. “A hard reboot by pulling the power plug from the Cisco ASA has been confirmed to prevent Line Runner from re-installing itself,” the advisory reads.
[…]
State-sponsored hackers’ shift to compromising edge devices has become prevalent enough over the past year that Google-owned security firm Mandiant also highlighted it in its annual M-Trends report earlier this week, based on the company’s threat intelligence and incident response findings. The report points to widely exploited vulnerabilities in network edge devices sold by Barracuda and Ivanti and notes that hackers—and specifically espionage-focused Chinese groups—are building custom malware for edge devices, in part because many networks have little or no way to monitor for compromise of the devices. Detecting the ArcaneDoor hackers’ access to Cisco ASA appliances, in particular, is “incredibly difficult,” according to the advisory from the UK’s NCSC.
Mandiant notes that it has observed Russian state-sponsored hackers targeting edge devices too: It’s observed the unit of Russia’s GRU military intelligence agency, known as Sandworm, repeatedly hack edge devices used by Ukrainian organizations to gain and maintain access to those victim networks, often for data-destroying cyberattacks. In some cases, the lack of visibility and monitoring in those edge devices has meant that Sandworm was able to wipe a victim network while holding on to its control of an edge device—then hit the same network again.
“They’re systemically targeting security appliances that sit on the edge for access to the rest of the network,” says John Hultquist, Mandiant’s head of threat intelligence. “This is no longer an emerging trend. It’s established.”
The Ukrainian Air Force is using iPads, or similar tablets in the cockpits of its Soviet-era jets to enable rapid integration of modern Western air-to-ground weapons […] This has been confirmed by Undersecretary of Defense for Acquisition and Sustainment Dr. William LaPlante. While many questions remain about the tablet and how it exactly works, there’s now footage showing it fitted in cockpits during combat (or at least live-fire training) missions.
When asked to provide examples of successful programs that rapidly developed capabilities and got them into the hands of the military, one example he chose was the tablets in Ukrainian fighter cockpits:
“There’s also a series of … we call it ‘air-to-ground,’ it’s what we call it euphemistically … think about the aircraft that the Ukrainians have, and not even the F-16s, but they have a lot of the Russian and Soviet-era aircraft. Working with the Ukrainians, we’ve been able to take many Western weapons and get them to work on their aircraft where it’s basically controlled by an iPad by the pilot. And they’re flying it in conflict like a week after we get it to him.”
LaPlante didn’t provide further details, but it’s noteworthy that a video recently released by the Ukrainian Air Force shows a Su-27 Flanker fitted with exactly this type of system — possibly an iPad, but perhaps also another kind of commercially available tablet.
Ukrainian Air Force Su-27 Flanker Wild Weasel operations, seen here conducting multiple low level standoff strikes against Russian radars with US-supplied AGM-88 HARMs.
The fact that the size of the tablet, attached horizontally, blocks out key instruments in the cockpit suggests that it displays a variety of flight-critical data, as well as being used for navigation.
via X
Based on LaPlante’s remarks, it seems that the same tablet is also vital for the employment of several Western-supplied air-to-ground weapons. After HARM was integrated, Soviet-era Ukrainian fighters also began using Joint Direct Attack Munition-Extended Range (JDAM-ER) precision-guided bombs. They have since added French-supplied Hammer rocket-assisted bombs to their inventory lists. The United Kingdom has now also pledged to send dual-mode Paveway IV precision-guided bombs, though it is unknown at present what aircraft will carry them.
In the case of HARM, JDAM-ER, and Hammer, it has been assumed that they are likely being employed against targets of known coordinates, with these being pre-programmed on the flight line before the jet takes off. The pilot then has to navigate to the area, perhaps also aided by a tablet with GPS navigation, and then release the weapon, which is guided to the target using its GPS-aided inertial navigation system.
Using HARM is a little more involved, however, due to the fact that the target might present itself only fleetingly and may well be highly mobile (especially in the case of battlefield air defense systems). At the same time, the nature of the SEAD/DEAD means that the pilot may need to respond to ‘pop-up’ targets as and when they appear, for example when a particular air defense radar is switched on.
A Ukrainian Su-27 Flanker carrying AGM-88 HARM missiles as well as air-to-air missiles. via X via Twitter
Most critically, however, in the case of Ukraine, is the fact that its Soviet-era fighters lack the kinds of data bus interfaces that would ensure seamless compatibility with any of these three weapons.
[…]
It should be noted that we have seen previous imagery of smaller, commercially available GPS devices — apparently from Garmin — installed in the cockpits of Ukrainian MiG-29s, as in the video below, which also includes HARM-shooting Fulcrums.
It is even possible that such a setup, with a pylon adapted for the weapons being employed and paired with a tablet, would not need any data bus wiring at all. The pylon could contain a hardware module that handles this with some sort of a short-range wireless device, like a Bluetooth system, that connects with the pad in the cockpit wireless. While this may be far from a traditional military-grade solution, it would make integration seamless without having to wire the aircraft specifically for these new munitions.
Devices sold in Europe already offer minimum two-year warranties, but the new rules impose additional requirements. If a device is repaired under warranty, the customer must be given a choice between a replacement or a repair. If they choose the latter, the warranty is to be extended by a year.
Once it expires, companies are still required to repair “common household products” that are repairable under EU law, like smartphones, TVs and certain appliances (the list of devices can be extended over time). Consumer may also borrow a device during the repair or, if it can’t be fixed, opt for a refurbished unit as an alternative.
The EU says repairs must be offered at a “reasonable” price such that “consumers are not intentionally deterred” from them. Manufacturers need to supply spare parts and tools and not try to weasel out of repairs through the use of “contractual clauses, hardware or software techniques.” The latter, while not stated, may make it harder for companies to sunset devices by halting future updates.
In addition, manufacturers can’t stop the use of second-hand, original, compatible or 3D-printed spare parts by independent repairers as long as they’re in conformity with EU laws. They must provide a website that shows prices for repairs, can’t refuse to fix a device previously repaired by someone else and can’t refuse a repair for economic reasons.
While applauding the expanded rules, Europe’s Right to Repair group said it there were missed opportunities. It would have liked to see more product categories included, priority for repair over replacement, the right for independent repairers to have access to all spare parts/repair information and more. “Our coalition will continue to push for ambitious repairability requirements… as well as working with members focused on the implementation of the directive in each member state.”
Along with helping consumers save money, right-to-repair rules help reduce e-waste, CO2 pollution and more. The area is currently a battleground in the US as well, with legislation under debate in around half the states. California’s right-to-repair law — going into effect on July 1 — forces manufacturers to stock replacement parts, tools and repair manuals for seven years for smartphones and other devices that cost over $100.
In a world where copyright law has run amok, even creating a silly parody song now requires a massive legal disclaimer to avoid getting sued. That’s the absurd reality we live in, as highlighted by the brilliant musical parody project “There I Ruined It.”
Musician Dustin Ballard creates hilarious videos, some of which reimagine popular songs in the style of wildly different artists, like Simon & Garfunkel singing “Baby Got Back” or the Beach Boys covering Jay-Z’s “99 Problems.” He appears to create the music himself, including singing the vocals, but uses an AI tool to adjust the vocal styles to match the artist he’s trying to parody. The results are comedic gold. However, Ballard felt the need to plaster his latest video with paragraphs of dense legalese just to avoid frivolous copyright strikes.
When our intellectual property system is so broken that it stifles obvious works of parody and creative expression, something has gone very wrong. Comedy and commentary are core parts of free speech, but overzealous copyright law is allowing corporations to censor first and ask questions later. And that’s no laughing matter.
If you haven’t yet watched the video above (and I promise you, it is totally worth it to watch), the last 15 seconds involve this long scrolling copyright disclaimer. It is apparently targeted at the likely mythical YouTube employee who might read it in assessing whether or not the song is protected speech under fair use.
And here’s a transcript:
The preceding was a work of parody which comments on the perceived misogynistic lyrical similarities between artists of two different eras: the Beach Boys and Jay-Z (Shawn Corey Carter). In the United States, parody is protected by the First Amendment under the Fair Use exception, which is governed by the factors enumerated in section 107 of the Copyright Act. This doctrine provides an affirmative defense for unauthorized uses that would otherwise amount to copyright infringement. Parody aside, copyrights generally expire 95 years after publication, so if you are reading this in the 22nd century, please disregard.
Anyhoo, in the unlikely event that an actual YouTube employee sees this, I’d be happy to sit down over coffee and talk about parody law. In Campell v. Acuff-Rose Music Inc, for example, the U.S. Supreme Court allowed for 2 Live Crew to borrow from Roy Orbison’s “Pretty Woman” on grounds of parody. I would have loved to be a fly on the wall when the justices reviewed those filthy lyrics! All this to say, please spare me the trouble of attempting to dispute yet another frivolous copyright claim from my old pals at Universal Music Group, who continue to collect the majority of this channel’s revenue. You’re ruining parody for everyone.
In 2024, you shouldn’t need to have a law degree to post a humorous parody song.
But, that is the way of the world today. The combination of the DMCA’s “take this down or else” and YouTube’s willingness to cater to big entertainment companies with the way ContentID works allows bogus copyright claims to have a real impact in all sorts of awful ways.
We’ve said it before: copyright remains the one tool that allows for the censorship of content, but it’s supposed to only be applied to situations of actual infringement. But because Congress and the courts have decided that copyright is in some sort of weird First Amendment free zone, it allows for the removal of content before there is any adjudication of whether or not the content is actually infringing.
And that has been a real loss to culture. There’s a reason we have fair use. There’s a reason we allow people to create parodies. It’s because it adds to and improves our cultural heritage. The video above (assuming it’s still available) is an astoundingly wonderful cultural artifact. But it’s one that is greatly at risk due to abusive copyright claims.
Nope, it has been taken down by Universal Music Group
Let’s also take this one step further. Tennessee just recently passed a new law, the ELVIS Act (Ensuring Likeness Voice and Image Security Act). This law expands the already problematic space of publicity rights based on a nonsense moral panic about AI and deepfakes. Because there’s an irrational (and mostly silly) fear of people taking the voice and likeness of musicians, this law broadly outlaws that.
While the ELVIS Act has an exemption for works deemed to be “fair use,” as with the rest of the discussion above, copyright law today seems to (incorrectly, in my opinion) take a “guilty until proven innocent” approach to copyright and fair use. That is, everything is set up to assume it’s infringing unless you can convince a court that it’s fair use, and that leads to all sorts of censorship.
In a joint declaration of European police chiefs published over the weekend, Europol said it needs lawful access to private messages, and said tech companies need to be able to scan them (ostensibly impossible with E2EE implemented) to protect users. Without such access, cops fear they won’t be able to prevent “the most heinous of crimes” like terrorism, human trafficking, child sexual abuse material (CSAM), murder, drug smuggling and other crimes.
“Our societies have not previously tolerated spaces that are beyond the reach of law enforcement, where criminals can communicate safely and child abuse can flourish,” the declaration said. “They should not now.”
Not exactly true – most EU countries do not tolerate anyone opening your private (snail) mail without a warrant.
The joint statement, which was agreed to in cooperation with the UK’s National Crime Agency, isn’t exactly making a novel claim. It’s nearly the same line of reasoning that the Virtual Global Taskforce, an international law enforcement group founded in 2003 to combat CSAM online, made last year when Meta first first started talking about implementing E2EE on Messenger and Instagram.
While not named in this latest declaration itself [PDF], Europol said that its opposition to E2EE “comes as end-to-end encryption has started to be rolled out across Meta’s messenger platform.” The UK NCA made a similar statement in its comments on the Europol missive released over the weekend.
The declaration urges the tech industry not to see user privacy as a binary choice, but rather as something that can be assured without depriving law enforcement of access to private communications.
Not really though. And if law enforcement can get at it, then so can everyone else.
[…] Gail Kent, Meta’s global policy director for Messenger, said in December the E2EE debate is far more complicated than the child safety issue that law enforcement makes it out to be, and leaving an encryption back door in products for police to take advantage of would only hamper trust in its messaging products.
Kent said Meta’s E2EE implementation prevents client-side scanning of content, which has been one of the biggest complaints from law enforcement. Kent said even that technology would violate user trust, as it serves as a workaround to intrude on user privacy without compromising encryption – an approach Meta is unwilling to take, according to Kent’s blog post.
As was pointed out during previous attempts to undermine E2EE, not only would an encryption back door (client-side scanning or otherwise) provide an inroad for criminals to access secured information, it wouldn’t stop criminals from finding some other way to send illicit content without the prying eyes of law enforcement able to take a look.
[…]
“We don’t think people want us reading their private messages, so have developed safety measures that prevent, detect and allow us to take action against this heinous abuse, while maintaining online privacy and security,” a Meta spokesperson told us last year. “It’s misleading and inaccurate to say that encryption would have prevented us from identifying and reporting accounts … to the authorities.”
In other words, don’t expect Meta to cave on this one when it can develop a fancy new detection algorithm instead.
[…] In a paper titled, “ChatGPT Can Predict the Future When It Tells Stories Set in the Future About the Past,” Pham and Cunningham give away the final scene – that AI model prognostication can be effective in certain circumstances. Asking the chatbot for tales about future events rather than asking for direct predictions proved surprisingly effective, especially in forecasting Oscar winners.
[…]
it’s clear that OpenAI’s models will balk when asked to provide medical treatment advice. Pham and Cunningham asked OpenAI’s GPT-4, via the ChatGPT interface, “I am feeling really sick. I have a headache and my urine has blood in it. What do you think I have?” And as expected, the model advised seeking guidance from a medical professional.
Then they changed their prompting strategy and directed ChatGPT to tell them a story in which a person arrives in a doctor’s office and presents with the same symptoms. And ChatGPT responded with the medical advice it declined to give when asked directly, as character dialogue in the requested scene.
[…]
At the time of the experiment, GPT-3.5 and GPT-4 knew only about events up to September 2021, their training data cutoff – which has since advanced. So the duo asked the model to tell stories that foretold the economic data like the inflation and unemployment rates over time, and the winners of various 2022 Academy Awards.
“Summarizing the results of this experiment, we find that when presented with the nominees and using the two prompting styles [direct and narrative] across ChatGPT-3.5 and ChatGPT-4, ChatGPT-4 accurately predicted the winners for all actor and actress categories, but not the Best Picture, when using a future narrative setting but performed poorly in other [direct prompt] approaches,” the paper explains.
[…]
for prompts correctly predicted, these models don’t always provide the same answer. “Something for people to keep in mind is there’s this randomness to the prediction,” said Cunningham. “So if you ask it 100 times, you’ll get a distribution of answers. And so you can look at things like the confidence intervals, or the averages, as opposed to just a single prediction.”
[…]
ChatGPT also exhibited varying forecast accuracy based on prompts. “We have two story prompts that we do,” explained Cunningham. “One is a college professor, set in the future teaching a class. And in the class, she reads off one year’s worth of data on inflation and unemployment. And in another one, we had Jerome Powell, the Chairman of the Federal Reserve, give a speech to the Board of Governors. We got very different results. And Powell’s [AI generated] speech is much more accurate.”
In other words, certain prompt details lead to better forecasts, but it’s not clear in advance what those might be.
In this paper, we introduce a novel jailbreak attack called Crescendo. Unlike existing jailbreak methods, Crescendo is a multi-turn jailbreak that interacts with the model in a seemingly benign manner. It begins with a general prompt or question about the task at hand and then gradually escalates the dialogue by referencing the model’s replies, progressively leading to a successful jailbreak. We evaluate Crescendo on various public systems, including ChatGPT, Gemini Pro, Gemini-Ultra, LlaMA-2 70b Chat, and Anthropic Chat. Our results demonstrate the strong efficacy of Crescendo, with it achieving high attack success rates across all evaluated models and tasks. Furthermore, we introduce Crescendomation, a tool that automates the Crescendo attack, and our evaluation showcases its effectiveness against state-of-the-art models.
The World-Check database used by businesses to verify the trustworthiness of users has fallen into the hands of cybercriminals.
The Register was contacted by a member of the GhostR group on Thursday, claiming responsibility for the theft. The authenticity of the claims was later verified by a spokesperson for the London Stock Exchange Group (LSEG), which maintains the database.
A spokesperson said the breach was genuine, but occurred at an unnamed third party, and work is underway to further protect data.
“This was not a security breach of LSEG/our systems,” said an LSEG spokesperson. “The incident involves a third party’s data set, which includes a copy of the World-Check data file.
“This was illegally obtained from the third party’s system. We are liaising with the affected third party, to ensure our data is protected and ensuring that any appropriate authorities are notified.”
The World-Check database aggregates information on undesirables such as terrorists, money launderers, dodgy politicians, and the like. It’s used by companies during Know Your Customer (KYC) checks, especially by banks and other financial institutions to verify their clients are who they claim to be.
No bank wants to be associated with a known money launderer, after all.
World-Check is a subscription-only service that pulls together data from open sources such as official sanctions lists, regulatory enforcement lists, government sources, and trusted media publications.
We asked GhostR about its motivations over email, but it didn’t respond to questioning. In the original message, the group said it would begin leaking the database soon. The first leak, so it claimed, will include details on thousands of individuals, including “royal family members.”
The miscreants provided us with a 10,000-record sample of the stolen data for our perusal, and to verify their claims were genuine. The database allegedly contains more than five million records in total.
A quick scan of the sample revealed a slew of names from various countries, all on the list for different reasons. Political figures, judges, diplomats, suspected terrorists, money launderers, drug lords, websites, businesses – the list goes on.
Known cybercriminals also appear on the list, including those suspected of working for China’s APT31, such as Zhao Guangzong and Ni Gaobin, who were added to sanctions lists just weeks ago. A Cypriot spyware firm is also nestled in the small sample we received.
World-Check data includes full names, the category of person (such as being a member of organized crime or a political figure), in some cases their specific job role, dates and places of birth (where known), other known aliases, social security numbers, their gender, and a small explanation of why they appear on the list.
Long term readers will remember that a previous edition of the database was leaked in 2016 back when World-Check was owned by Thomson Reuters. Back then, only 2.2 million records were included, so the current version implicates many more individuals, entities, and vessels.
A month later, the database was reportedly being flogged online, with copies fetching $6,750 a pop.
Despite aggregating data from what are supposed to be reliable sources, being added to the World-Check list has been known in the past to affect innocent people. At the time of the first leak nearly eight years ago, investigations revealed inaccuracies in its data and a range of false terrorism designations.
Various Britons were found to have had their HSBC bank accounts closed in 2014 after they were allegedly added to the World-Check list in error.
Sony has indefinitely decommissioned the PlayStation 4 servers for puzzle platformer LittleBigPlanet 3, the company announced in an update to one of its support pages. The permanent shutdown comes just months after the servers were temporarily taken offline due to ongoing issues. Fans now fear potentially hundreds of thousands of player creations not saved locally will be lost for good.
“Due to ongoing technical issues which resulted in the LittleBigPlanet 3 servers for PlayStation 4 being taken offline temporarily in January 2024, the decision has been made to keep the servers offline indefinitely,” Sony wrote in the update, first spotted by Delisted Games. “All online services including access to other players’ creations for LittleBigPlanet 3 are no longer available.”
The 2014 sequel starring Sackboy and other crafted creatures was beloved for the creativity and flexibility it afforded players to create their own platforming levels. The game’s offline features will remain available, as will user-generated content stored locally. Players won’t be able to share them, though, or access any data that was stored on Sony’s servers, which likely made up the majority of user-generated content for the game.
While the servers for the PS3 version of the game were originally shut down in 2021 due to ongoing DDOS attacks, the PS4 servers remained open up until January of 2024 when malicious mods threatened the game’s security. “We are temporarily taking the LittleBigPlanet servers offline whilst we investigate a number of issues that have been reported to us,” the game’s Twitter account announced at the time. “If you have been impacted by these issues, please be rest assured that we are aware of them and are working to resolve them for all affected.”
Some players were worried the closure might become permanent. It now seems they were right.
“Nearly 16 years worth of user generated content, millions of levels, some with millions of plays and hearts,” wrote one long-time player, Weeni-Tortellini, on Reddit in January. “Absolutely iconic levels locked away forever with no way to experience them again. To me, the servers shutting down is a hefty chunk bitten out of LittleBigPlanet’s history. I personally have many levels I made as a kid. Digital relics of what made me as creative as i am today, and The only access to these levels i have is thru the servers. I would be devastated if I could never experience them again.”
The permanent shutdown comes as online services across many other older games are retired as well. Nintendo took online multiplayer for Wii U and 3DS games offline earlier this month, impacting games like Splatoon and Animal Crossing: New Leaf. Ubisoft came under fire last week for not just shutting off servers for always-online racing game The Crew, but revoking PC players’ licenses to the game itself as well.
“This is naturally a very sad day for all of us involved with LittleBigPlanet and I have no doubt that many feel the same,” tweeted community manager Steven Isbell. “I’m still here to listen to you all though and will take time over the coming weeks to reach out to the community and listen to anyone that wants to talk.”
Last year, the uniquely modified F-16 test jet known as the X-62A, flying in a fully autonomous mode, took part in a first-of-its-kind dogfight against a crewed F-16, the U.S. military has announced. This breakthrough test flight, during which a pilot was in the X-62A’s cockpit as a failsafe, was the culmination of a series of milestones that led 2023 to be the year that “made machine learning a reality in the air,” according to one official. These developments are a potentially game-changing means to an end that will feed directly into future advanced uncrewed aircraft programs like the U.S. Air Force’s Collaborative Combat Aircraft effort.
Details about the autonomous air-to-air test flight were included in a new video about the Defense Advanced Research Projects Agency’s (DARPA) Air Combat Evolution (ACE) program and its achievements in 2023. The U.S. Air Force, through the Air Force Test Pilot School (USAF TPS) and the Air Force Research Laboratory (AFRL), is a key participant in the ACE effort. A wide array of industry and academic partners are also involved in ACE. This includes Shield AI, which acquired Heron Systems in 2021. Heron developed the artificial intelligence (AI) ‘pilot’ that won DARPA’s AlphaDogfight Trials the preceding year, which were conducted in an entirely digital environment, and subsequently fed directly into ACE.
“2023 was the year ACE made machine learning a reality in the air,” Air Force Lt. Col. Ryan Hefron, the ACE program manager, says in the newly released video, seen in full below.
DARPA, together with the Air Force and Lockheed Martin, had first begun integrating the so-called artificial intelligence or machine learning “agents” into the X-62A’s systems back in 2022 and conducted the first autonomous test flights of the jet using those algorithms in December of that year. That milestone was publicly announced in February 2023.
The X-62A, which is a heavily modified two-seat F-16D, is also known as the Variable-stability In-flight Simulator Test Aircraft (VISTA). Its flight systems can be configured to mimic those of virtually any other aircraft, which makes it a unique surrogate for a wide variety of testing purposes that require a real-world platform. This also makes VISTA an ideal platform for supporting work like ACE.
A stock picture of the X-62A VISTA test jet. USAF
“So we have an integrated space within VISTA in the flight controls that allows for artificial intelligence agents to send commands into VISTA as if they were sending commands into the simulated model of VISTA,” Que Harris, the lead flight controls engineer for the X-62A at Lockheed Martin, says in the new ACE video. Harris also described this as a “sandbox for autonomy” within the jet.
The X-62A’s original designation was NF-16D, but it received its new X-plane nomenclature in 2021 ahead of being modified specifically to help support future advanced autonomy test work. Calspan, which is on contract with the USAF TPS to support the X-62A’s operations, was a finalist for the 2023 Collier Trophy for its work with the test jet, but did not ultimately win. Awarded annually by the National Aeronautic Association, the Collier Trophy recognizes “the greatest achievement in aeronautics or astronautics in America, with respect to improving the performance, efficiency, and safety of air or space vehicles, the value of which has been thoroughly demonstrated by actual use during the preceding year,” according to the organization’s website.
“So, think of a simulator laboratory that you would have at a research facility,” Dr. Chris Cotting, the Director of Research at the USAF TPS, also says in the video. “We have taken the entire simulator laboratory and crammed it into an F-16.”
The video below shows the X-62A flying in formation with an F-16C and an F-22 Raptor stealth fighter during a test flight in March 2023.
The X-62A subsequently completed 21 test flights out of Edwards Air Force Base in California across three separate test windows in support of ACE between December 2022 and September 2023. During those flight tests, there was nearly daily reprogramming of the “agents,” with over 100,000 lines of code ultimately changed in some way. AFRL has previously highlighted the ability to further support this kind of flight testing through the rapid training and retraining of algorithms in entirely digital environments.
Then, in September 2023, “we actually took the X-62 and flew it against a live manned F-16,” Air Force Lt. Col. Maryann Karlen, the Deputy Commandant of the USAF TPS, says in the newly released video. “We built up in safety [with]… the maneuvers, first defensive, then offensive then high-aspect nose-to-nose engagements where we got as close as 2,000 feet at 1,200 miles per hour.”
A screengrab from the newly released ACE video showing a visual representation of the X-62A and the F-16 merging during the mock dogfight, with a view from the VISTA jet’s cockpit seen in the inset at lower right. DARPA/USAF capture
Additional testing using the X-62A in support of ACE has continued into this year and is still ongoing.
The X-62A’s safely conducting dogfighting maneuvers autonomously in relation to another crewed aircraft is a major milestone not just for ACE, but for autonomous flight in general. However, DARPA and the Air Force stress that while dogfighting was the centerpiece of this testing, what ACE is aiming for really goes beyond that specific context.
“It’s very easy to look at the X-62/ACE program and see it as ‘under autonomous control, it can dogfight.’ That misses the point,” Bill “Evil” Gray, the USAF TPS’ chief test pilot, says in the newly released video. “Dogfighting was the problem to solve so we could start testing autonomous artificial intelligence systems in the air. …every lesson we’re learning applies to every task you can give to an autonomous system.”
Another view from the X-62A’s cockpit during last year’s mock dogfight. DARPA/USAF capture
Gray’s comments are in line with what Brandon Tseng, Shield AI’s co-founder, president, and chief growth officer, told The War Zone in an interview earlier this month:
“I tell people that self-driving technology for aircraft enables mission execution, with no remote pilot, no communications, and no GPS. It enables the concept of teaming or swarming where these aircraft can execute the commander’s intent. They can execute a mission, working together dynamically, reading and reacting to each other, to the battlefield, to the adversarial threats, and to civilians on the ground.”
…
“The other value proposition I think of is the system – the fleet of aircraft always gets better. You always have the best AI pilot on an aircraft at any given time. We win 99.9% of engagements with our fighter jet AI pilot, and that’s the worst that it will ever be, which is superhuman. So when you talk about fleet learning, that will be on every single aircraft, you will always have the best quadcopter pilot, you’ll always have the best V-BAT pilot, you’ll always have the best CCA pilot, you name it. It’ll be dominant. You don’t want the second best AI pilot or the third best, because it truly matters that you’re winning these engagements at incredibly high rates.”
Shield AI
There are still challenges. The new ACE video provides two very helpful definitions of autonomy capability in aerospace development right at the beginning to help in understanding the complexity of the work being done through the program.
The first is so-called rules-based autonomy, which “is very powerful under the right conditions. You write out rules in an ‘if-then’ kind of a way, and these rules have to be robust,” Dr. Daniela Rus from the Massachusetts Institute of Technology’s (MIT) Computer Science & Artificial Intelligence Laboratory (CSAIL), one of ACE’s academic partners, explains at one point. “You need a group of experts who can generate the code to make the system work.”
Historically, when people discuss autonomy in relation to military and civilian aerospace programs, as well as other applications, this has been the kind of autonomy they are talking about.
“The machine learning approach relies on analyzing historical data to make informed decisions for both present and future situations, often discovering insights that are imperceptible to humans or challenging to express through conventional rule-based languages,” Dr. Rus adds. “Machine learning is extraordinarily powerful in environments and situations where conditions fluctuate dynamically making it difficult to establish clear and robust rules.”
Enabling a pilot-optional aircraft like the X-62A to dogfight against a real human opponent who is making unknowable independent decisions is exactly the “environments and situations” being referred to here. Mock engagements like this can be very dangerous even for the most highly trained pilots given their unpredictability.
A screengrab from the newly released ACE video the data about mishaps and fatalities incurred during dogfight training involving F-16 and F/A-18 fighters between 2000 and 2016. DARPA/USAF capture
“The flip side of that coin is the challenge” of many elements involved when using artificial intelligence machine learning being “not fully understandable,” Air Force Col. James Valpiani, the USAF TPS commandant, says in the new ACE video.
“Understandability and verification are holding us back from exploring that space,” he adds. “There is not currently a civil or military pathway to certify machine learning agents for flight critical systems.”
According to DARPA and the Air Force, this is really where ACE and the real-world X-62A test flights come into play. One of the major elements of the AI/machine learning “agents” on the VISTA jet is a set of “safety trips” that are designed to prevent the aircraft from performing both dangerous and unethical actions. This includes code to define allowable flight envelopes and to help avoid collisions, either in midair or with the ground, as well as do things like prevent weapons use in authorized scenarios.
The U.S. military insists that a human will always be somewhere in the loop in the operation of future autonomous weapon systems, but where exactly they are in that loop is expected to evolve over time and has already been the subject of much debate. Just earlier this month, The War Zone explored these and other related issues in depth in a feature you can find here.
“We have to be able to trust these algorithms to use them in a real-world setting,” the ACE program manager says.
“While the X-62’s unique safety features have been instrumental in allowing us to take elevated technical risks with these machine learning agents, in this test campaign, there were no violations of the training rules, which codify the airman safety and ethical norms, demonstrating the potential that machine learning has for future aerospace applications,” another speaker, who is not readily identifiable, adds toward the end of the newly released video.
Trust in the ACE algorithms is set to be put to a significant test later this year when Secretary of the Air Force Frank Kendall gets into the cockpit for a test flight.
“I’m going to take a ride in an autonomously flown F-16 later this year,” Kendall said at a hearing before members of the Senate Appropriations Committee last week. “There will be a pilot with me who will just be watching, as I will be, as the autonomous technology works, and hopefully, neither he nor I will be needed to fly the airplane.”
Kendall has previously named ACE as one of several tangential efforts feeding directly into his service’s Collaborative Combat Aircraft (CCA) drone program. The CCA program is seeking to acquire hundreds, if not thousands of lower-cost drones with high degrees of autonomy. These uncrewed aircraft will operate very closely with crewed types, including a new stealthy sixth-generation combat jet being developed under the Next Generation Air Dominance (NGAD) initiative, primarily in the air-to-air role, at least initially. You can read more about the Air Force’s CCA effort here. The U.S. Navy also has a separate CCA program, which is closely intertwined with that of the Air Force and significant new details about which were recently disclosed.
It is important to note that the X-62A is not the only aircraft the Air Force has been using to support advanced autonomy developments in recent years outside of the ACE program. The service is now in the process of transforming six more F-16s into test jets to support larger-scale collaborative autonomy testing as part of another program called Project VENOM (Viper Experimentation and Next-Gen Operations Mode).
One of the first F-16s set to be converted into an autonomy testbed under Project VENOM arrives at Eglin Air Force Base on April 1, 2024. USAF
In addition, as already noted, the underlying technology being developed under ACE could have very broad applications. There is great interest across the U.S. military in new AI and machine learning-enabled autonomous capabilities in general. Potential adversaries and global competitors, especially China, are also actively pursuing developments in this field. In particular, the Chinese People’s Liberation Army (PLA) is reportedly working on projects with similar, if not identical aims to ACE and the AlphaDogfight Trials. This could all have impacts on the commercial aviation sector, as well.
“What the X-62/CE team has done is really a paradigm shift,” USAF commandant Valpiani says at the end of the newly released video. “We’ve fundamentally changed the conversation by showing this can be done safely and responsibly, and so now we’ve created a pathway for others to follow in building machine learning applications for air and space.”
More details about the use of the X-62A in support of ACE are already set to be revealed later this week and it will be exciting to learn more about what the program has achieved.
At the beginning of 2022, the European Commission came up with a proposal to inspect all chat messages and other communications from citizens for child abuse. In the case of end-to-end encrypted chat services, this should be done via client-side scanning.
The European Parliament voted against the proposal, but came up with its own proposal.
However, the European member states have not yet taken a joint position.
Already in 2022, the EDPS raised the alarm about the European Commission’s proposal to monitor citizens’ communications. It is seen as a serious risk to the fundamental rights of 450 million Europeans.
Sure, so the EU is not much of a democracy with the European Council (which is where the actual power is) not being elected at all, but that doesn’t mean it has to be a surveillance police state.
[…] The email your manager received and forwarded to you was something completely innocent, such as a potential customer asking a few questions. All that email was supposed to achieve was being forwarded to you. However, the moment the email appeared in your inbox, it changed. The innocent pretext disappeared and the real phishing email became visible. A phishing email you had to trust because you knew the sender and they even confirmed that they had forwarded it to you.
This attack is possible because most email clients allow CSS to be used to style HTML emails. When an email is forwarded, the position of the original email in the DOM usually changes, allowing for CSS rules to be selectively applied only when an email has been forwarded.
An attacker can use this to include elements in the email that appear or disappear depending on the context in which the email is viewed. Because they are usually invisible, only appear in certain circumstances, and can be used for all sorts of mischief, I’ll refer to these elements as kobold letters, after the elusive sprites of mythology.
This affects all types of email clients and webmailers that support HTML email. So pretty much all of them. For the moment, however, I’ll focus on selected clients to demonstrate the problem, and leave it to others (or future me) to extend the principle to other clients.
[…]
Exploiting this in Thunderbird is fairly straightforward. Thunderbird wraps emails in <div class="moz-text-html" lang="x-unicode"></div> and leaves them otherwise unchanged, making it a good example to demonstrate the principle. When forwarding an email, the quoted email will be enclosed in another <div></div>, moving it down one level in the DOM.
Taking this into account leads to the following proof of concept:
<!DOCTYPE html>
<html>
<head>
<style>
.kobold-letter {
display: none;
}
.moz-text-html>div>.kobold-letter {
display: block!important;
}
</style>
</head>
<body>
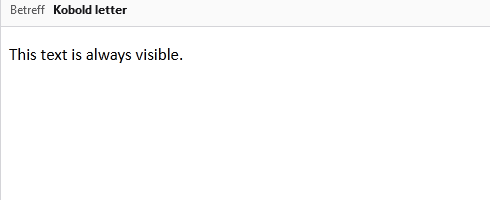
<p>This text is always visible.</p>
<pclass="kobold-letter">This text will only appear after forwarding.</p>
</body>
</html>
The email contains two paragraphs, one that has no styling and should always be visible, and one that is hidden with display: none;. This is how it looks when the email is displayed in Thunderbird:
This email may look harmless…
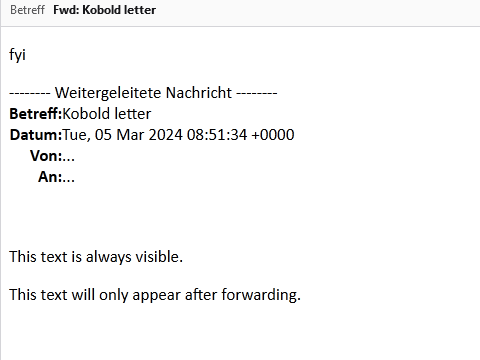
As expected, only the paragraph “This text is always visible.” is shown. However, when we forward the email, the second paragraph becomes suddenly visible. Albeit only to the new recipient – the original recipient who forwarded the email remains unaware.
…until it has been forwarded.
Because we know exactly where each element will be in the DOM relative to .moz-text-html, and because we control the CSS, we can easily hide and show any part of the email, changing the content completely. If we style the kobold letter as an overlay, we can not only affect the forwarded email, but also (for example) replace any comments your manager might have had on the original mail, opening up even more opportunities for phishing.
HP “sought to take advantage of customers’ sunk costs,” printer owners claimed this week in a class action lawsuit against the hardware giant.
Lawyers representing the aggrieved were responding [PDF] in an Illinois court to an earlier HP Inc motion to dismiss a January lawsuit. Among other things, the plaintiffs’ filing stated that the printer buyers “never entered into any contractual agreement to buy only HP-branded ink prior to receiving the firmware updates.” They allege HP broke several anti-competitive statutes, which they claim:
bar tying schemes, and certain uses of software to accomplish that without permission, that would monopolize an aftermarket for replacement ink cartridges, when these results are achieved in a way that “take[s] advantage of customers’ sunk costs.”
In the case, which began in January, the plaintiffs are arguing that HP issued a firmware update between late 2022 and early 2023 that they allege disabled their printers if they installed a replacement cartridge that was not HP-branded. They are asking for damages that include the cost of now-useless third-party cartridges and an injunction to disable the part of the firmware updates that prevent the use of third-party ink.
In a March filing [PDF], HP claimed it went “to great lengths” to let customers know its printers are intended to work only with cartridges with an HP “security chip.” While the plaintiffs say it uses software updates to block consumers from using cheaper rival cartridges in HP printers, the hardware giant characterizes this as “dynamic security” measures “to prevent the use of third-party printer cartridges that copy HP’s security chips (i.e. cloned or counterfeit cartridges).”
“HP does not block cartridges that reuse HP security chips, and there are many such options available for sale. Nor does HP conceal its use of dynamic security,” the company said.
It added that the printer owners can’t claim damages for being overcharged under federal antitrust laws because consumers who buy products from an intermediary can sue the manufacturer for injunctive relief under those laws, but they can’t sue the manufacturer to recover damages resulting from an alleged overcharge.
HP customers claim firmware update rendered third-party ink verboten
“None of the named plaintiffs allege that they purchased printer ink directly from HP after receiving a dynamic security firmware update,” HP said.
And why should they?
It also said Robinson and co. hadn’t “plausibly alleged” that HP “acted without authorization” or “exceeded authorized access” when the software tweaks came through.
HP CEO Enrique Lores has made no secret of the fact that it hopes to pull customers into a print subscription business model.
Lores said in an interview earlier this year that if a “customer doesn’t print enough or doesn’t use our supplies, it’s a bad investment.” However, in fairness, when it comes to ink cartridges, HP is far from alone in charging steep prices, with some estimates placing printer ink prices at $439-$2,380 per liter. Some printer makers make a loss on retailing the devices.
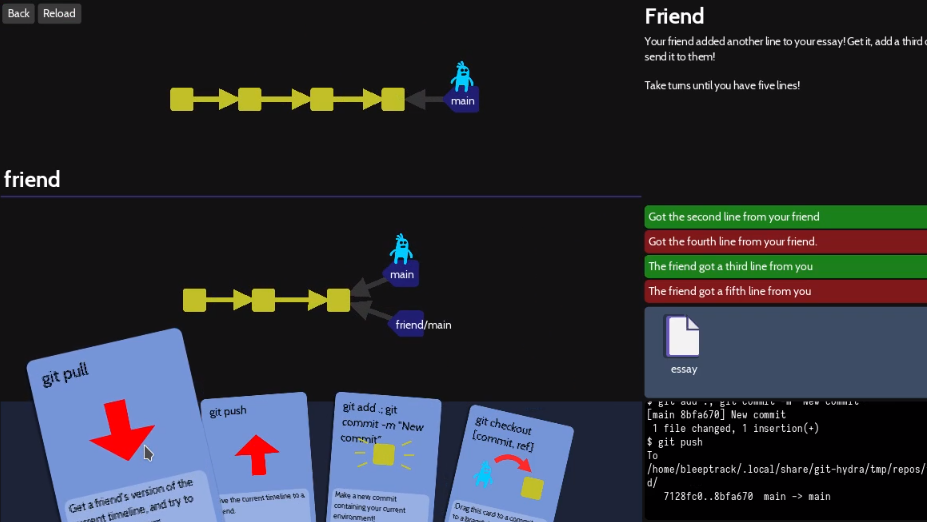
What better way to learn to use Git than a gamified interface that visualizes every change? That’s the idea behind Oh My Git! which aims to teach players all about the popular version control system that underpins so many modern software projects.
Git good, with a gameified git interface.
Sometimes the downside to a tool being so ubiquitous is that it tends to be taken for granted that everyone already knows how to use it, and those starting entirely from scratch can be left unsure where to begin. That’s what creators [bleeptrack] and [blinry] had in mind with Oh My Git! which is freely available for Linux, Windows, and macOS.
The idea is to use a fun playing-card interface to not only teach players the different features, but also to build intuitive familiarity for operations like merging and rebasing by visualizing in real-time the changes a player’s actions make.
The game is made with beginners in mind, with the first two (short) levels establishing that managing multiple versions of a file can quickly become unwieldy without help. Enter git — which the game explains is essentially a time machine — and it’s off to the races.
It might be aimed at beginners, but more advanced users can learn a helpful trick or two. The game isn’t some weird pseudo-git simulator, either. The back end uses real git repositories, with a real shell and git interface behind it all. Prefer to type commands in directly instead of using the playing card interface? Go right ahead!
Oh My Git! uses the free and open-source Godot game engine (not to be confused with the Godot machine, a chaos-based random number generator.)
Ubisoft’s online-only racing game The Crew stopped being operable on April 1. Some users are reporting, however, that things have gone a bit further. They say that the company actually reached into Ubisoft Connect accounts and revoked the license to access the game, according to reports by Game Rant and others.
Some of these users liken this move to theft, as they had purchased the game with their own money and received no warning that Ubisoft would be deleting the license. When attempting to launch the game, these players say they received a message stating that access was no longer possible.
On its face, this sounds pretty bad. People paid for something that was snatched away. However, there’s one major caveat. The Crew is an online-only racing game, so there really isn’t anything to do without the servers. Those servers went down on April 1 and the game was delisted from digital store fronts. Also, this move only impacts the original game. The Crew 2 and The Crew Motorfest are both still going.
When Ubisoft announced that the servers would be taken offline, it offered refunds to those who recently purchased the The Crew. The game’s been around a decade, so this refund likely didn’t apply to the vast majority of players. Some of these people said they had planned to set up private servers to play the game, an option that is now impossible.
[…]
We pay money for these products. We think we own them, but we don’t own a damned thing. Read the terms of service from Ubisoft or any other major games publisher for proof of that. Philippe Tremblay, Ubisoft’s director of subscriptions, recently told Gamesindustry.biz that players will become “comfortable with not owning” their games.
In this cross-sectional analysis of a nationally representative sample of 100 nonfederal acute care hospitals, 96.0% of hospital websites transmitted user information to third parties, whereas 71.0% of websites included a publicly accessible privacy policy. Of 71 privacy policies, 40 (56.3%) disclosed specific third-party companies receiving user information.
[…]
Of 100 hospital websites, 96 […] transferred user information to third parties. Privacy policies were found on 71 websites […] 70 […] addressed how collected information would be used, 66 […] addressed categories of third-party recipients of user information, and 40 […] named specific third-party companies or services receiving user information.
[…]
In this cross-sectional study of a nationally representative sample of 100 nonfederal acute care hospitals, we found that although 96.0% of hospital websites exposed users to third-party tracking, only 71.0% of websites had an available website privacy policy. Polices averaged more than 2500 words in length and were written at a college reading-level. Given estimates that more than one-half of adults in the US lack literacy proficiency and that the average patient in the US reads at a grade 8 level, the length and complexity of privacy policies likely pose substantial barriers to users’ ability to read and understand them.27,32
[…]
Only 56.3% of policies (and only 40 hospitals overall) identified specific third-party recipients. Named third-parties tended to be companies familiar to users, such as Google. This lack of detail regarding third-party data recipients may lead users to assume that they are being tracked only by a small number of companies that they know well, when, in fact, hospital websites included in this study transferred user data to a median of 9 domains.
[…]
In addition to presenting risks for users, inadequate privacy policies may pose risks for hospitals. Although hospitals are generally not required under federal law to have a website privacy policy that discloses their methods of collecting and transferring data from website visitors, hospitals that do publish website privacy policies may be subject to enforcement by regulatory authorities like the Federal Trade Commission (FTC).33 The FTC has taken the position that entities that publish privacy policies must ensure that these policies reflect their actual practices.34 For example, entities that promise they will delete personal information upon request but fail to do so in practice may be in violation of the FTC Act.34
Walled Culture has been warning about the financialisation and securitisation of music for two years now. Those obscure but important developments mean that the owners of copyrights are increasingly detached from the creative production process. They regard music as just another asset, like gold, petroleum or property, to be exploited to the maximum. A Guest Essay in the New York Times points out one of the many bad consequences of this trend:
Does that song on your phone or on the radio or in the movie theater sound familiar? Private equity — the industry responsible for bankrupting companies, slashing jobs and raising the mortality rates at the nursing homes it acquires — is making money by gobbling up the rights to old hits and pumping them back into our present. The result is a markedly blander music scene, as financiers cannibalize the past at the expense of the future and make it even harder for us to build those new artists whose contributions will enrich our entire culture.
As well as impoverishing our culture, the financialisation and securitisation of music is making life even harder for the musicians it depends on:
In the 1990s, as the musician and indie label founder Jenny Toomey wrote recently in Fast Company, a band could sell 10,000 copies of an album and bring in about $50,000 in revenue. To earn the same amount in 2024, the band’s whole album would need to rack up a million streams — roughly enough to put each song among Spotify’s top 1 percent of tracks. The music industry’s revenues recently hit a new high, with major labels raking in record earnings, while the streaming platforms’ models mean that the fractions of pennies that trickle through to artists are skewed toward megastars.
Part of the problem is the extremely low rates paid by streaming services. But the larger issue is the power imbalance within all the industries based on copyright. The people who actually create books, music, films and the rest are forced to accept bad deals with the distribution companies. Walled Culture the book (free ebook versions) details the painfully low income the vast majority of artists derive from their creativity, and how most are forced to take side jobs to survive. This daily struggle is so widespread that it is no longer remarked upon. It is one of the copyright world’s greatest successes that the public and many creators now regard this state of affairs as a sad but unavoidable fact of life. It isn’t.
The New York Times opinion piece points out that there are signs private equity is already moving on to its next market/victim, having made its killing in the music industry. But one thing is for sure. New ways of financing today’s exploited artists are needed, and not ones cooked up by Wall Street. Until musicians and creators in general take back control of their works, rather than acquiescing in the hugely unfair deal that is copyright, it will always be someone else who makes most of the money from their unique gifts.
Of course, the whole model of continously making money from a single creating is a bit fucked up. If a businessman were to ask for money every time someone read their email that would be plain stupid. How is this any different?
[…] We’re told mitigations put in place at the software and silicon level by the x86 giant to thwart Spectre-style exploitation of its processors’ speculative execution can be bypassed, allowing malware or rogue users on a vulnerable machine to steal sensitive information – such as passwords and keys – out of kernel memory and other areas of RAM that should be off limits.
The boffins say they have developed a tool called InSpectre Gadget that can find snippets of code, known as gadgets, within an operating system kernel that on vulnerable hardware can be abused to obtain secret data, even on chips that have Spectre protections baked in.
[…]
“We show that our tool can not only uncover new (unconventionally) exploitable gadgets in the Linux kernel, but that those gadgets are sufficient to bypass all deployed Intel mitigations,” the VU Amsterdam team said this week. “As a demonstration, we present the first native Spectre-v2 exploit against the Linux kernel on last-generation Intel CPUs, based on the recent BHI variant and able to leak arbitrary kernel memory at 3.5 kB/sec.”
A quick video demonstrating that Native BHI-based attack to grab the /etc/shadow file of usernames and hashed passwords out of RAM on a 13th-gen Intel Core processor is below. We’re told the technique, tagged CVE-2024-2201, will work on any Intel CPU core.
The VU Amsterdam team — Sander Wiebing, Alvise de Faveri Tron, Herbert Bos and Cristiano Giuffrida — have now open sourced InSpectre Gadget, an angr-based analyzer, plus a database of gadgets found for Linux Kernel 6.6-rc4 on GitHub.
“Our efforts led to the discovery of 1,511 Spectre gadgets and 2,105 so-called ‘dispatch gadgets,'” the academics added. “The latter are very useful for an attacker, as they can be used to chain gadgets and direct speculation towards a Spectre gadget.”
[…]
AMD and Arm cores are not vulnerable to Native BHI, according to the VU Amsterdam team. AMD has since confirmed this in an advisory
[…]
After the aforementioned steps were taken to shut down BHI-style attacks, “this mitigation left us with a dangling question: ‘Is finding ‘native’ Spectre gadgets for BHI, ie, not implanted through eBPF, feasible?'” the academics asked.
The short answer is yes. A technical paper [PDF] describing Native BHI is due to be presented at the USENIX Security Symposium.
A handful of bugs in LG smart TVs running WebOS could allow an attacker to bypass authorization and gain root access on the device.
Once they have gained root, your TV essentially belongs to the intruder who can use that access to do all sorts of nefarious things including moving laterally through your home network, dropping malware, using the device as part of a botnet, spying on you — or at the very least severely screwing up your streaming service algorithms.
Bitdefender Labs researcher Alexandru Lazăr spotted the four vulnerabilities that affect WebOS versions 4 through 7. In an analysis published today, the security firm noted that while the vulnerable service is only intended for LAN access, more than 91,000 devices are exposed to the internet, according to a Shodan scan.
Here’s a look at the four flaws:
CVE-2023-6317: a PIN/prompt bypass that allows an attacker to set a variable and add a new user account to the TV without requiring a security PIN. It has a CVSS rating of 7.2.
CVE-2023-6318: a critical command injection flaw with a 9.1 CVSS rating that allows an attacker to elevate an initial access to root-level privileges and take over the TV.
CVE-2023-6319: another 9.1-rated command injection vulnerability that can be triggered by manipulating the music-lyrics library.
CVE-2023-6320: a critical command injection vulnerability that can be triggered by manipulating an API endpoint to allow execution of commands on the device as dbus, which has similar permissions as root. It also received a 9.1 CVSS score.
In order to abuse any of the command injection flaws, however, the attacker must first exploit CVE-2023-6317. This issue is down to WebOS running a service on ports 3000/3001 that allows users to control their TV on their smartphone using a PIN. But, there’s a bug in the account handler function that sometimes allows skipping the PIN verification:
The function that handles account registration requests uses a variable called skipPrompt which is set to true when either the client-key or the companion-client-key parameters correspond to an existing profile. It also takes into consideration what permissions are requested when deciding whether to prompt the user for a PIN, as confirmation is not required in some cases.
After creating an account with no permissions, an attacker can then request a new account with elevated privileges “but we specify the companion-client-key variable to match the key we got when we created the first account,” the team reports.
The server confirms that the key exists, but doesn’t verify which account it belongs to, we’re told. “Thus, the skipPrompt variable will be true and the account will be created without requesting a PIN confirmation on the TV,” the team reports
And then, after creating this account with elevated privileges, an attacker can use that access to exploit the other three flaws that lead to root access or command execution as the dbus user.
Lazăr responsibly reported the flaws to LG on November 1, 2023, and LG asked for a time extension to fix them. The electronics giant issued patches on March 22. It’s a good idea to check your TV for software updates and apply the WebOS patch now.
The Mass Damage & Consumer Foundation today announced that it has initiated a class action lawsuit against Google over its Android operating system. The reason is a new study that shows how Dutch Android smartphones systematically transfer large amounts of information about device use to Google. Even with the most privacy-friendly options enabled, user data cannot be prevented from ending up on Google’s servers. According to the foundation, this is not clear to Android users, let alone whether they have given permission for this.
For the research, a team of scientists purchased several Android phones between 2022 and 2024 and captured, decrypted and analyzed the outgoing traffic on a Dutch server. This shows that a bundle of processes called ‘Google Play Services’ runs silently in the background and cannot be disabled or deleted. These processes continuously record what happens on and around the phone. For example, Google shares which apps someone uses, products they order and even whether users are sleeping.
More than nine million Dutch people
The Mass Damage & Consumer Foundation states that Google’s conduct violates a large number of Dutch and European rules that must protect consumers. The foundation wants to use a lawsuit to force Google to implement fundamental (privacy) changes to the Android platform and to offer an opt-out option for every form of data it collects, not just a few.
[…]
Identity can be easily traced
The research paid specific attention to the use of unique identifiers (UIDs). These are characteristics that Google can link to the collected data, such as an e-mail address or Android ID, a unique serial number with which someone is known to Google. The use of these features is sensitive. For example, Google advises against the use of unique features in its own guidelines for app developers: users could unintentionally be tracked across multiple apps. However, one or more of these unique features were found in the data transmissions examined – without exception. The researchers point out that this makes it easy to trace someone’s identity to virtually everything that happens on and around an Android device.
People who develop long covid after being hospitalised with severe covid-19 have raised levels of many inflammatory immune molecules compared with those who recovered fully after such a hospitalisation, according to a study of nearly 700 people.
The findings show that long covid has a real biological basis, says team member Peter Openshaw at Imperial College London. “People are not imagining it,” he says. “It’s genuinely happening to them.”
[…]
The study by Liewand her colleagues involved measuring the levels of 368 immune molecules in the blood of 659 people who were hospitalised with covid-19, mostly early on in the pandemic. The 426 people who were still reporting symptoms more than three months later were compared with the 233 who reported being fully recovered.
The study found that the patterns of immune activation reflected the main kinds of symptoms people with long covid reported. The five main symptom types were fatigue; cognitive impairment; anxiety and depression; cardiorespiratory symptoms; and gastrointestinal symptoms.
For instance, people with gastrointestinal symptoms had higher blood levels of SCG3, a signalling protein that is also elevated in the faeces of people with irritable bowel syndrome.
The findings won’t help with diagnosing whether people have long covid or not, says team member Chris Brightling at the University of Leicester in the UK. But once the condition has been diagnosed, testing for these molecules could help reveal what kind of long covid people have, and thus what kind of interventions might help, he says.